 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-to-Distribution Prediction with Quantile Tokens and Neighbor Context
Apr 22, 2026Many applications of LLM-based text regression require predicting a full conditional distribution rather than a single point value. We study distributional regression under empirical-quantile supervision, where each input is paired with multiple observed quantile outcomes, and the target distribution is represented by a dense grid of quantiles. We address two key limitations of current approaches: the lack of local grounding for distribution estimates, and the reliance on shared representations that create an indirect bottleneck between inputs and quantile outputs. In this paper, we introduce Quantile Token Regression, which, to our knowledge, is the first work to insert dedicated quantile tokens into the input sequence, enabling direct input-output pathways for each quantile through self-attention. We further augment these quantile tokens with retrieval, incorporating semantically similar neighbor instances and their empirical distributions to ground predictions with local evidence from similar instances. We also provide the first theoretical analysis of loss functions for quantile regression, clarifying which distributional objectives each optimizes. Experiments on the Inside Airbnb and StackSample benchmark datasets with LLMs ranging from 1.7B to 14B parameters show that quantile tokens with neighbors consistently outperform baselines (~4 points lower MAPE and 2x narrower prediction intervals), with especially large gains on smaller and more challenging datasets where quantile tokens produce substantially sharper and more accurate distributions.
A Modular LLM Framework for Explainable Price Outlier Detection
Mar 21, 2026Detecting product price outliers is important for retail and e-commerce stores as erroneous or unexpectedly high prices adversely affect competitiveness, revenue, and consumer trust. Classical techniques offer simple thresholds while ignoring the rich semantic relationships among product attributes. We propose an agentic Large Language Model (LLM) framework that treats outlier price flagging as a reasoning task grounded in related product detection and comparison. The system processes the prices of target products in three stages: (i) relevance classification selects price-relevant similar products using product descriptions and attributes; (ii) relative utility assessment evaluates the target product against each similar product along price influencing dimensions (e.g., brand, size, features); (iii) reasoning-based decision aggregates these justifications into an explainable price outlier judgment. The framework attains over 75% agreement with human auditors on a test dataset, and outperforms zero-shot and retrieval based LLM techniques. Ablation studies show the sensitivity of the method to key hyper-parameters and testify on its flexibility to be applied to cases with different accuracy requirement and auditor agreements.
Hint-Augmented Re-ranking: Efficient Product Search using LLM-Based Query Decomposition
Nov 17, 2025Search queries with superlatives (e.g., best, most popular) require comparing candidates across multiple dimensions, demanding linguistic understanding and domain knowledge. We show that LLMs can uncover latent intent behind these expressions in e-commerce queries through a framework that extracts structured interpretations or hints. Our approach decomposes queries into attribute-value hints generated concurrently with retrieval, enabling efficient integration into the ranking pipeline. Our method improves search performanc eby 10.9 points in MAP and ranking by 5.9 points in MRR over baselines. Since direct LLM-based reranking faces prohibitive latency, we develop an efficient approach transferring superlative interpretations to lightweight models. Our findings provide insights into how superlative semantics can be represented and transferred between models, advancing linguistic interpretation in retrieval systems while addressing practical deployment constraints.
Quantile Regression with Large Language Models for Price Prediction
Jun 07, 2025Large Language Models (LLMs) have shown promise in structured prediction tasks, including regression, but existing approaches primarily focus on point estimates and lack systematic comparison across different methods. We investigate probabilistic regression using LLMs for unstructured inputs, addressing challenging text-to-distribution prediction tasks such as price estimation where both nuanced text understanding and uncertainty quantification are critical. We propose a novel quantile regression approach that enables LLMs to produce full predictive distributions, improving upon traditional point estimates. Through extensive experiments across three diverse price prediction datasets, we demonstrate that a Mistral-7B model fine-tuned with quantile heads significantly outperforms traditional approaches for both point and distributional estimations, as measured by three established metrics each for prediction accuracy and distributional calibration. Our systematic comparison of LLM approaches, model architectures, training approaches, and data scaling reveals that Mistral-7B consistently outperforms encoder architectures, embedding-based methods, and few-shot learning methods. Our experiments also reveal the effectiveness of LLM-assisted label correction in achieving human-level accuracy without systematic bias. Our curated datasets are made available at https://github.com/vnik18/llm-price-quantile-reg/ to support future research.
Generative Product Recommendations for Implicit Superlative Queries
Apr 26, 2025In Recommender Systems, users often seek the best products through indirect, vague, or under-specified queries, such as "best shoes for trail running". Such queries, also referred to as implicit superlative queries, pose a significant challenge for standard retrieval and ranking systems as they lack an explicit mention of attributes and require identifying and reasoning over complex factors. We investigate how Large Language Models (LLMs) can generate implicit attributes for ranking as well as reason over them to improve product recommendations for such queries. As a first step, we propose a novel four-point schema for annotating the best product candidates for superlative queries called SUPERB, paired with LLM-based product annotations. We then empirically evaluate several existing retrieval and ranking approaches on our new dataset, providing insights and discussing their integration into real-world e-commerce production systems.
Wizard of Shopping: Target-Oriented E-commerce Dialogue Generation with Decision Tree Branching
Feb 03, 2025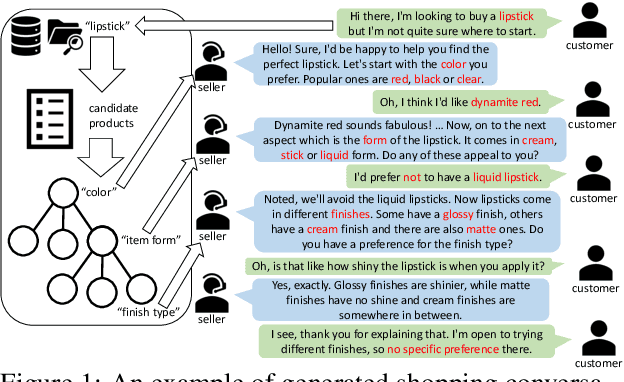

The goal of conversational product search (CPS) is to develop an intelligent, chat-based shopping assistant that can directly interact with customers to understand shopping intents, ask clarification questions, and find relevant products. However, training such assistants is hindered mainly due to the lack of reliable and large-scale datasets. Prior human-annotated CPS datasets are extremely small in size and lack integration with real-world product search systems. We propose a novel approach, TRACER, which leverages large language models (LLMs) to generate realistic and natural conversations for different shopping domains. TRACER's novelty lies in grounding the generation to dialogue plans, which are product search trajectories predicted from a decision tree model, that guarantees relevant product discovery in the shortest number of search conditions. We also release the first target-oriented CPS dataset Wizard of Shopping (WoS), containing highly natural and coherent conversations (3.6k) from three shopping domains. Finally, we demonstrate the quality and effectiveness of WoS via human evaluations and downstream tasks.
Generative Explore-Exploit: Training-free Optimization of Generative Recommender Systems using LLM Optimizers
Jun 07, 2024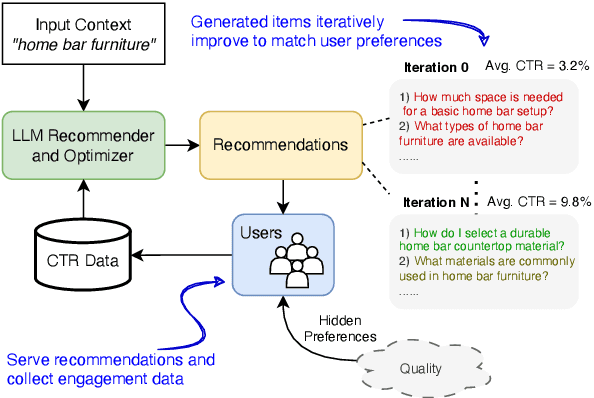



Recommender systems are widely used to suggest engaging content, and Large Language Models (LLMs) have given rise to generative recommenders. Such systems can directly generate items, including for open-set tasks like question suggestion. While the world knowledge of LLMs enable good recommendations, improving the generated content through user feedback is challenging as continuously fine-tuning LLMs is prohibitively expensive. We present a training-free approach for optimizing generative recommenders by connecting user feedback loops to LLM-based optimizers. We propose a generative explore-exploit method that can not only exploit generated items with known high engagement, but also actively explore and discover hidden population preferences to improve recommendation quality. We evaluate our approach on question generation in two domains (e-commerce and general knowledge), and model user feedback with Click Through Rate (CTR). Experiments show our LLM-based explore-exploit approach can iteratively improve recommendations, and consistently increase CTR. Ablation analysis shows that generative exploration is key to learning user preferences, avoiding the pitfalls of greedy exploit-only approaches. A human evaluation strongly supports our quantitative findings.
Question Suggestion for Conversational Shopping Assistants Using Product Metadata
May 02, 2024
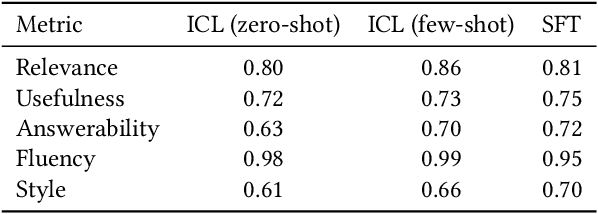
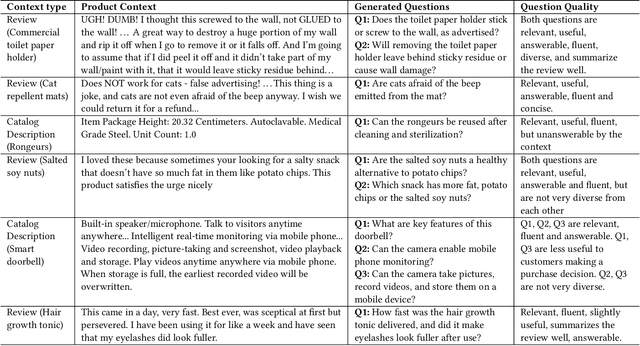
Digital assistants have become ubiquitous in e-commerce applications, following the recent advancements in Information Retrieval (IR), Natural Language Processing (NLP) and Generative Artificial Intelligence (AI). However, customers are often unsure or unaware of how to effectively converse with these assistants to meet their shopping needs. In this work, we emphasize the importance of providing customers a fast, easy to use, and natural way to interact with conversational shopping assistants. We propose a framework that employs Large Language Models (LLMs) to automatically generate contextual, useful, answerable, fluent and diverse questions about products, via in-context learning and supervised fine-tuning. Recommending these questions to customers as helpful suggestions or hints to both start and continue a conversation can result in a smoother and faster shopping experience with reduced conversation overhead and friction. We perform extensive offline evaluations, and discuss in detail about potential customer impact, and the type, length and latency of our generated product questions if incorporated into a real-world shopping assistant.
Leveraging Interesting Facts to Enhance User Engagement with Conversational Interfaces
Apr 09, 2024



Conversational Task Assistants (CTAs) guide users in performing a multitude of activities, such as making recipes. However, ensuring that interactions remain engaging, interesting, and enjoyable for CTA users is not trivial, especially for time-consuming or challenging tasks. Grounded in psychological theories of human interest, we propose to engage users with contextual and interesting statements or facts during interactions with a multi-modal CTA, to reduce fatigue and task abandonment before a task is complete. To operationalize this idea, we train a high-performing classifier (82% F1-score) to automatically identify relevant and interesting facts for users. We use it to create an annotated dataset of task-specific interesting facts for the domain of cooking. Finally, we design and validate a dialogue policy to incorporate the identified relevant and interesting facts into a conversation, to improve user engagement and task completion. Live testing on a leading multi-modal voice assistant shows that 66% of the presented facts were received positively, leading to a 40% gain in the user satisfaction rating, and a 37% increase in conversation length. These findings emphasize that strategically incorporating interesting facts into the CTA experience can promote real-world user participation for guided task interactions.
Instant Answering in E-Commerce Buyer-Seller Messaging using Message-to-Question Reformulation
Jan 30, 2024
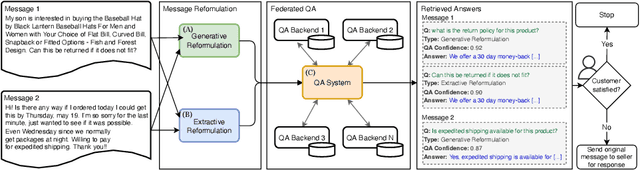
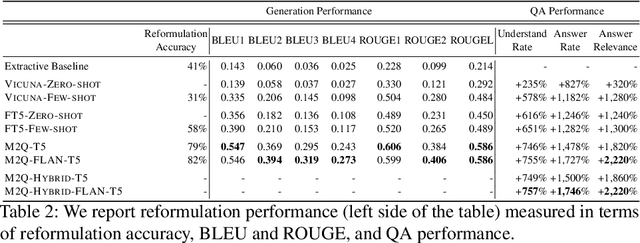
E-commerce customers frequently seek detailed product information for purchase decisions, commonly contacting sellers directly with extended queries. This manual response requirement imposes additional costs and disrupts buyer's shopping experience with response time fluctuations ranging from hours to days. We seek to automate buyer inquiries to sellers in a leading e-commerce store using a domain-specific federated Question Answering (QA) system. The main challenge is adapting current QA systems, designed for single questions, to address detailed customer queries. We address this with a low-latency, sequence-to-sequence approach, MESSAGE-TO-QUESTION ( M2Q ). It reformulates buyer messages into succinct questions by identifying and extracting the most salient information from a message. Evaluation against baselines shows that M2Q yields relative increases of 757% in question understanding, and 1,746% in answering rate from the federated QA system. Live deployment shows that automatic answering saves sellers from manually responding to millions of messages per year, and also accelerates customer purchase decisions by eliminating the need for buyers to wait for a reply