 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRubricRAG: Towards Interpretable and Reliable LLM Evaluation via Domain Knowledge Retrieval for Rubric Generation
Mar 21, 2026Large language models (LLMs) are increasingly evaluated and sometimes trained using automated graders such as LLM-as-judges that output scalar scores or preferences. While convenient, these approaches are often opaque: a single score rarely explains why an answer is good or bad, which requirements were missed, or how a system should be improved. This lack of interpretability limits their usefulness for model development, dataset curation, and high-stakes deployment. Query-specific rubric-based evaluation offers a more transparent alternative by decomposing quality into explicit, checkable criteria. However, manually designing high-quality, query-specific rubrics is labor-intensive and cognitively demanding and not feasible for deployment. While previous approaches have focused on generating intermediate rubrics for automated downstream evaluation, it is unclear if these rubrics are both interpretable and effective for human users. In this work, we investigate whether LLMs can generate useful, instance-specific rubrics as compared to human-authored rubrics, while also improving effectiveness for identifying good responses. Through our systematic study on two rubric benchmarks, and on multiple few-shot and post-training strategies, we find that off-the-shelf LLMs produce rubrics that are poorly aligned with human-authored ones. We introduce a simple strategy, RubricRAG, which retrieves domain knowledge via rubrics at inference time from related queries. We demonstrate that RubricRAG can generate more interpretable rubrics both for similarity to human-authored rubrics, and for improved downstream evaluation effectiveness. Our results highlight both the challenges and a promising approach of scalable, interpretable evaluation through automated rubric generation.
BabyReasoningBench: Generating Developmentally-Inspired Reasoning Tasks for Evaluating Baby Language Models
Jan 26, 2026Traditional evaluations of reasoning capabilities of language models are dominated by adult-centric benchmarks that presuppose broad world knowledge, complex instruction following, and mature pragmatic competence. These assumptions are mismatched to baby language models trained on developmentally plausible input such as child-directed speech and early-childhood narratives, and they obscure which reasoning abilities (if any) emerge under such constraints. We introduce BabyReasoningBench, a GPT-5.2 generated benchmark of 19 reasoning tasks grounded in classic paradigms from developmental psychology, spanning theory of mind, analogical and relational reasoning, causal inference and intervention selection, and core reasoning primitives that are known to be confounded by memory and pragmatics. We find that two GPT-2 based baby language models (pretrained on 10M and 100M of child-directed speech text) show overall low but uneven performance, with dissociations across task families: scaling improves several causal and physical reasoning tasks, while belief attribution and pragmatics-sensitive tasks remain challenging. BabyReasoningBench provides a developmentally grounded lens for analyzing what kinds of reasoning are supported by child-like training distributions, and for testing mechanistic hypotheses about how such abilities emerge.
Generative Product Recommendations for Implicit Superlative Queries
Apr 26, 2025In Recommender Systems, users often seek the best products through indirect, vague, or under-specified queries, such as "best shoes for trail running". Such queries, also referred to as implicit superlative queries, pose a significant challenge for standard retrieval and ranking systems as they lack an explicit mention of attributes and require identifying and reasoning over complex factors. We investigate how Large Language Models (LLMs) can generate implicit attributes for ranking as well as reason over them to improve product recommendations for such queries. As a first step, we propose a novel four-point schema for annotating the best product candidates for superlative queries called SUPERB, paired with LLM-based product annotations. We then empirically evaluate several existing retrieval and ranking approaches on our new dataset, providing insights and discussing their integration into real-world e-commerce production systems.
To Retrieve or Not to Retrieve? Uncertainty Detection for Dynamic Retrieval Augmented Generation
Jan 16, 2025Retrieval-Augmented Generation equips large language models with the capability to retrieve external knowledge, thereby mitigating hallucinations by incorporating information beyond the model's intrinsic abilities. However, most prior works have focused on invoking retrieval deterministically, which makes it unsuitable for tasks such as long-form question answering. Instead, dynamically performing retrieval by invoking it only when the underlying LLM lacks the required knowledge can be more efficient. In this context, we delve deeper into the question, "To Retrieve or Not to Retrieve?" by exploring multiple uncertainty detection methods. We evaluate these methods for the task of long-form question answering, employing dynamic retrieval, and present our comparisons. Our findings suggest that uncertainty detection metrics, such as Degree Matrix Jaccard and Eccentricity, can reduce the number of retrieval calls by almost half, with only a slight reduction in question-answering accuracy.
A Multi-Encoder Frozen-Decoder Approach for Fine-Tuning Large Language Models
Jan 14, 2025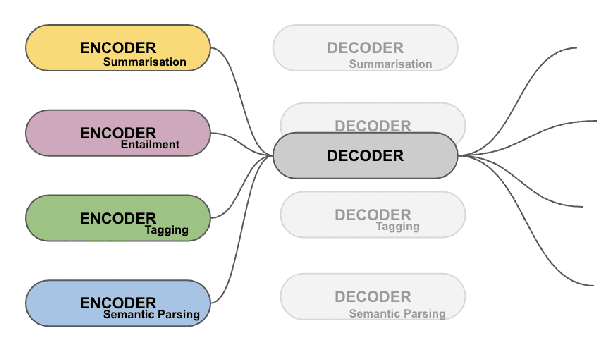
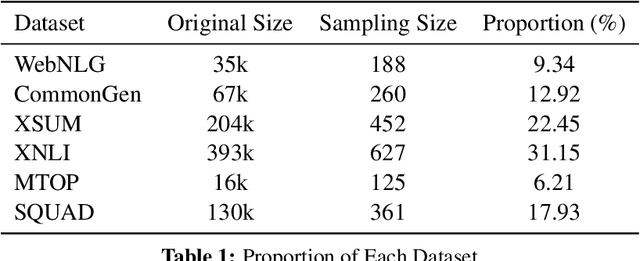
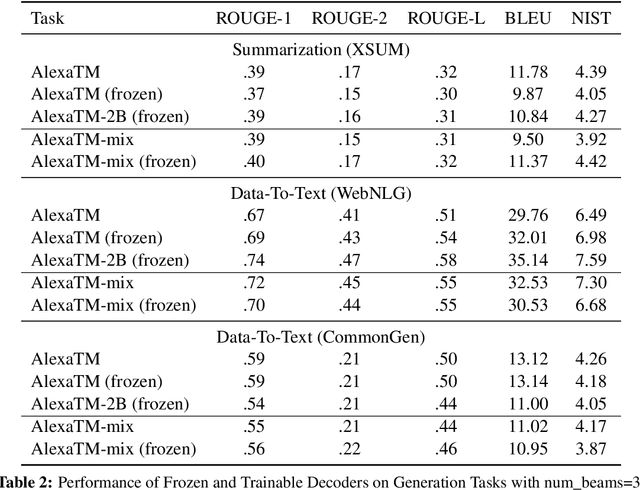
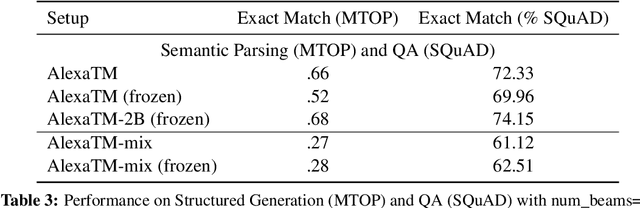
Among parameter-efficient fine-tuning methods, freezing has emerged as a popular strategy for speeding up training, reducing catastrophic forgetting, and improving downstream performance. We investigate the impact of freezing the decoder in a multi-task setup comprising diverse natural language tasks, aiming to reduce deployment overhead and enhance portability to novel tasks. Our experiments, conducted by fine-tuning both individual and multi-task setups on the AlexaTM model, reveal that freezing decoders is highly effective for tasks with natural language outputs and mitigates catastrophic forgetting in multilingual tasks. However, we find that pairing frozen decoders with a larger model can effectively maintain or even enhance performance in structured and QA tasks, making it a viable strategy for a broader range of task types.
ConQRet: Benchmarking Fine-Grained Evaluation of Retrieval Augmented Argumentation with LLM Judges
Dec 06, 2024Computational argumentation, which involves generating answers or summaries for controversial topics like abortion bans and vaccination, has become increasingly important in today's polarized environment. Sophisticated LLM capabilities offer the potential to provide nuanced, evidence-based answers to such questions through Retrieval-Augmented Argumentation (RAArg), leveraging real-world evidence for high-quality, grounded arguments. However, evaluating RAArg remains challenging, as human evaluation is costly and difficult for complex, lengthy answers on complicated topics. At the same time, re-using existing argumentation datasets is no longer sufficient, as they lack long, complex arguments and realistic evidence from potentially misleading sources, limiting holistic evaluation of retrieval effectiveness and argument quality. To address these gaps, we investigate automated evaluation methods using multiple fine-grained LLM judges, providing better and more interpretable assessments than traditional single-score metrics and even previously reported human crowdsourcing. To validate the proposed techniques, we introduce ConQRet, a new benchmark featuring long and complex human-authored arguments on debated topics, grounded in real-world websites, allowing an exhaustive evaluation across retrieval effectiveness, argument quality, and groundedness. We validate our LLM Judges on a prior dataset and the new ConQRet benchmark. Our proposed LLM Judges and the ConQRet benchmark can enable rapid progress in computational argumentation and can be naturally extended to other complex retrieval-augmented generation tasks.
PyTerrier-GenRank: The PyTerrier Plugin for Reranking with Large Language Models
Dec 06, 2024Using LLMs as rerankers requires experimenting with various hyperparameters, such as prompt formats, model choice, and reformulation strategies. We introduce PyTerrier-GenRank, a PyTerrier plugin to facilitate seamless reranking experiments with LLMs, supporting popular ranking strategies like pointwise and listwise prompting. We validate our plugin through HuggingFace and OpenAI hosted endpoints.
Generative Query Reformulation Using Ensemble Prompting, Document Fusion, and Relevance Feedback
May 27, 2024
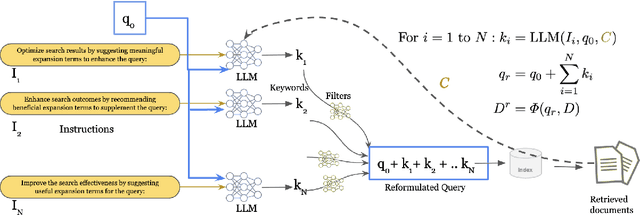
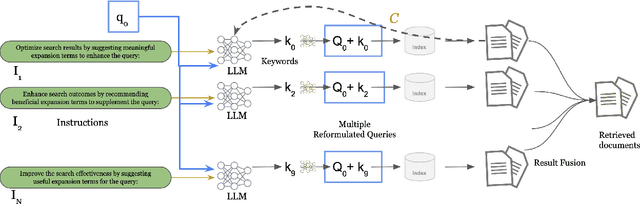
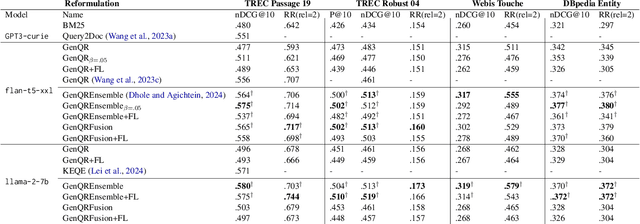
Query Reformulation (QR) is a set of techniques used to transform a user's original search query to a text that better aligns with the user's intent and improves their search experience. Recently, zero-shot QR has been a promising approach due to its ability to exploit knowledge inherent in large language models. Inspired by the success of ensemble prompting strategies which have benefited other tasks, we investigate if they can improve query reformulation. In this context, we propose two ensemble-based prompting techniques, GenQREnsemble and GenQRFusion which leverage paraphrases of a zero-shot instruction to generate multiple sets of keywords to improve retrieval performance ultimately. We further introduce their post-retrieval variants to incorporate relevance feedback from a variety of sources, including an oracle simulating a human user and a "critic" LLM. We demonstrate that an ensemble of query reformulations can improve retrieval effectiveness by up to 18% on nDCG@10 in pre-retrieval settings and 9% on post-retrieval settings on multiple benchmarks, outperforming all previously reported SOTA results. We perform subsequent analyses to investigate the effects of feedback documents, incorporate domain-specific instructions, filter reformulations, and generate fluent reformulations that might be more beneficial to human searchers. Together, the techniques and the results presented in this paper establish a new state of the art in automated query reformulation for retrieval and suggest promising directions for future research.
DUQGen: Effective Unsupervised Domain Adaptation of Neural Rankers by Diversifying Synthetic Query Generation
Apr 03, 2024State-of-the-art neural rankers pre-trained on large task-specific training data such as MS-MARCO, have been shown to exhibit strong performance on various ranking tasks without domain adaptation, also called zero-shot. However, zero-shot neural ranking may be sub-optimal, as it does not take advantage of the target domain information. Unfortunately, acquiring sufficiently large and high quality target training data to improve a modern neural ranker can be costly and time-consuming. To address this problem, we propose a new approach to unsupervised domain adaptation for ranking, DUQGen, which addresses a critical gap in prior literature, namely how to automatically generate both effective and diverse synthetic training data to fine tune a modern neural ranker for a new domain. Specifically, DUQGen produces a more effective representation of the target domain by identifying clusters of similar documents; and generates a more diverse training dataset by probabilistic sampling over the resulting document clusters. Our extensive experiments, over the standard BEIR collection, demonstrate that DUQGen consistently outperforms all zero-shot baselines and substantially outperforms the SOTA baselines on 16 out of 18 datasets, for an average of 4% relative improvement across all datasets. We complement our results with a thorough analysis for more in-depth understanding of the proposed method's performance and to identify promising areas for further improvements.
QueryExplorer: An Interactive Query Generation Assistant for Search and Exploration
Mar 23, 2024Formulating effective search queries remains a challenging task, particularly when users lack expertise in a specific domain or are not proficient in the language of the content. Providing example documents of interest might be easier for a user. However, such query-by-example scenarios are prone to concept drift, and the retrieval effectiveness is highly sensitive to the query generation method, without a clear way to incorporate user feedback. To enable exploration and to support Human-In-The-Loop experiments we propose QueryExplorer -- an interactive query generation, reformulation, and retrieval interface with support for HuggingFace generation models and PyTerrier's retrieval pipelines and datasets, and extensive logging of human feedback. To allow users to create and modify effective queries, our demo supports complementary approaches of using LLMs interactively, assisting the user with edits and feedback at multiple stages of the query formulation process. With support for recording fine-grained interactions and user annotations, QueryExplorer can serve as a valuable experimental and research platform for annotation, qualitative evaluation, and conducting Human-in-the-Loop (HITL) experiments for complex search tasks where users struggle to formulate queries.