 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Function Demonstrations Improve Generation in Low-Resource Programming Languages
Mar 24, 2025
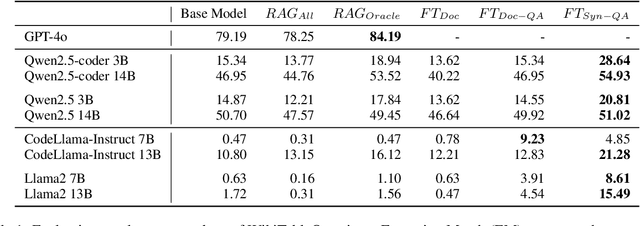
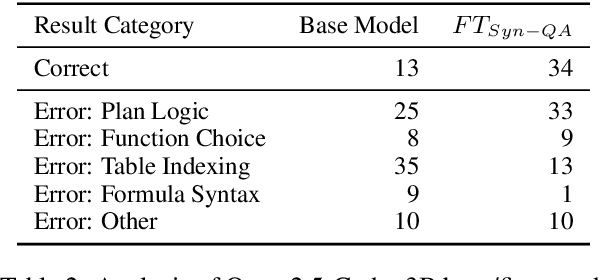

A key consideration when training an LLM is whether the target language is more or less resourced, whether this is English compared to Welsh, or Python compared to Excel. Typical training data for programming languages consist of real program demonstrations coupled with human-written comments. Here we present novel approaches to the creation of such data for low resource programming languages. We generate fully-synthetic, textbook-quality demonstrations of common library functions in an example domain of Excel formulas, using a teacher model. We then finetune an underperforming student model, and show improvement on 2 question-answering datasets recast into the Excel domain. We show advantages of finetuning over standard, off-the-shelf RAG approaches, which can offer only modest improvement due to the unfamiliar target domain.
Dynamic Prompt Middleware: Contextual Prompt Refinement Controls for Comprehension Tasks
Dec 03, 2024

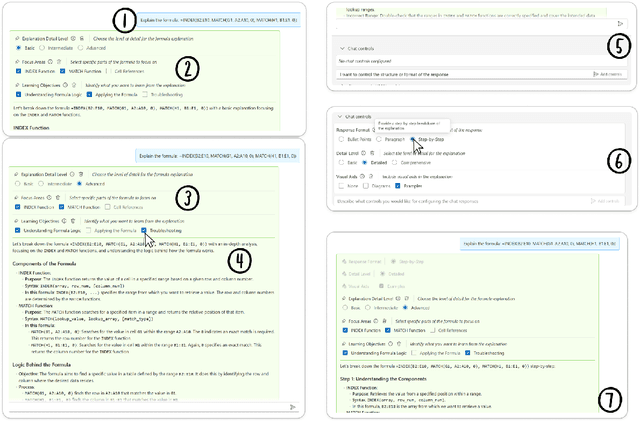

Effective prompting of generative AI is challenging for many users, particularly in expressing context for comprehension tasks such as explaining spreadsheet formulas, Python code, and text passages. Prompt middleware aims to address this barrier by assisting in prompt construction, but barriers remain for users in expressing adequate control so that they can receive AI-responses that match their preferences. We conduct a formative survey (n=38) investigating user needs for control over AI-generated explanations in comprehension tasks, which uncovers a trade-off between standardized but predictable support for prompting, and adaptive but unpredictable support tailored to the user and task. To explore this trade-off, we implement two prompt middleware approaches: Dynamic Prompt Refinement Control (Dynamic PRC) and Static Prompt Refinement Control (Static PRC). The Dynamic PRC approach generates context-specific UI elements that provide prompt refinements based on the user's prompt and user needs from the AI, while the Static PRC approach offers a preset list of generally applicable refinements. We evaluate these two approaches with a controlled user study (n=16) to assess the impact of these approaches on user control of AI responses for crafting better explanations. Results show a preference for the Dynamic PRC approach as it afforded more control, lowered barriers to providing context, and encouraged exploration and reflection of the tasks, but that reasoning about the effects of different generated controls on the final output remains challenging. Drawing on participant feedback, we discuss design implications for future Dynamic PRC systems that enhance user control of AI responses. Our findings suggest that dynamic prompt middleware can improve the user experience of generative AI workflows by affording greater control and guide users to a better AI response.
Improving Steering and Verification in AI-Assisted Data Analysis with Interactive Task Decomposition
Jul 02, 2024



LLM-powered tools like ChatGPT Data Analysis, have the potential to help users tackle the challenging task of data analysis programming, which requires expertise in data processing, programming, and statistics. However, our formative study (n=15) uncovered serious challenges in verifying AI-generated results and steering the AI (i.e., guiding the AI system to produce the desired output). We developed two contrasting approaches to address these challenges. The first (Stepwise) decomposes the problem into step-by-step subgoals with pairs of editable assumptions and code until task completion, while the second (Phasewise) decomposes the entire problem into three editable, logical phases: structured input/output assumptions, execution plan, and code. A controlled, within-subjects experiment (n=18) compared these systems against a conversational baseline. Users reported significantly greater control with the Stepwise and Phasewise systems, and found intervention, correction, and verification easier, compared to the baseline. The results suggest design guidelines and trade-offs for AI-assisted data analysis tools.
Solving Data-centric Tasks using Large Language Models
Feb 18, 2024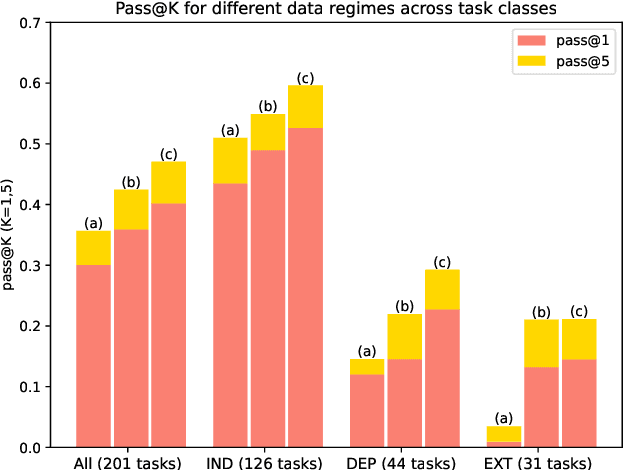
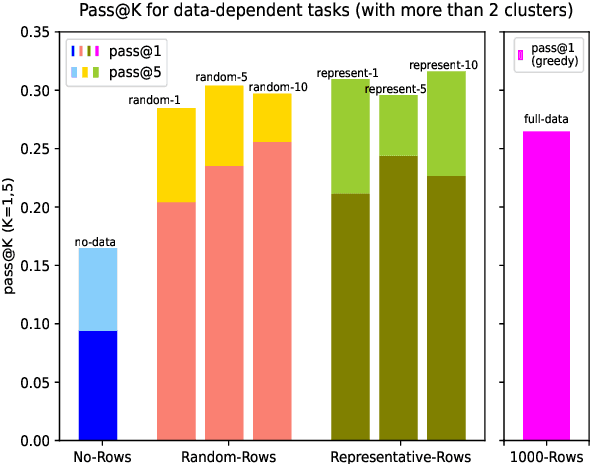
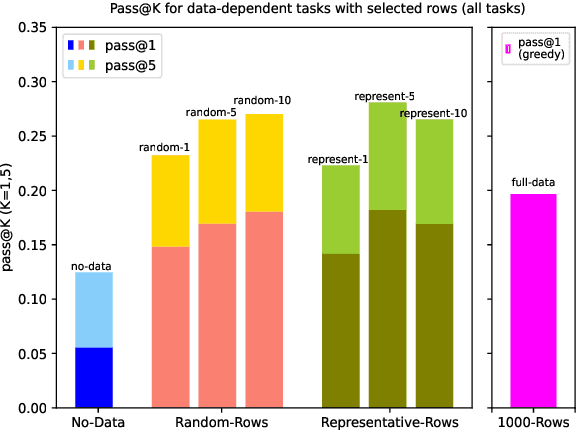
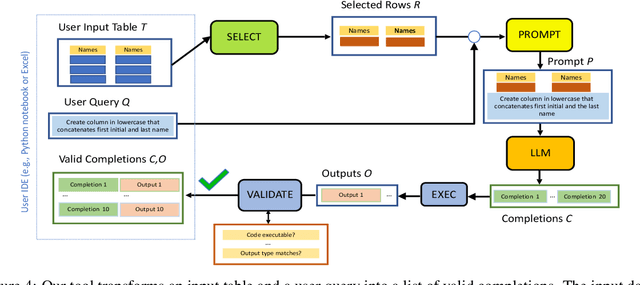
Large language models (LLMs) are rapidly replacing help forums like StackOverflow, and are especially helpful for non-professional programmers and end users. These users are often interested in data-centric tasks, such as spreadsheet manipulation and data wrangling, which are hard to solve if the intent is only communicated using a natural-language description, without including the data. But how do we decide how much data and which data to include in the prompt? This paper makes two contributions towards answering this question. First, we create a dataset of real-world NL-to-code tasks manipulating tabular data, mined from StackOverflow posts. Second, we introduce a cluster-then-select prompting technique, which adds the most representative rows from the input data to the LLM prompt. Our experiments show that LLM performance is indeed sensitive to the amount of data passed in the prompt, and that for tasks with a lot of syntactic variation in the input table, our cluster-then-select technique outperforms a random selection baseline.
Co-audit: tools to help humans double-check AI-generated content
Oct 02, 2023Users are increasingly being warned to check AI-generated content for correctness. Still, as LLMs (and other generative models) generate more complex output, such as summaries, tables, or code, it becomes harder for the user to audit or evaluate the output for quality or correctness. Hence, we are seeing the emergence of tool-assisted experiences to help the user double-check a piece of AI-generated content. We refer to these as co-audit tools. Co-audit tools complement prompt engineering techniques: one helps the user construct the input prompt, while the other helps them check the output response. As a specific example, this paper describes recent research on co-audit tools for spreadsheet computations powered by generative models. We explain why co-audit experiences are essential for any application of generative AI where quality is important and errors are consequential (as is common in spreadsheet computations). We propose a preliminary list of principles for co-audit, and outline research challenges.
Rows from Many Sources: Enriching row completions from Wikidata with a pre-trained Language Model
Apr 14, 2022

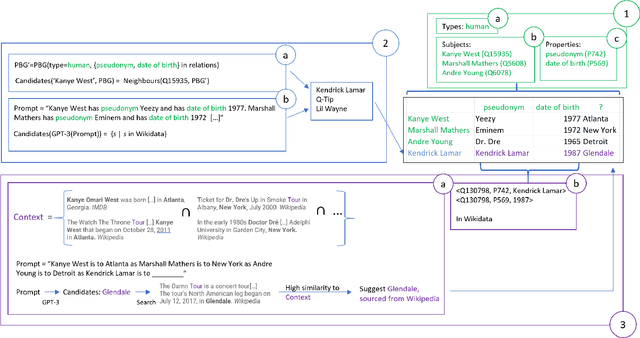
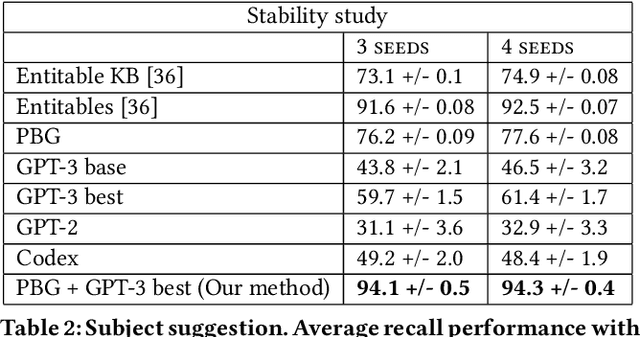
Row completion is the task of augmenting a given table of text and numbers with additional, relevant rows. The task divides into two steps: subject suggestion, the task of populating the main column; and gap filling, the task of populating the remaining columns. We present state-of-the-art results for subject suggestion and gap filling measured on a standard benchmark (WikiTables). Our idea is to solve this task by harmoniously combining knowledge base table interpretation and free text generation. We interpret the table using the knowledge base to suggest new rows and generate metadata like headers through property linking. To improve candidate diversity, we synthesize additional rows using free text generation via GPT-3, and crucially, we exploit the metadata we interpret to produce better prompts for text generation. Finally, we verify that the additional synthesized content can be linked to the knowledge base or a trusted web source such as Wikipedia.