 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBradley-Terry and Multi-Objective Reward Modeling Are Complementary
Jul 10, 2025Reward models trained on human preference data have demonstrated strong effectiveness in aligning Large Language Models (LLMs) with human intent under the framework of Reinforcement Learning from Human Feedback (RLHF). However, RLHF remains vulnerable to reward hacking, where the policy exploits imperfections in the reward function rather than genuinely learning the intended behavior. Although significant efforts have been made to mitigate reward hacking, they predominantly focus on and evaluate in-distribution scenarios, where the training and testing data for the reward model share the same distribution. In this paper, we empirically show that state-of-the-art methods struggle in more challenging out-of-distribution (OOD) settings. We further demonstrate that incorporating fine-grained multi-attribute scores helps address this challenge. However, the limited availability of high-quality data often leads to weak performance of multi-objective reward functions, which can negatively impact overall performance and become the bottleneck. To address this issue, we propose a unified reward modeling framework that jointly trains Bradley--Terry (BT) single-objective and multi-objective regression-based reward functions using a shared embedding space. We theoretically establish a connection between the BT loss and the regression objective and highlight their complementary benefits. Specifically, the regression task enhances the single-objective reward function's ability to mitigate reward hacking in challenging OOD settings, while BT-based training improves the scoring capability of the multi-objective reward function, enabling a 7B model to outperform a 70B baseline. Extensive experimental results demonstrate that our framework significantly improves both the robustness and the scoring performance of reward models.
Generative Query Reformulation Using Ensemble Prompting, Document Fusion, and Relevance Feedback
May 27, 2024
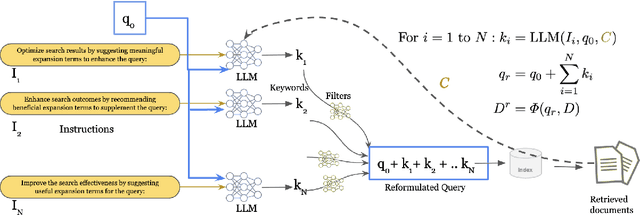
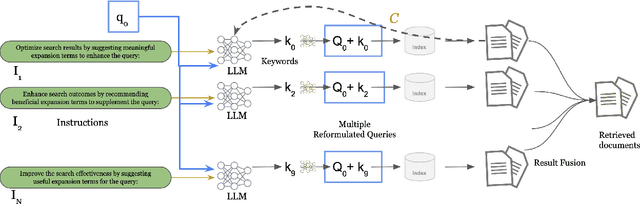
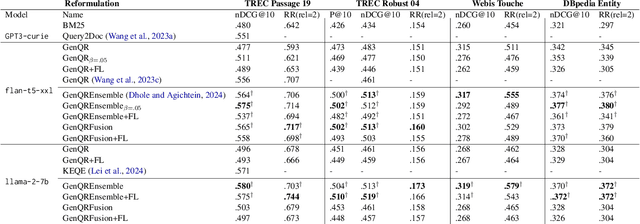
Query Reformulation (QR) is a set of techniques used to transform a user's original search query to a text that better aligns with the user's intent and improves their search experience. Recently, zero-shot QR has been a promising approach due to its ability to exploit knowledge inherent in large language models. Inspired by the success of ensemble prompting strategies which have benefited other tasks, we investigate if they can improve query reformulation. In this context, we propose two ensemble-based prompting techniques, GenQREnsemble and GenQRFusion which leverage paraphrases of a zero-shot instruction to generate multiple sets of keywords to improve retrieval performance ultimately. We further introduce their post-retrieval variants to incorporate relevance feedback from a variety of sources, including an oracle simulating a human user and a "critic" LLM. We demonstrate that an ensemble of query reformulations can improve retrieval effectiveness by up to 18% on nDCG@10 in pre-retrieval settings and 9% on post-retrieval settings on multiple benchmarks, outperforming all previously reported SOTA results. We perform subsequent analyses to investigate the effects of feedback documents, incorporate domain-specific instructions, filter reformulations, and generate fluent reformulations that might be more beneficial to human searchers. Together, the techniques and the results presented in this paper establish a new state of the art in automated query reformulation for retrieval and suggest promising directions for future research.
DUQGen: Effective Unsupervised Domain Adaptation of Neural Rankers by Diversifying Synthetic Query Generation
Apr 03, 2024State-of-the-art neural rankers pre-trained on large task-specific training data such as MS-MARCO, have been shown to exhibit strong performance on various ranking tasks without domain adaptation, also called zero-shot. However, zero-shot neural ranking may be sub-optimal, as it does not take advantage of the target domain information. Unfortunately, acquiring sufficiently large and high quality target training data to improve a modern neural ranker can be costly and time-consuming. To address this problem, we propose a new approach to unsupervised domain adaptation for ranking, DUQGen, which addresses a critical gap in prior literature, namely how to automatically generate both effective and diverse synthetic training data to fine tune a modern neural ranker for a new domain. Specifically, DUQGen produces a more effective representation of the target domain by identifying clusters of similar documents; and generates a more diverse training dataset by probabilistic sampling over the resulting document clusters. Our extensive experiments, over the standard BEIR collection, demonstrate that DUQGen consistently outperforms all zero-shot baselines and substantially outperforms the SOTA baselines on 16 out of 18 datasets, for an average of 4% relative improvement across all datasets. We complement our results with a thorough analysis for more in-depth understanding of the proposed method's performance and to identify promising areas for further improvements.
QueryExplorer: An Interactive Query Generation Assistant for Search and Exploration
Mar 23, 2024Formulating effective search queries remains a challenging task, particularly when users lack expertise in a specific domain or are not proficient in the language of the content. Providing example documents of interest might be easier for a user. However, such query-by-example scenarios are prone to concept drift, and the retrieval effectiveness is highly sensitive to the query generation method, without a clear way to incorporate user feedback. To enable exploration and to support Human-In-The-Loop experiments we propose QueryExplorer -- an interactive query generation, reformulation, and retrieval interface with support for HuggingFace generation models and PyTerrier's retrieval pipelines and datasets, and extensive logging of human feedback. To allow users to create and modify effective queries, our demo supports complementary approaches of using LLMs interactively, assisting the user with edits and feedback at multiple stages of the query formulation process. With support for recording fine-grained interactions and user annotations, QueryExplorer can serve as a valuable experimental and research platform for annotation, qualitative evaluation, and conducting Human-in-the-Loop (HITL) experiments for complex search tasks where users struggle to formulate queries.
An Interactive Query Generation Assistant using LLM-based Prompt Modification and User Feedback
Nov 19, 2023
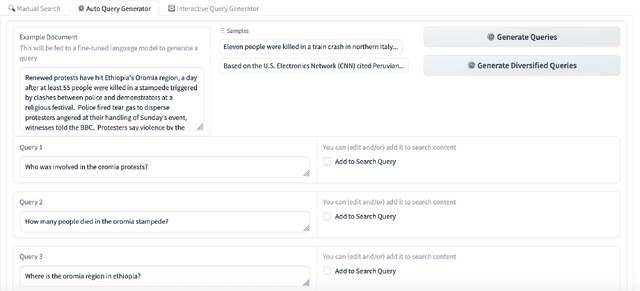
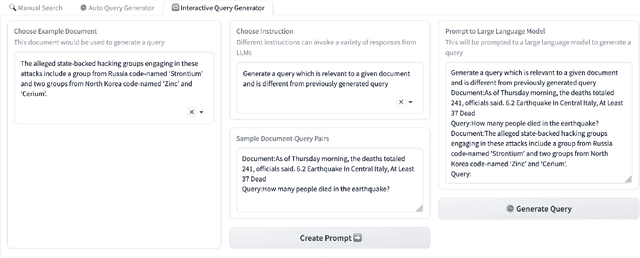
While search is the predominant method of accessing information, formulating effective queries remains a challenging task, especially for situations where the users are not familiar with a domain, or searching for documents in other languages, or looking for complex information such as events, which are not easily expressible as queries. Providing example documents or passages of interest, might be easier for a user, however, such query-by-example scenarios are prone to concept drift, and are highly sensitive to the query generation method. This demo illustrates complementary approaches of using LLMs interactively, assisting and enabling the user to provide edits and feedback at all stages of the query formulation process. The proposed Query Generation Assistant is a novel search interface which supports automatic and interactive query generation over a mono-linguial or multi-lingual document collection. Specifically, the proposed assistive interface enables the users to refine the queries generated by different LLMs, to provide feedback on the retrieved documents or passages, and is able to incorporate the users' feedback as prompts to generate more effective queries. The proposed interface is a valuable experimental tool for exploring fine-tuning and prompting of LLMs for query generation to qualitatively evaluate the effectiveness of retrieval and ranking models, and for conducting Human-in-the-Loop (HITL) experiments for complex search tasks where users struggle to formulate queries without such assistance.
C3: Continued Pretraining with Contrastive Weak Supervision for Cross Language Ad-Hoc Retrieval
Apr 25, 2022
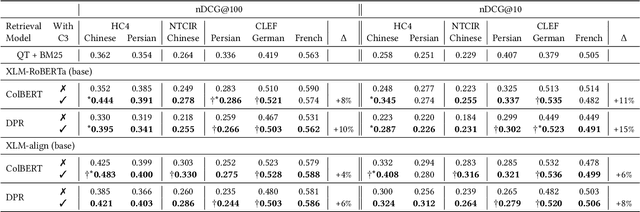
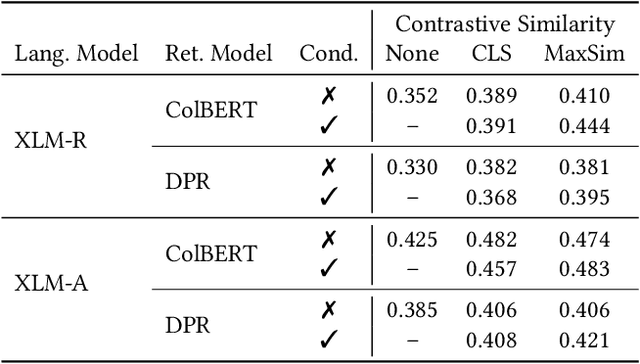
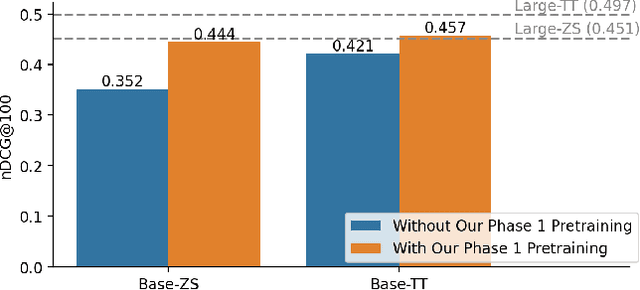
Pretrained language models have improved effectiveness on numerous tasks, including ad-hoc retrieval. Recent work has shown that continuing to pretrain a language model with auxiliary objectives before fine-tuning on the retrieval task can further improve retrieval effectiveness. Unlike monolingual retrieval, designing an appropriate auxiliary task for cross-language mappings is challenging. To address this challenge, we use comparable Wikipedia articles in different languages to further pretrain off-the-shelf multilingual pretrained models before fine-tuning on the retrieval task. We show that our approach yields improvements in retrieval effectiveness.