 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Fine-Grained Should a RAG Benchmark Be? A Hierarchical Framework for Synthetic Question Generation
Jun 11, 2026Evaluating retrieval-augmented generation (RAG) systems requires benchmarks that capture diverse question characteristics, yet practitioners lack empirical guidance on which dimensions to vary and at what granularity. We present HieraRAG, a hierarchical framework for studying granularity in RAG benchmark construction, defining optimal granularity as the level that maximizes discriminative power (the standard deviation of generation quality across categories) within a given RAG configuration. As a case study, we generate 5,872 synthetic question-answer (QA) pairs from FineWeb-10BT across 3 dimensions (Question Complexity, Answer Type, Linguistic Variation) at 3 granularity levels (2, 4, and 8 categories). With a BM25+Falcon-3-10B pipeline, optimal granularity varies by dimension: complexity benefits from fine-grained distinctions (discriminative power: 0.053) while answer type and linguistic variation peak at medium granularity. We introduce a Coherence Ratio metric to quantify whether fine-grained splits cleanly subdivide parent categories, revealing structural differences across dimensions (Question Complexity: 0.40 vs. Answer Type: 1.44). Human evaluation of 110 stratified QA pairs confirms synthetic quality. While these specific findings reflect a single configuration, HieraRAG provides a portable procedure and validation metric for practitioners to determine evaluation granularity within their own RAG settings.
Agents' Last Exam
Jun 03, 2026Recent AI systems have achieved strong results on a wide range of benchmarks, yet these gains have not translated into economically meaningful deployment across many professional domains. We argue that this gap is largely an evaluation problem: widely used benchmarks lack sustained performance measurement on real and economically valuable workflows. This paper introduces Agents' Last Exam (ALE), a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. Developed in collaboration with 250+ industry experts, ALE covers non-physical industries defined with reference to O*NET / SOC 2018 (the U.S. federal occupational taxonomy). It is organized around a task taxonomy with 55 subfields grouped into 13 industry clusters covering 1K+ tasks. Current results show that the hardest tier remains far from saturated: across mainstream harness and backbone configurations, the average full pass rate is 2.6%. ALE is designed as a living benchmark: its task pool grows continuously as new workflows and industries are onboarded. More broadly, ALE is intended not merely as another leaderboard, but as an instrument for closing the gap between benchmark success and GDP-relevant impact.
Scaling Laws for Reranking in Information Retrieval
Mar 05, 2026Scaling laws have been observed across a wide range of tasks, such as natural language generation and dense retrieval, where performance follows predictable patterns as model size, data, and compute grow. However, these scaling laws are insufficient for understanding the scaling behavior of multi-stage retrieval systems, which typically include a reranking stage. In large-scale multi-stage retrieval systems, reranking is the final and most influential step before presenting a ranked list of items to the end user. In this work, we present the first systematic study of scaling laws for rerankers by analyzing performance across model sizes and data budgets for three popular paradigms: pointwise, pairwise, and listwise reranking. Using a detailed case study with cross-encoder rerankers, we demonstrate that performance follows a predictable power law. This regularity allows us to accurately forecast the performance of larger models for some metrics more than others using smaller-scale experiments, offering a robust methodology for saving significant computational resources. For example, we accurately estimate the NDCG of a 1B-parameter model by training and evaluating only smaller models (up to 400M parameters), in both in-domain as well as out-of-domain settings. Our experiments encompass span several loss functions, models and metrics and demonstrate that downstream metrics like NDCG, MAP (Mean Avg Precision) show reliable scaling behavior and can be forecasted accurately at scale, while highlighting the limitations of metrics like Contrastive Entropy and MRR (Mean Reciprocal Rank) which do not follow predictable scaling behavior in all instances. Our results establish scaling principles for reranking and provide actionable insights for building industrial-grade retrieval systems.
Adversarial Lens: Exploiting Attention Layers to Generate Adversarial Examples for Evaluation
Dec 29, 2025Recent advances in mechanistic interpretability suggest that intermediate attention layers encode token-level hypotheses that are iteratively refined toward the final output. In this work, we exploit this property to generate adversarial examples directly from attention-layer token distributions. Unlike prompt-based or gradient-based attacks, our approach leverages model-internal token predictions, producing perturbations that are both plausible and internally consistent with the model's own generation process. We evaluate whether tokens extracted from intermediate layers can serve as effective adversarial perturbations for downstream evaluation tasks. We conduct experiments on argument quality assessment using the ArgQuality dataset, with LLaMA-3.1-Instruct-8B serving as both the generator and evaluator. Our results show that attention-based adversarial examples lead to measurable drops in evaluation performance while remaining semantically similar to the original inputs. However, we also observe that substitutions drawn from certain layers and token positions can introduce grammatical degradation, limiting their practical effectiveness. Overall, our findings highlight both the promise and current limitations of using intermediate-layer representations as a principled source of adversarial examples for stress-testing LLM-based evaluation pipelines.
Stabilizing Reinforcement Learning for Honesty Alignment in Language Models on Deductive Reasoning
Nov 12, 2025Reinforcement learning with verifiable rewards (RLVR) has recently emerged as a promising framework for aligning language models with complex reasoning objectives. However, most existing methods optimize only for final task outcomes, leaving models vulnerable to collapse when negative rewards dominate early training. This challenge is especially pronounced in honesty alignment, where models must not only solve answerable queries but also identify when conclusions cannot be drawn from the given premises. Deductive reasoning provides an ideal testbed because it isolates reasoning capability from reliance on external factual knowledge. To investigate honesty alignment, we curate two multi-step deductive reasoning datasets from graph structures, one for linear algebra and one for logical inference, and introduce unanswerable cases by randomly perturbing an edge in half of the instances. We find that GRPO, with or without supervised fine tuning initialization, struggles on these tasks. Through extensive experiments across three models, we evaluate stabilization strategies and show that curriculum learning provides some benefit but requires carefully designed in distribution datasets with controllable difficulty. To address these limitations, we propose Anchor, a reinforcement learning method that injects ground truth trajectories into rollouts, preventing early training collapse. Our results demonstrate that this method stabilizes learning and significantly improves the overall reasoning performance, underscoring the importance of training dynamics for enabling reliable deductive reasoning in aligned language models.
Chatting with Logs: An exploratory study on Finetuning LLMs for LogQL
Dec 04, 2024Logging is a critical function in modern distributed applications, but the lack of standardization in log query languages and formats creates significant challenges. Developers currently must write ad hoc queries in platform-specific languages, requiring expertise in both the query language and application-specific log details -- an impractical expectation given the variety of platforms and volume of logs and applications. While generating these queries with large language models (LLMs) seems intuitive, we show that current LLMs struggle with log-specific query generation due to the lack of exposure to domain-specific knowledge. We propose a novel natural language (NL) interface to address these inconsistencies and aide log query generation, enabling developers to create queries in a target log query language by providing NL inputs. We further introduce ~\textbf{NL2QL}, a manually annotated, real-world dataset of natural language questions paired with corresponding LogQL queries spread across three log formats, to promote the training and evaluation of NL-to-loq query systems. Using NL2QL, we subsequently fine-tune and evaluate several state of the art LLMs, and demonstrate their improved capability to generate accurate LogQL queries. We perform further ablation studies to demonstrate the effect of additional training data, and the transferability across different log formats. In our experiments, we find up to 75\% improvement of finetuned models to generate LogQL queries compared to non finetuned models.
GenQREnsemble: Zero-Shot LLM Ensemble Prompting for Generative Query Reformulation
Apr 04, 2024Query Reformulation(QR) is a set of techniques used to transform a user's original search query to a text that better aligns with the user's intent and improves their search experience. Recently, zero-shot QR has been shown to be a promising approach due to its ability to exploit knowledge inherent in large language models. By taking inspiration from the success of ensemble prompting strategies which have benefited many tasks, we investigate if they can help improve query reformulation. In this context, we propose an ensemble based prompting technique, GenQREnsemble which leverages paraphrases of a zero-shot instruction to generate multiple sets of keywords ultimately improving retrieval performance. We further introduce its post-retrieval variant, GenQREnsembleRF to incorporate pseudo relevant feedback. On evaluations over four IR benchmarks, we find that GenQREnsemble generates better reformulations with relative nDCG@10 improvements up to 18% and MAP improvements upto 24% over the previous zero-shot state-of-art. On the MSMarco Passage Ranking task, GenQREnsembleRF shows relative gains of 5% MRR using pseudo-relevance feedback, and 9% nDCG@10 using relevant feedback documents.
Contextual Response Interpretation for Automated Structured Interviews: A Case Study in Market Research
Apr 30, 2023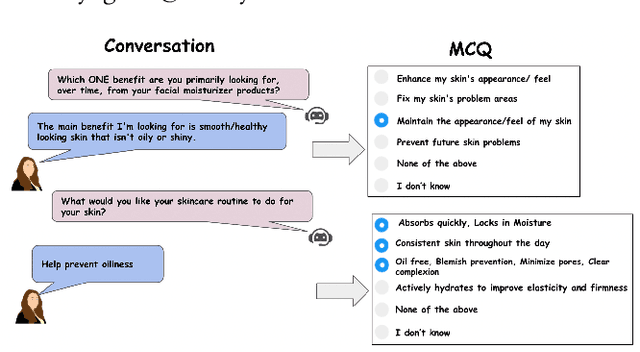
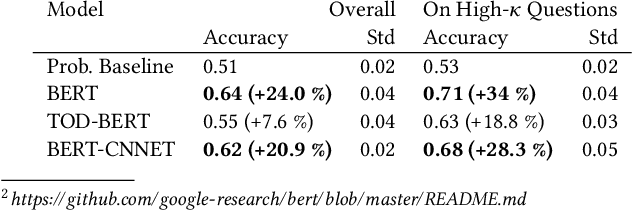
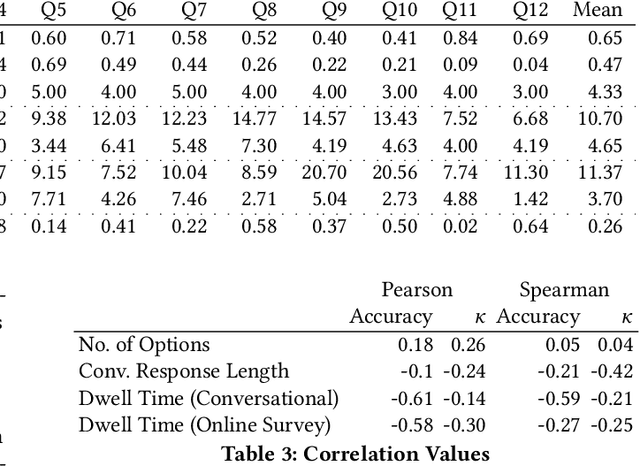
Structured interviews are used in many settings, importantly in market research on topics such as brand perception, customer habits, or preferences, which are critical to product development, marketing, and e-commerce at large. Such interviews generally consist of a series of questions that are asked to a participant. These interviews are typically conducted by skilled interviewers, who interpret the responses from the participants and can adapt the interview accordingly. Using automated conversational agents to conduct such interviews would enable reaching a much larger and potentially more diverse group of participants than currently possible. However, the technical challenges involved in building such a conversational system are relatively unexplored. To learn more about these challenges, we convert a market research multiple-choice questionnaire to a conversational format and conduct a user study. We address the key task of conducting structured interviews, namely interpreting the participant's response, for example, by matching it to one or more predefined options. Our findings can be applied to improve response interpretation for the information elicitation phase of conversational recommender systems.
Is AI Art Another Industrial Revolution in the Making?
Jan 12, 2023A major shift from skilled to unskilled workers was one of the many changes caused by the Industrial Revolution, when the switch to machines contributed to decline in the social and economic status of artisans, whose skills were dismembered into discrete actions by factory-line workers. We consider what may be an analogous computing technology: the recent introduction of AI-generated art software. AI art generators such as Dall-E and Midjourney can create fully rendered images based solely on a user's prompt, just at the click of a button. Some artists fear if the cheaper price and conveyor-belt speed that comes with AI-produced images is seen as an improvement to the current system, it may permanently change the way society values/views art and artists. In this article, we consider the implications that AI art generation introduces through a post-industrial revolution historical lens. We then reflect on the analogous issues that appear to arise as a result of the AI art revolution, and we conclude that the problems raised mirror those of industrialization, giving a vital glimpse into what may lie ahead.
GEMv2: Multilingual NLG Benchmarking in a Single Line of Code
Jun 24, 2022



Evaluation in machine learning is usually informed by past choices, for example which datasets or metrics to use. This standardization enables the comparison on equal footing using leaderboards, but the evaluation choices become sub-optimal as better alternatives arise. This problem is especially pertinent in natural language generation which requires ever-improving suites of datasets, metrics, and human evaluation to make definitive claims. To make following best model evaluation practices easier, we introduce GEMv2. The new version of the Generation, Evaluation, and Metrics Benchmark introduces a modular infrastructure for dataset, model, and metric developers to benefit from each others work. GEMv2 supports 40 documented datasets in 51 languages. Models for all datasets can be evaluated online and our interactive data card creation and rendering tools make it easier to add new datasets to the living benchmark.