 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRubricRAG: Towards Interpretable and Reliable LLM Evaluation via Domain Knowledge Retrieval for Rubric Generation
Mar 21, 2026Large language models (LLMs) are increasingly evaluated and sometimes trained using automated graders such as LLM-as-judges that output scalar scores or preferences. While convenient, these approaches are often opaque: a single score rarely explains why an answer is good or bad, which requirements were missed, or how a system should be improved. This lack of interpretability limits their usefulness for model development, dataset curation, and high-stakes deployment. Query-specific rubric-based evaluation offers a more transparent alternative by decomposing quality into explicit, checkable criteria. However, manually designing high-quality, query-specific rubrics is labor-intensive and cognitively demanding and not feasible for deployment. While previous approaches have focused on generating intermediate rubrics for automated downstream evaluation, it is unclear if these rubrics are both interpretable and effective for human users. In this work, we investigate whether LLMs can generate useful, instance-specific rubrics as compared to human-authored rubrics, while also improving effectiveness for identifying good responses. Through our systematic study on two rubric benchmarks, and on multiple few-shot and post-training strategies, we find that off-the-shelf LLMs produce rubrics that are poorly aligned with human-authored ones. We introduce a simple strategy, RubricRAG, which retrieves domain knowledge via rubrics at inference time from related queries. We demonstrate that RubricRAG can generate more interpretable rubrics both for similarity to human-authored rubrics, and for improved downstream evaluation effectiveness. Our results highlight both the challenges and a promising approach of scalable, interpretable evaluation through automated rubric generation.
Generative Product Recommendations for Implicit Superlative Queries
Apr 26, 2025In Recommender Systems, users often seek the best products through indirect, vague, or under-specified queries, such as "best shoes for trail running". Such queries, also referred to as implicit superlative queries, pose a significant challenge for standard retrieval and ranking systems as they lack an explicit mention of attributes and require identifying and reasoning over complex factors. We investigate how Large Language Models (LLMs) can generate implicit attributes for ranking as well as reason over them to improve product recommendations for such queries. As a first step, we propose a novel four-point schema for annotating the best product candidates for superlative queries called SUPERB, paired with LLM-based product annotations. We then empirically evaluate several existing retrieval and ranking approaches on our new dataset, providing insights and discussing their integration into real-world e-commerce production systems.
ConQRet: Benchmarking Fine-Grained Evaluation of Retrieval Augmented Argumentation with LLM Judges
Dec 06, 2024Computational argumentation, which involves generating answers or summaries for controversial topics like abortion bans and vaccination, has become increasingly important in today's polarized environment. Sophisticated LLM capabilities offer the potential to provide nuanced, evidence-based answers to such questions through Retrieval-Augmented Argumentation (RAArg), leveraging real-world evidence for high-quality, grounded arguments. However, evaluating RAArg remains challenging, as human evaluation is costly and difficult for complex, lengthy answers on complicated topics. At the same time, re-using existing argumentation datasets is no longer sufficient, as they lack long, complex arguments and realistic evidence from potentially misleading sources, limiting holistic evaluation of retrieval effectiveness and argument quality. To address these gaps, we investigate automated evaluation methods using multiple fine-grained LLM judges, providing better and more interpretable assessments than traditional single-score metrics and even previously reported human crowdsourcing. To validate the proposed techniques, we introduce ConQRet, a new benchmark featuring long and complex human-authored arguments on debated topics, grounded in real-world websites, allowing an exhaustive evaluation across retrieval effectiveness, argument quality, and groundedness. We validate our LLM Judges on a prior dataset and the new ConQRet benchmark. Our proposed LLM Judges and the ConQRet benchmark can enable rapid progress in computational argumentation and can be naturally extended to other complex retrieval-augmented generation tasks.
Generative Query Reformulation Using Ensemble Prompting, Document Fusion, and Relevance Feedback
May 27, 2024
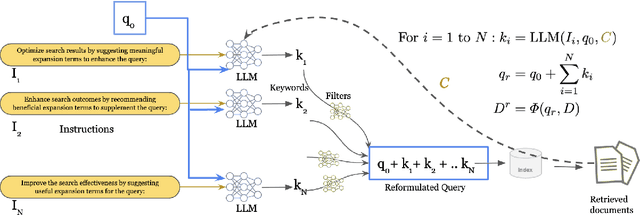
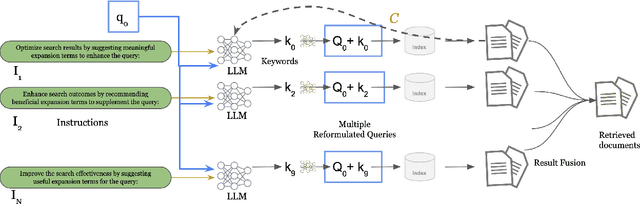
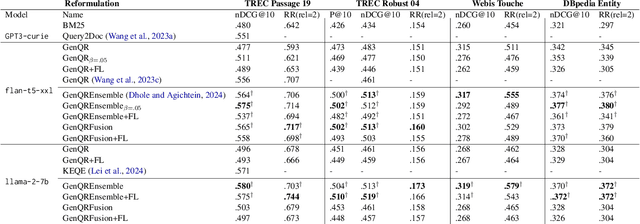
Query Reformulation (QR) is a set of techniques used to transform a user's original search query to a text that better aligns with the user's intent and improves their search experience. Recently, zero-shot QR has been a promising approach due to its ability to exploit knowledge inherent in large language models. Inspired by the success of ensemble prompting strategies which have benefited other tasks, we investigate if they can improve query reformulation. In this context, we propose two ensemble-based prompting techniques, GenQREnsemble and GenQRFusion which leverage paraphrases of a zero-shot instruction to generate multiple sets of keywords to improve retrieval performance ultimately. We further introduce their post-retrieval variants to incorporate relevance feedback from a variety of sources, including an oracle simulating a human user and a "critic" LLM. We demonstrate that an ensemble of query reformulations can improve retrieval effectiveness by up to 18% on nDCG@10 in pre-retrieval settings and 9% on post-retrieval settings on multiple benchmarks, outperforming all previously reported SOTA results. We perform subsequent analyses to investigate the effects of feedback documents, incorporate domain-specific instructions, filter reformulations, and generate fluent reformulations that might be more beneficial to human searchers. Together, the techniques and the results presented in this paper establish a new state of the art in automated query reformulation for retrieval and suggest promising directions for future research.
Leveraging Interesting Facts to Enhance User Engagement with Conversational Interfaces
Apr 09, 2024



Conversational Task Assistants (CTAs) guide users in performing a multitude of activities, such as making recipes. However, ensuring that interactions remain engaging, interesting, and enjoyable for CTA users is not trivial, especially for time-consuming or challenging tasks. Grounded in psychological theories of human interest, we propose to engage users with contextual and interesting statements or facts during interactions with a multi-modal CTA, to reduce fatigue and task abandonment before a task is complete. To operationalize this idea, we train a high-performing classifier (82% F1-score) to automatically identify relevant and interesting facts for users. We use it to create an annotated dataset of task-specific interesting facts for the domain of cooking. Finally, we design and validate a dialogue policy to incorporate the identified relevant and interesting facts into a conversation, to improve user engagement and task completion. Live testing on a leading multi-modal voice assistant shows that 66% of the presented facts were received positively, leading to a 40% gain in the user satisfaction rating, and a 37% increase in conversation length. These findings emphasize that strategically incorporating interesting facts into the CTA experience can promote real-world user participation for guided task interactions.
GenQREnsemble: Zero-Shot LLM Ensemble Prompting for Generative Query Reformulation
Apr 04, 2024Query Reformulation(QR) is a set of techniques used to transform a user's original search query to a text that better aligns with the user's intent and improves their search experience. Recently, zero-shot QR has been shown to be a promising approach due to its ability to exploit knowledge inherent in large language models. By taking inspiration from the success of ensemble prompting strategies which have benefited many tasks, we investigate if they can help improve query reformulation. In this context, we propose an ensemble based prompting technique, GenQREnsemble which leverages paraphrases of a zero-shot instruction to generate multiple sets of keywords ultimately improving retrieval performance. We further introduce its post-retrieval variant, GenQREnsembleRF to incorporate pseudo relevant feedback. On evaluations over four IR benchmarks, we find that GenQREnsemble generates better reformulations with relative nDCG@10 improvements up to 18% and MAP improvements upto 24% over the previous zero-shot state-of-art. On the MSMarco Passage Ranking task, GenQREnsembleRF shows relative gains of 5% MRR using pseudo-relevance feedback, and 9% nDCG@10 using relevant feedback documents.
DUQGen: Effective Unsupervised Domain Adaptation of Neural Rankers by Diversifying Synthetic Query Generation
Apr 03, 2024State-of-the-art neural rankers pre-trained on large task-specific training data such as MS-MARCO, have been shown to exhibit strong performance on various ranking tasks without domain adaptation, also called zero-shot. However, zero-shot neural ranking may be sub-optimal, as it does not take advantage of the target domain information. Unfortunately, acquiring sufficiently large and high quality target training data to improve a modern neural ranker can be costly and time-consuming. To address this problem, we propose a new approach to unsupervised domain adaptation for ranking, DUQGen, which addresses a critical gap in prior literature, namely how to automatically generate both effective and diverse synthetic training data to fine tune a modern neural ranker for a new domain. Specifically, DUQGen produces a more effective representation of the target domain by identifying clusters of similar documents; and generates a more diverse training dataset by probabilistic sampling over the resulting document clusters. Our extensive experiments, over the standard BEIR collection, demonstrate that DUQGen consistently outperforms all zero-shot baselines and substantially outperforms the SOTA baselines on 16 out of 18 datasets, for an average of 4% relative improvement across all datasets. We complement our results with a thorough analysis for more in-depth understanding of the proposed method's performance and to identify promising areas for further improvements.
QueryExplorer: An Interactive Query Generation Assistant for Search and Exploration
Mar 23, 2024Formulating effective search queries remains a challenging task, particularly when users lack expertise in a specific domain or are not proficient in the language of the content. Providing example documents of interest might be easier for a user. However, such query-by-example scenarios are prone to concept drift, and the retrieval effectiveness is highly sensitive to the query generation method, without a clear way to incorporate user feedback. To enable exploration and to support Human-In-The-Loop experiments we propose QueryExplorer -- an interactive query generation, reformulation, and retrieval interface with support for HuggingFace generation models and PyTerrier's retrieval pipelines and datasets, and extensive logging of human feedback. To allow users to create and modify effective queries, our demo supports complementary approaches of using LLMs interactively, assisting the user with edits and feedback at multiple stages of the query formulation process. With support for recording fine-grained interactions and user annotations, QueryExplorer can serve as a valuable experimental and research platform for annotation, qualitative evaluation, and conducting Human-in-the-Loop (HITL) experiments for complex search tasks where users struggle to formulate queries.
Evaluation Metrics of Language Generation Models for Synthetic Traffic Generation Tasks
Nov 21, 2023Many Natural Language Generation (NLG) tasks aim to generate a single output text given an input prompt. Other settings require the generation of multiple texts, e.g., for Synthetic Traffic Generation (STG). This generation task is crucial for training and evaluating QA systems as well as conversational agents, where the goal is to generate multiple questions or utterances resembling the linguistic variability of real users. In this paper, we show that common NLG metrics, like BLEU, are not suitable for evaluating STG. We propose and evaluate several metrics designed to compare the generated traffic to the distribution of real user texts. We validate our metrics with an automatic procedure to verify whether they capture different types of quality issues of generated data; we also run human annotations to verify the correlation with human judgements. Experiments on three tasks, i.e., Shopping Utterance Generation, Product Question Generation and Query Auto Completion, demonstrate that our metrics are effective for evaluating STG tasks, and improve the agreement with human judgement up to 20% with respect to common NLG metrics. We believe these findings can pave the way towards better solutions for estimating the representativeness of synthetic text data.
An Interactive Query Generation Assistant using LLM-based Prompt Modification and User Feedback
Nov 19, 2023
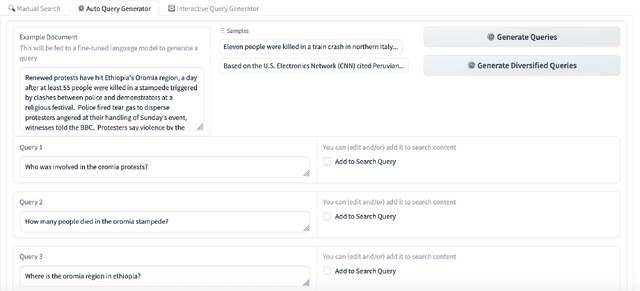
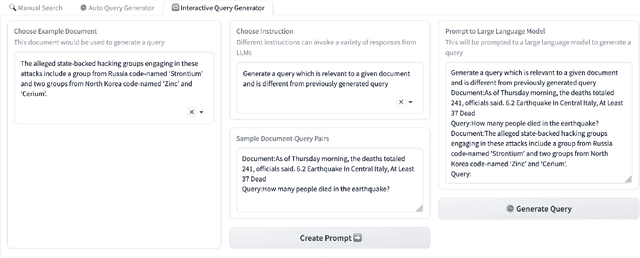
While search is the predominant method of accessing information, formulating effective queries remains a challenging task, especially for situations where the users are not familiar with a domain, or searching for documents in other languages, or looking for complex information such as events, which are not easily expressible as queries. Providing example documents or passages of interest, might be easier for a user, however, such query-by-example scenarios are prone to concept drift, and are highly sensitive to the query generation method. This demo illustrates complementary approaches of using LLMs interactively, assisting and enabling the user to provide edits and feedback at all stages of the query formulation process. The proposed Query Generation Assistant is a novel search interface which supports automatic and interactive query generation over a mono-linguial or multi-lingual document collection. Specifically, the proposed assistive interface enables the users to refine the queries generated by different LLMs, to provide feedback on the retrieved documents or passages, and is able to incorporate the users' feedback as prompts to generate more effective queries. The proposed interface is a valuable experimental tool for exploring fine-tuning and prompting of LLMs for query generation to qualitatively evaluate the effectiveness of retrieval and ranking models, and for conducting Human-in-the-Loop (HITL) experiments for complex search tasks where users struggle to formulate queries without such assistance.