 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Cogeneration of Bug Reproduction Test in Agentic Program Repair
Jan 27, 2026Bug Reproduction Tests (BRTs) have been used in many agentic Automated Program Repair (APR) systems, primarily for validating promising fixes and aiding fix generation. In practice, when developers submit a patch, they often implement the BRT alongside the fix. Our experience deploying agentic APR reveals that developers similarly desire a BRT within AI-generated patches to increase their confidence. However, canonical APR systems tend to generate BRTs and fixes separately, or focus on producing only the fix in the final patch. In this paper, we study agentic APR in the context of cogeneration, where the APR agent is instructed to generate both a fix and a BRT in the same patch. We evaluate the effectiveness of different cogeneration strategies on 120 human-reported bugs at Google and characterize different cogeneration strategies by their influence on APR agent behavior. We develop and evaluate patch selectors that account for test change information to select patches with plausible fixes (and plausible BRTs). Finally, we analyze the root causes of failed cogeneration trajectories. Importantly, we show that cogeneration allows the APR agent to generate BRTs for at least as many bugs as a dedicated BRT agent, without compromising the generation rate of plausible fixes, thereby reducing engineering effort in maintaining and coordinating separate generation pipelines for fix and BRT at scale.
Towards Verified Code Reasoning by LLMs
Sep 30, 2025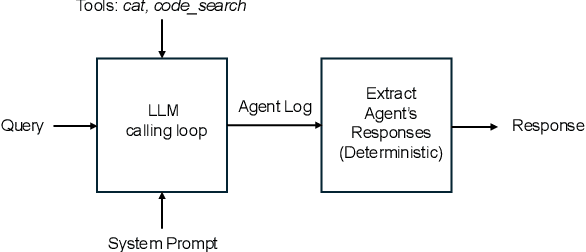

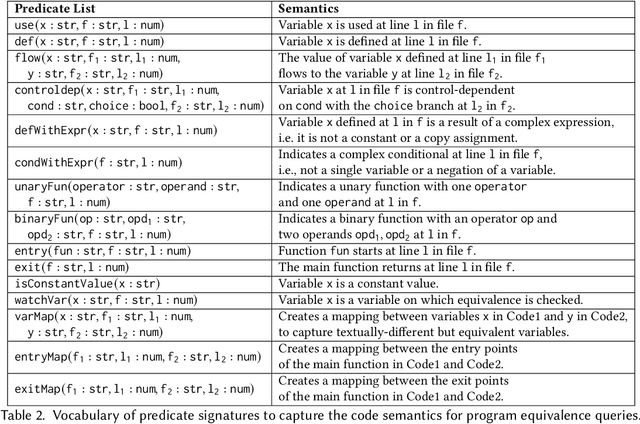
While LLM-based agents are able to tackle a wide variety of code reasoning questions, the answers are not always correct. This prevents the agent from being useful in situations where high precision is desired: (1) helping a software engineer understand a new code base, (2) helping a software engineer during code review sessions, and (3) ensuring that the code generated by an automated code generation system meets certain requirements (e.g. fixes a bug, improves readability, implements a feature). As a result of this lack of trustworthiness, the agent's answers need to be manually verified before they can be trusted. Manually confirming responses from a code reasoning agent requires human effort and can result in slower developer productivity, which weakens the assistance benefits of the agent. In this paper, we describe a method to automatically validate the answers provided by a code reasoning agent by verifying its reasoning steps. At a very high level, the method consists of extracting a formal representation of the agent's response and, subsequently, using formal verification and program analysis tools to verify the agent's reasoning steps. We applied this approach to a benchmark set of 20 uninitialized variable errors detected by sanitizers and 20 program equivalence queries. For the uninitialized variable errors, the formal verification step was able to validate the agent's reasoning on 13/20 examples, and for the program equivalence queries, the formal verification step successfully caught 6/8 incorrect judgments made by the agent.
Agentic Bug Reproduction for Effective Automated Program Repair at Google
Feb 03, 2025



Bug reports often lack sufficient detail for developers to reproduce and fix the underlying defects. Bug Reproduction Tests (BRTs), tests that fail when the bug is present and pass when it has been resolved, are crucial for debugging, but they are rarely included in bug reports, both in open-source and in industrial settings. Thus, automatically generating BRTs from bug reports has the potential to accelerate the debugging process and lower time to repair. This paper investigates automated BRT generation within an industry setting, specifically at Google, focusing on the challenges of a large-scale, proprietary codebase and considering real-world industry bugs extracted from Google's internal issue tracker. We adapt and evaluate a state-of-the-art BRT generation technique, LIBRO, and present our agent-based approach, BRT Agent, which makes use of a fine-tuned Large Language Model (LLM) for code editing. Our BRT Agent significantly outperforms LIBRO, achieving a 28% plausible BRT generation rate, compared to 10% by LIBRO, on 80 human-reported bugs from Google's internal issue tracker. We further investigate the practical value of generated BRTs by integrating them with an Automated Program Repair (APR) system at Google. Our results show that providing BRTs to the APR system results in 30% more bugs with plausible fixes. Additionally, we introduce Ensemble Pass Rate (EPR), a metric which leverages the generated BRTs to select the most promising fixes from all fixes generated by APR system. Our evaluation on EPR for Top-K and threshold-based fix selections demonstrates promising results and trade-offs. For example, EPR correctly selects a plausible fix from a pool of 20 candidates in 70% of cases, based on its top-1 ranking.
Evaluating Agent-based Program Repair at Google
Jan 13, 2025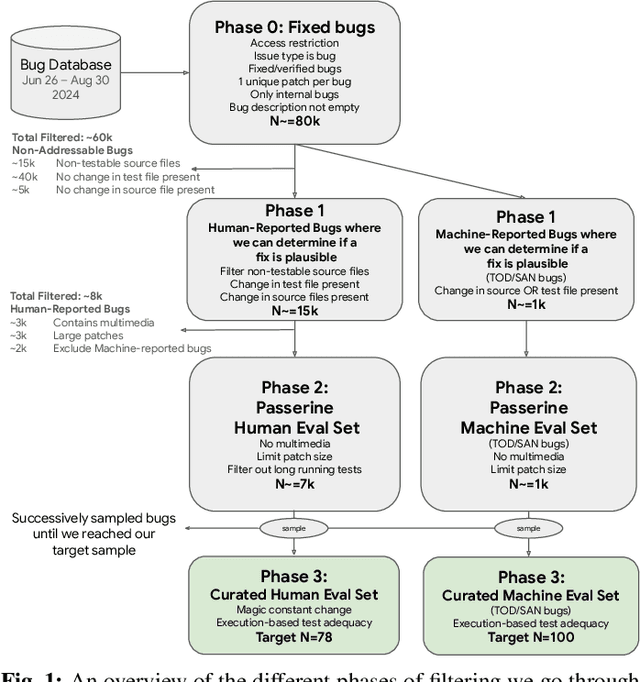



Agent-based program repair offers to automatically resolve complex bugs end-to-end by combining the planning, tool use, and code generation abilities of modern LLMs. Recent work has explored the use of agent-based repair approaches on the popular open-source SWE-Bench, a collection of bugs from highly-rated GitHub Python projects. In addition, various agentic approaches such as SWE-Agent have been proposed to solve bugs in this benchmark. This paper explores the viability of using an agentic approach to address bugs in an enterprise context. To investigate this, we curate an evaluation set of 178 bugs drawn from Google's issue tracking system. This dataset spans both human-reported (78) and machine-reported bugs (100). To establish a repair performance baseline on this benchmark, we implement Passerine, an agent similar in spirit to SWE-Agent that can work within Google's development environment. We show that with 20 trajectory samples and Gemini 1.5 Pro, Passerine can produce a patch that passes bug tests (i.e., plausible) for 73% of machine-reported and 25.6% of human-reported bugs in our evaluation set. After manual examination, we found that 43% of machine-reported bugs and 17.9% of human-reported bugs have at least one patch that is semantically equivalent to the ground-truth patch. These results establish a baseline on an industrially relevant benchmark, which as we show, contains bugs drawn from a different distribution -- in terms of language diversity, size, and spread of changes, etc. -- compared to those in the popular SWE-Bench dataset.
Chatting with Logs: An exploratory study on Finetuning LLMs for LogQL
Dec 04, 2024Logging is a critical function in modern distributed applications, but the lack of standardization in log query languages and formats creates significant challenges. Developers currently must write ad hoc queries in platform-specific languages, requiring expertise in both the query language and application-specific log details -- an impractical expectation given the variety of platforms and volume of logs and applications. While generating these queries with large language models (LLMs) seems intuitive, we show that current LLMs struggle with log-specific query generation due to the lack of exposure to domain-specific knowledge. We propose a novel natural language (NL) interface to address these inconsistencies and aide log query generation, enabling developers to create queries in a target log query language by providing NL inputs. We further introduce ~\textbf{NL2QL}, a manually annotated, real-world dataset of natural language questions paired with corresponding LogQL queries spread across three log formats, to promote the training and evaluation of NL-to-loq query systems. Using NL2QL, we subsequently fine-tune and evaluate several state of the art LLMs, and demonstrate their improved capability to generate accurate LogQL queries. We perform further ablation studies to demonstrate the effect of additional training data, and the transferability across different log formats. In our experiments, we find up to 75\% improvement of finetuned models to generate LogQL queries compared to non finetuned models.
An Empirical Study of Validating Synthetic Data for Formula Generation
Jul 15, 2024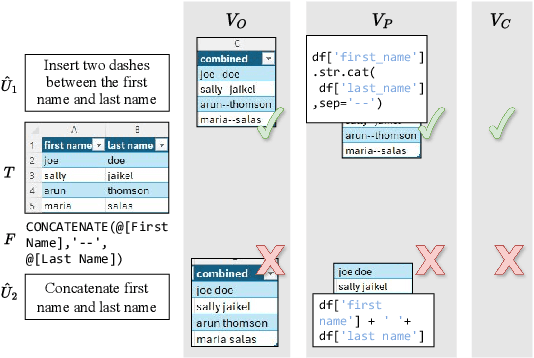
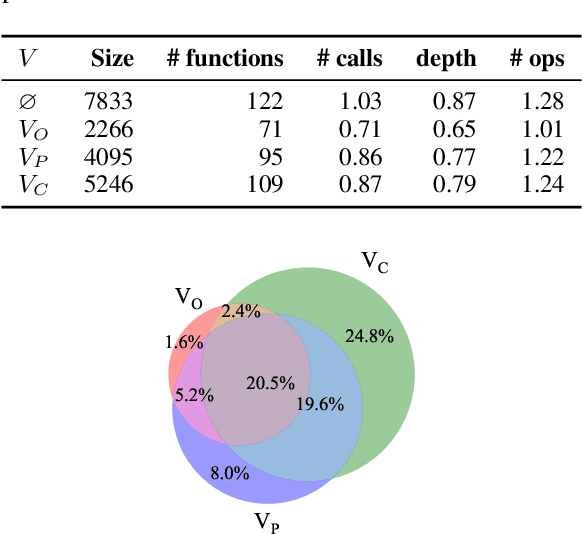
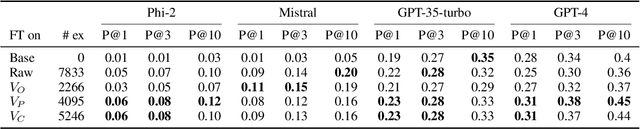
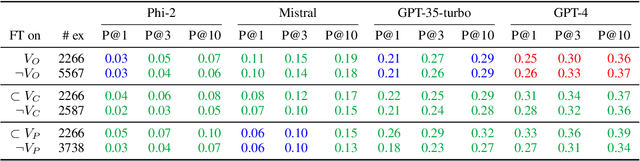
Large language models (LLMs) can be leveraged to help with writing formulas in spreadsheets, but resources on these formulas are scarce, impacting both the base performance of pre-trained models and limiting the ability to fine-tune them. Given a corpus of formulas, we can use a(nother) model to generate synthetic natural language utterances for fine-tuning. However, it is important to validate whether the NL generated by the LLM is indeed accurate to be beneficial for fine-tuning. In this paper, we provide empirical results on the impact of validating these synthetic training examples with surrogate objectives that evaluate the accuracy of the synthetic annotations. We demonstrate that validation improves performance over raw data across four models (2 open and 2 closed weight). Interestingly, we show that although validation tends to prune more challenging examples, it increases the complexity of problems that models can solve after being fine-tuned on validated data.
SpreadsheetLLM: Encoding Spreadsheets for Large Language Models
Jul 12, 2024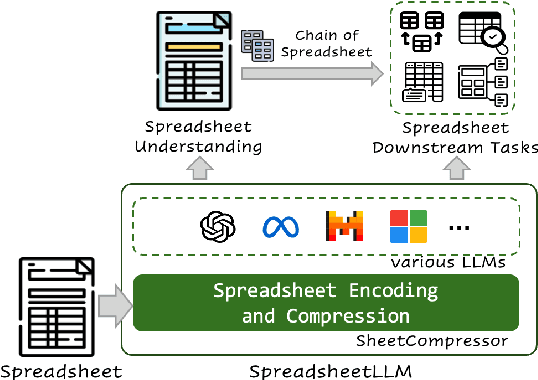

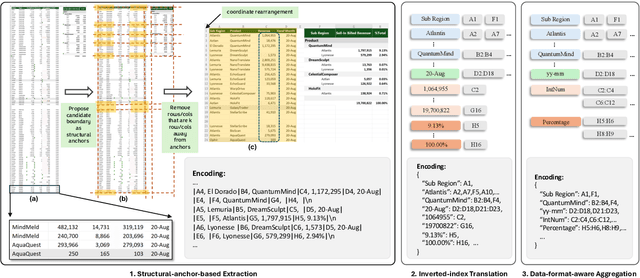
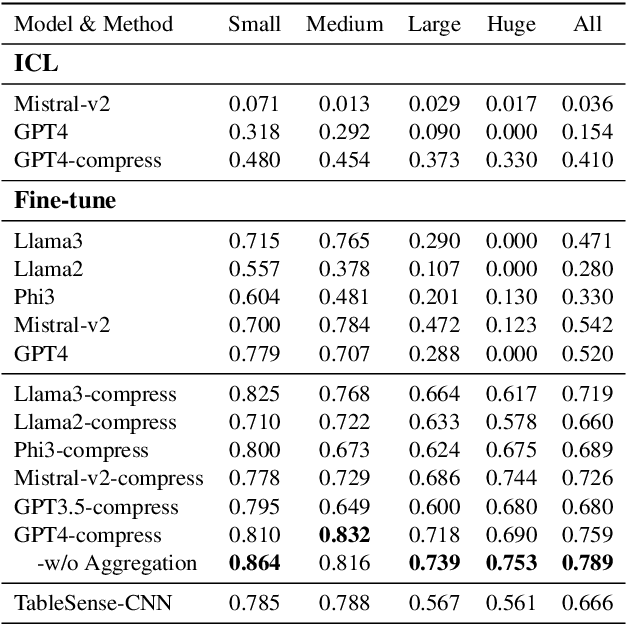
Spreadsheets, with their extensive two-dimensional grids, various layouts, and diverse formatting options, present notable challenges for large language models (LLMs). In response, we introduce SpreadsheetLLM, pioneering an efficient encoding method designed to unleash and optimize LLMs' powerful understanding and reasoning capability on spreadsheets. Initially, we propose a vanilla serialization approach that incorporates cell addresses, values, and formats. However, this approach was limited by LLMs' token constraints, making it impractical for most applications. To tackle this challenge, we develop SheetCompressor, an innovative encoding framework that compresses spreadsheets effectively for LLMs. It comprises three modules: structural-anchor-based compression, inverse index translation, and data-format-aware aggregation. It significantly improves performance in spreadsheet table detection task, outperforming the vanilla approach by 25.6% in GPT4's in-context learning setting. Moreover, fine-tuned LLM with SheetCompressor has an average compression ratio of 25 times, but achieves a state-of-the-art 78.9% F1 score, surpassing the best existing models by 12.3%. Finally, we propose Chain of Spreadsheet for downstream tasks of spreadsheet understanding and validate in a new and demanding spreadsheet QA task. We methodically leverage the inherent layout and structure of spreadsheets, demonstrating that SpreadsheetLLM is highly effective across a variety of spreadsheet tasks.
Solving Data-centric Tasks using Large Language Models
Feb 18, 2024
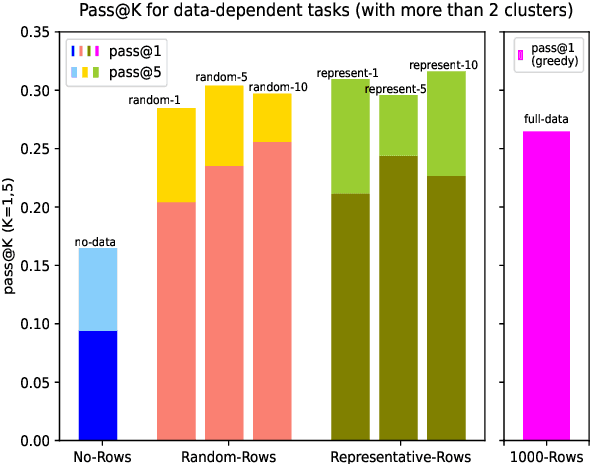
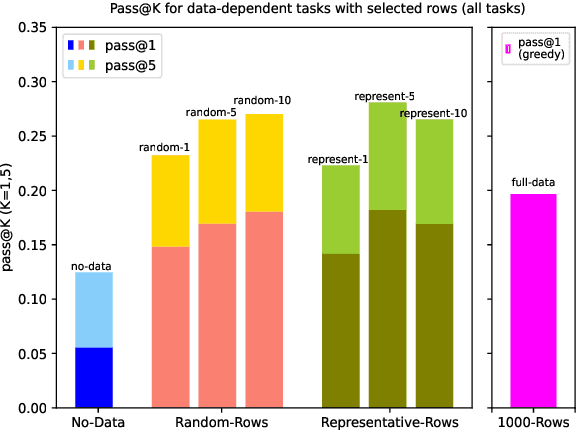
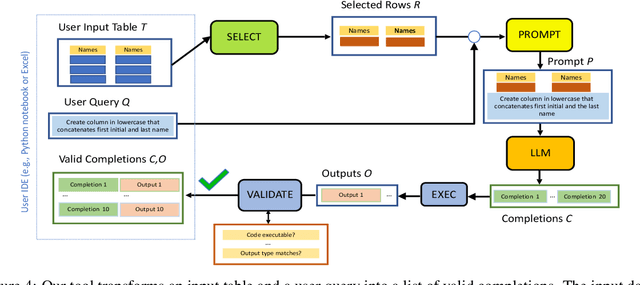
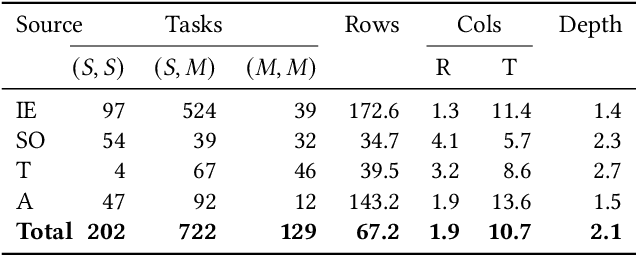
Large language models (LLMs) are rapidly replacing help forums like StackOverflow, and are especially helpful for non-professional programmers and end users. These users are often interested in data-centric tasks, such as spreadsheet manipulation and data wrangling, which are hard to solve if the intent is only communicated using a natural-language description, without including the data. But how do we decide how much data and which data to include in the prompt? This paper makes two contributions towards answering this question. First, we create a dataset of real-world NL-to-code tasks manipulating tabular data, mined from StackOverflow posts. Second, we introduce a cluster-then-select prompting technique, which adds the most representative rows from the input data to the LLM prompt. Our experiments show that LLM performance is indeed sensitive to the amount of data passed in the prompt, and that for tasks with a lot of syntactic variation in the input table, our cluster-then-select technique outperforms a random selection baseline.
Assessing GPT4-V on Structured Reasoning Tasks
Dec 13, 2023Multi-modality promises to unlock further uses for large language models. Recently, the state-of-the-art language model GPT-4 was enhanced with vision capabilities. We carry out a prompting evaluation of GPT-4V and five other baselines on structured reasoning tasks, such as mathematical reasoning, visual data analysis, and code generation. We show that visual Chain-of-Thought, an extension of Chain-of-Thought to multi-modal LLMs, yields significant improvements over the vanilla model. We also present a categorized analysis of scenarios where these models perform well and where they struggle, highlighting challenges associated with coherent multimodal reasoning.
FormaT5: Abstention and Examples for Conditional Table Formatting with Natural Language
Nov 01, 2023

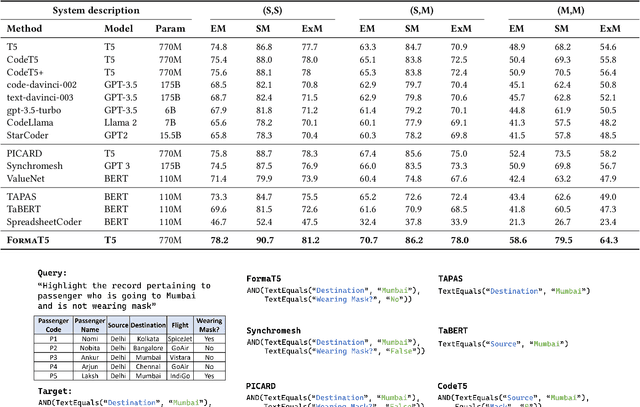
Formatting is an important property in tables for visualization, presentation, and analysis. Spreadsheet software allows users to automatically format their tables by writing data-dependent conditional formatting (CF) rules. Writing such rules is often challenging for users as it requires them to understand and implement the underlying logic. We present FormaT5, a transformer-based model that can generate a CF rule given the target table and a natural language description of the desired formatting logic. We find that user descriptions for these tasks are often under-specified or ambiguous, making it harder for code generation systems to accurately learn the desired rule in a single step. To tackle this problem of under-specification and minimise argument errors, FormaT5 learns to predict placeholders though an abstention objective. These placeholders can then be filled by a second model or, when examples of rows that should be formatted are available, by a programming-by-example system. To evaluate FormaT5 on diverse and real scenarios, we create an extensive benchmark of 1053 CF tasks, containing real-world descriptions collected from four different sources. We release our benchmarks to encourage research in this area. Abstention and filling allow FormaT5 to outperform 8 different neural approaches on our benchmarks, both with and without examples. Our results illustrate the value of building domain-specific learning systems.