 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Steering and Verification in AI-Assisted Data Analysis with Interactive Task Decomposition
Jul 02, 2024



LLM-powered tools like ChatGPT Data Analysis, have the potential to help users tackle the challenging task of data analysis programming, which requires expertise in data processing, programming, and statistics. However, our formative study (n=15) uncovered serious challenges in verifying AI-generated results and steering the AI (i.e., guiding the AI system to produce the desired output). We developed two contrasting approaches to address these challenges. The first (Stepwise) decomposes the problem into step-by-step subgoals with pairs of editable assumptions and code until task completion, while the second (Phasewise) decomposes the entire problem into three editable, logical phases: structured input/output assumptions, execution plan, and code. A controlled, within-subjects experiment (n=18) compared these systems against a conversational baseline. Users reported significantly greater control with the Stepwise and Phasewise systems, and found intervention, correction, and verification easier, compared to the baseline. The results suggest design guidelines and trade-offs for AI-assisted data analysis tools.
FormaT5: Abstention and Examples for Conditional Table Formatting with Natural Language
Nov 01, 2023
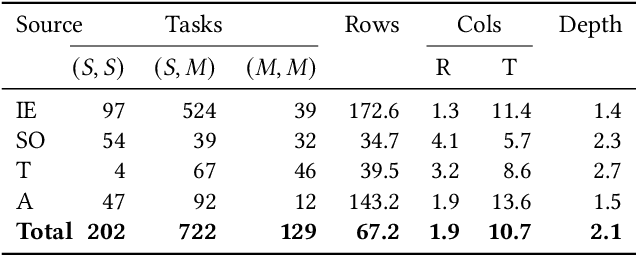

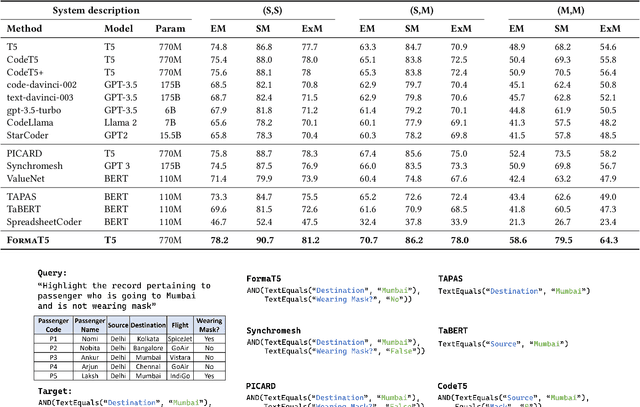
Formatting is an important property in tables for visualization, presentation, and analysis. Spreadsheet software allows users to automatically format their tables by writing data-dependent conditional formatting (CF) rules. Writing such rules is often challenging for users as it requires them to understand and implement the underlying logic. We present FormaT5, a transformer-based model that can generate a CF rule given the target table and a natural language description of the desired formatting logic. We find that user descriptions for these tasks are often under-specified or ambiguous, making it harder for code generation systems to accurately learn the desired rule in a single step. To tackle this problem of under-specification and minimise argument errors, FormaT5 learns to predict placeholders though an abstention objective. These placeholders can then be filled by a second model or, when examples of rows that should be formatted are available, by a programming-by-example system. To evaluate FormaT5 on diverse and real scenarios, we create an extensive benchmark of 1053 CF tasks, containing real-world descriptions collected from four different sources. We release our benchmarks to encourage research in this area. Abstention and filling allow FormaT5 to outperform 8 different neural approaches on our benchmarks, both with and without examples. Our results illustrate the value of building domain-specific learning systems.
CodeFusion: A Pre-trained Diffusion Model for Code Generation
Nov 01, 2023

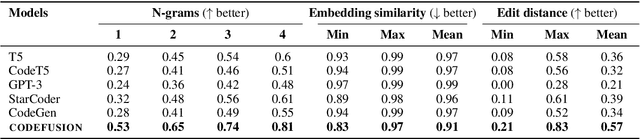

Imagine a developer who can only change their last line of code, how often would they have to start writing a function from scratch before it is correct? Auto-regressive models for code generation from natural language have a similar limitation: they do not easily allow reconsidering earlier tokens generated. We introduce CodeFusion, a pre-trained diffusion code generation model that addresses this limitation by iteratively denoising a complete program conditioned on the encoded natural language. We evaluate CodeFusion on the task of natural language to code generation for Bash, Python, and Microsoft Excel conditional formatting (CF) rules. Experiments show that CodeFusion (75M parameters) performs on par with state-of-the-art auto-regressive systems (350M-175B parameters) in top-1 accuracy and outperforms them in top-3 and top-5 accuracy due to its better balance in diversity versus quality.
InstructExcel: A Benchmark for Natural Language Instruction in Excel
Oct 23, 2023With the evolution of Large Language Models (LLMs) we can solve increasingly more complex NLP tasks across various domains, including spreadsheets. This work investigates whether LLMs can generate code (Excel OfficeScripts, a TypeScript API for executing many tasks in Excel) that solves Excel specific tasks provided via natural language user instructions. To do so we introduce a new large-scale benchmark, InstructExcel, created by leveraging the 'Automate' feature in Excel to automatically generate OfficeScripts from users' actions. Our benchmark includes over 10k samples covering 170+ Excel operations across 2,000 publicly available Excel spreadsheets. Experiments across various zero-shot and few-shot settings show that InstructExcel is a hard benchmark for state of the art models like GPT-4. We observe that (1) using GPT-4 over GPT-3.5, (2) providing more in-context examples, and (3) dynamic prompting can help improve performance on this benchmark.
Co-audit: tools to help humans double-check AI-generated content
Oct 02, 2023Users are increasingly being warned to check AI-generated content for correctness. Still, as LLMs (and other generative models) generate more complex output, such as summaries, tables, or code, it becomes harder for the user to audit or evaluate the output for quality or correctness. Hence, we are seeing the emergence of tool-assisted experiences to help the user double-check a piece of AI-generated content. We refer to these as co-audit tools. Co-audit tools complement prompt engineering techniques: one helps the user construct the input prompt, while the other helps them check the output response. As a specific example, this paper describes recent research on co-audit tools for spreadsheet computations powered by generative models. We explain why co-audit experiences are essential for any application of generative AI where quality is important and errors are consequential (as is common in spreadsheet computations). We propose a preliminary list of principles for co-audit, and outline research challenges.
DataVinci: Learning Syntactic and Semantic String Repairs
Aug 21, 2023



String data is common in real-world datasets: 67.6% of values in a sample of 1.8 million real Excel spreadsheets from the web were represented as text. Systems that successfully clean such string data can have a significant impact on real users. While prior work has explored errors in string data, proposed approaches have often been limited to error detection or require that the user provide annotations, examples, or constraints to fix the errors. Furthermore, these systems have focused independently on syntactic errors or semantic errors in strings, but ignore that strings often contain both syntactic and semantic substrings. We introduce DataVinci, a fully unsupervised string data error detection and repair system. DataVinci learns regular-expression-based patterns that cover a majority of values in a column and reports values that do not satisfy such patterns as data errors. DataVinci can automatically derive edits to the data error based on the majority patterns and constraints learned over other columns without the need for further user interaction. To handle strings with both syntactic and semantic substrings, DataVinci uses an LLM to abstract (and re-concretize) portions of strings that are semantic prior to learning majority patterns and deriving edits. Because not all data can result in majority patterns, DataVinci leverages execution information from an existing program (which reads the target data) to identify and correct data repairs that would not otherwise be identified. DataVinci outperforms 7 baselines on both error detection and repair when evaluated on 4 existing and new benchmarks.
Demonstration of CORNET: A System For Learning Spreadsheet Formatting Rules By Example
Aug 14, 2023

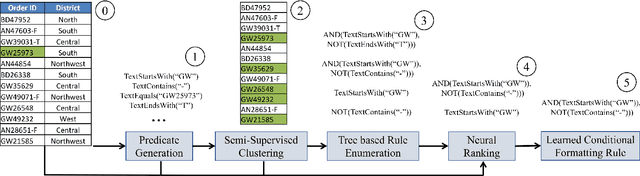

Data management and analysis tasks are often carried out using spreadsheet software. A popular feature in most spreadsheet platforms is the ability to define data-dependent formatting rules. These rules can express actions such as "color red all entries in a column that are negative" or "bold all rows not containing error or failure." Unfortunately, users who want to exercise this functionality need to manually write these conditional formatting (CF) rules. We introduce CORNET, a system that automatically learns such conditional formatting rules from user examples. CORNET takes inspiration from inductive program synthesis and combines symbolic rule enumeration, based on semi-supervised clustering and iterative decision tree learning, with a neural ranker to produce accurate conditional formatting rules. In this demonstration, we show CORNET in action as a simple add-in to Microsoft Excel. After the user provides one or two formatted cells as examples, CORNET generates formatting rule suggestions for the user to apply to the spreadsheet.
CORNET: A neurosymbolic approach to learning conditional table formatting rules by example
Aug 22, 2022
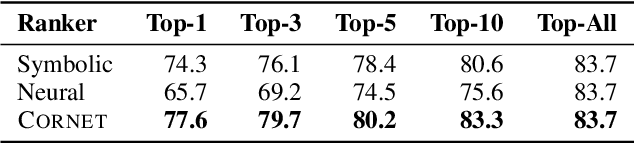
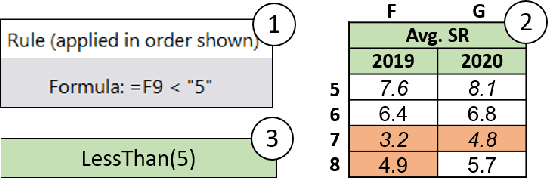

Spreadsheets are widely used for table manipulation and presentation. Stylistic formatting of these tables is an important property for both presentation and analysis. As a result, popular spreadsheet software, such as Excel, supports automatically formatting tables based on data-dependent rules. Unfortunately, writing these formatting rules can be challenging for users as that requires knowledge of the underlying rule language and data logic. In this paper, we present CORNET, a neuro-symbolic system that tackles the novel problem of automatically learning such formatting rules from user examples of formatted cells. CORNET takes inspiration from inductive program synthesis and combines symbolic rule enumeration, based on semi-supervised clustering and iterative decision tree learning, with a neural ranker to produce conditional formatting rules. To motivate and evaluate our approach, we extracted tables with formatting rules from a corpus of over 40K real spreadsheets. Using this data, we compared CORNET to a wide range of symbolic and neural baselines. Our results show that CORNET can learn rules more accurately, across varying conditions, compared to these baselines.
What is it like to program with artificial intelligence?
Aug 12, 2022
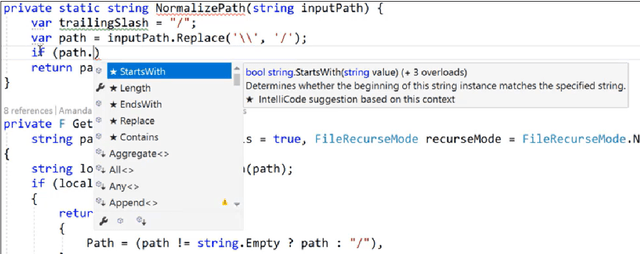
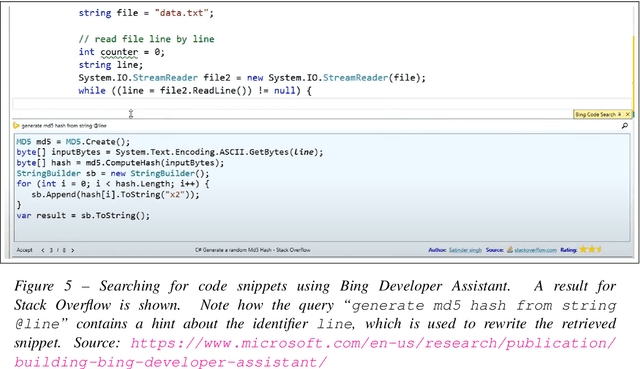
Large language models, such as OpenAI's codex and Deepmind's AlphaCode, can generate code to solve a variety of problems expressed in natural language. This technology has already been commercialised in at least one widely-used programming editor extension: GitHub Copilot. In this paper, we explore how programming with large language models (LLM-assisted programming) is similar to, and differs from, prior conceptualisations of programmer assistance. We draw upon publicly available experience reports of LLM-assisted programming, as well as prior usability and design studies. We find that while LLM-assisted programming shares some properties of compilation, pair programming, and programming via search and reuse, there are fundamental differences both in the technical possibilities as well as the practical experience. Thus, LLM-assisted programming ought to be viewed as a new way of programming with its own distinct properties and challenges. Finally, we draw upon observations from a user study in which non-expert end user programmers use LLM-assisted tools for solving data tasks in spreadsheets. We discuss the issues that might arise, and open research challenges, in applying large language models to end-user programming, particularly with users who have little or no programming expertise.
Rows from Many Sources: Enriching row completions from Wikidata with a pre-trained Language Model
Apr 14, 2022

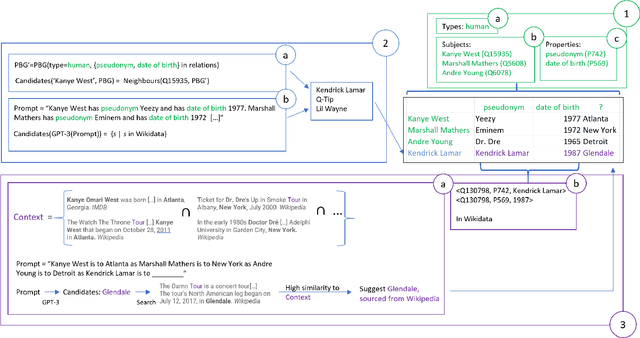
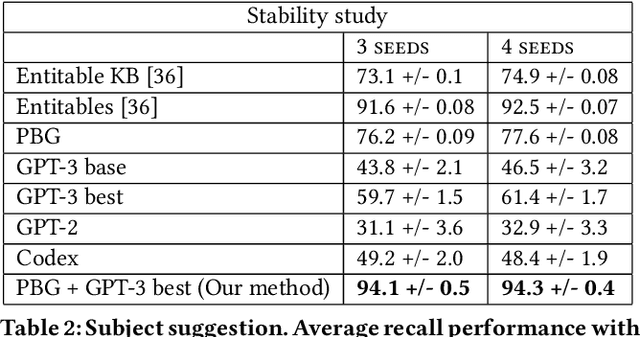
Row completion is the task of augmenting a given table of text and numbers with additional, relevant rows. The task divides into two steps: subject suggestion, the task of populating the main column; and gap filling, the task of populating the remaining columns. We present state-of-the-art results for subject suggestion and gap filling measured on a standard benchmark (WikiTables). Our idea is to solve this task by harmoniously combining knowledge base table interpretation and free text generation. We interpret the table using the knowledge base to suggest new rows and generate metadata like headers through property linking. To improve candidate diversity, we synthesize additional rows using free text generation via GPT-3, and crucially, we exploit the metadata we interpret to produce better prompts for text generation. Finally, we verify that the additional synthesized content can be linked to the knowledge base or a trusted web source such as Wikipedia.