 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiRANews: Dataset and Benchmarks for Multi-Resource-Assisted News Summarization
Paper and Code

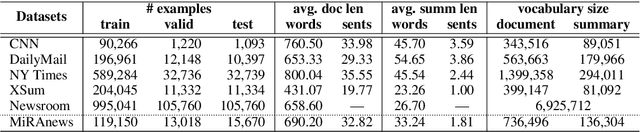
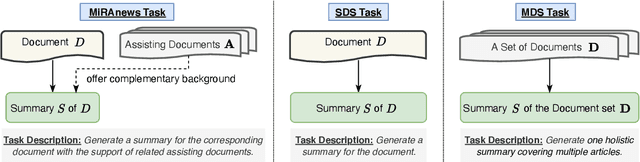

One of the most challenging aspects of current single-document news summarization is that the summary often contains 'extrinsic hallucinations', i.e., facts that are not present in the source document, which are often derived via world knowledge. This causes summarization systems to act more like open-ended language models tending to hallucinate facts that are erroneous. In this paper, we mitigate this problem with the help of multiple supplementary resource documents assisting the task. We present a new dataset MiRANews and benchmark existing summarization models. In contrast to multi-document summarization, which addresses multiple events from several source documents, we still aim at generating a summary for a single document. We show via data analysis that it's not only the models which are to blame: more than 27% of facts mentioned in the gold summaries of MiRANews are better grounded on assisting documents than in the main source articles. An error analysis of generated summaries from pretrained models fine-tuned on MiRANews reveals that this has an even bigger effects on models: assisted summarization reduces 55% of hallucinations when compared to single-document summarization models trained on the main article only. Our code and data are available at https://github.com/XinnuoXu/MiRANews.