 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAIRA-Seg: Enhancing Radiology Report Generation with Segmentation-Aware Multimodal Large Language Models
Nov 18, 2024



There is growing interest in applying AI to radiology report generation, particularly for chest X-rays (CXRs). This paper investigates whether incorporating pixel-level information through segmentation masks can improve fine-grained image interpretation of multimodal large language models (MLLMs) for radiology report generation. We introduce MAIRA-Seg, a segmentation-aware MLLM framework designed to utilize semantic segmentation masks alongside CXRs for generating radiology reports. We train expert segmentation models to obtain mask pseudolabels for radiology-specific structures in CXRs. Subsequently, building on the architectures of MAIRA, a CXR-specialised model for report generation, we integrate a trainable segmentation tokens extractor that leverages these mask pseudolabels, and employ mask-aware prompting to generate draft radiology reports. Our experiments on the publicly available MIMIC-CXR dataset show that MAIRA-Seg outperforms non-segmentation baselines. We also investigate set-of-marks prompting with MAIRA and find that MAIRA-Seg consistently demonstrates comparable or superior performance. The results confirm that using segmentation masks enhances the nuanced reasoning of MLLMs, potentially contributing to better clinical outcomes.
Challenges for Responsible AI Design and Workflow Integration in Healthcare: A Case Study of Automatic Feeding Tube Qualification in Radiology
May 08, 2024
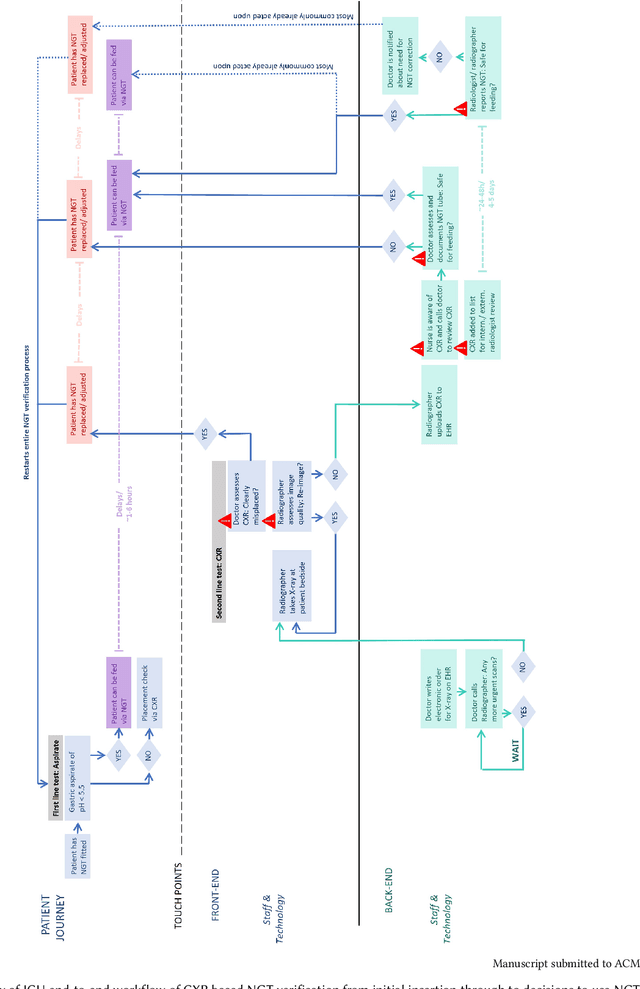


Nasogastric tubes (NGTs) are feeding tubes that are inserted through the nose into the stomach to deliver nutrition or medication. If not placed correctly, they can cause serious harm, even death to patients. Recent AI developments demonstrate the feasibility of robustly detecting NGT placement from Chest X-ray images to reduce risks of sub-optimally or critically placed NGTs being missed or delayed in their detection, but gaps remain in clinical practice integration. In this study, we present a human-centered approach to the problem and describe insights derived following contextual inquiry and in-depth interviews with 15 clinical stakeholders. The interviews helped understand challenges in existing workflows, and how best to align technical capabilities with user needs and expectations. We discovered the trade-offs and complexities that need consideration when choosing suitable workflow stages, target users, and design configurations for different AI proposals. We explored how to balance AI benefits and risks for healthcare staff and patients within broader organizational and medical-legal constraints. We also identified data issues related to edge cases and data biases that affect model training and evaluation; how data documentation practices influence data preparation and labelling; and how to measure relevant AI outcomes reliably in future evaluations. We discuss how our work informs design and development of AI applications that are clinically useful, ethical, and acceptable in real-world healthcare services.
RadEdit: stress-testing biomedical vision models via diffusion image editing
Dec 21, 2023Biomedical imaging datasets are often small and biased, meaning that real-world performance of predictive models can be substantially lower than expected from internal testing. This work proposes using generative image editing to simulate dataset shifts and diagnose failure modes of biomedical vision models; this can be used in advance of deployment to assess readiness, potentially reducing cost and patient harm. Existing editing methods can produce undesirable changes, with spurious correlations learned due to the co-occurrence of disease and treatment interventions, limiting practical applicability. To address this, we train a text-to-image diffusion model on multiple chest X-ray datasets and introduce a new editing method RadEdit that uses multiple masks, if present, to constrain changes and ensure consistency in the edited images. We consider three types of dataset shifts: acquisition shift, manifestation shift, and population shift, and demonstrate that our approach can diagnose failures and quantify model robustness without additional data collection, complementing more qualitative tools for explainable AI.
Co-audit: tools to help humans double-check AI-generated content
Oct 02, 2023Users are increasingly being warned to check AI-generated content for correctness. Still, as LLMs (and other generative models) generate more complex output, such as summaries, tables, or code, it becomes harder for the user to audit or evaluate the output for quality or correctness. Hence, we are seeing the emergence of tool-assisted experiences to help the user double-check a piece of AI-generated content. We refer to these as co-audit tools. Co-audit tools complement prompt engineering techniques: one helps the user construct the input prompt, while the other helps them check the output response. As a specific example, this paper describes recent research on co-audit tools for spreadsheet computations powered by generative models. We explain why co-audit experiences are essential for any application of generative AI where quality is important and errors are consequential (as is common in spreadsheet computations). We propose a preliminary list of principles for co-audit, and outline research challenges.