 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Open Intent Discovery for Conversational Text
Paper and Code
Apr 17, 2019
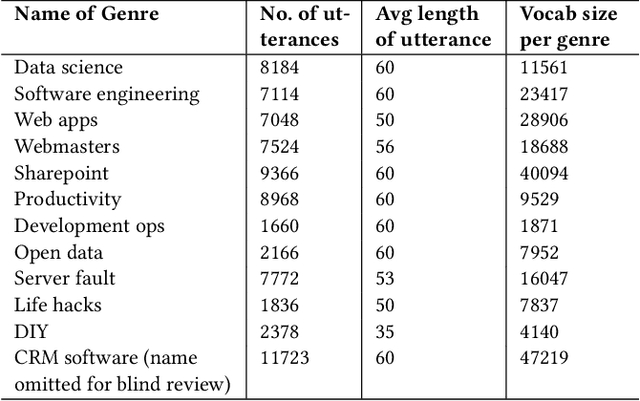
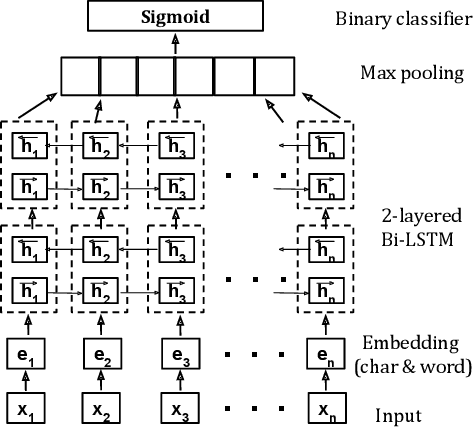

Detecting and identifying user intent from text, both written and spoken, plays an important role in modelling and understand dialogs. Existing research for intent discovery model it as a classification task with a predefined set of known categories. To generailze beyond these preexisting classes, we define a new task of \textit{open intent discovery}. We investigate how intent can be generalized to those not seen during training. To this end, we propose a two-stage approach to this task - predicting whether an utterance contains an intent, and then tagging the intent in the input utterance. Our model consists of a bidirectional LSTM with a CRF on top to capture contextual semantics, subject to some constraints. Self-attention is used to learn long distance dependencies. Further, we adapt an adversarial training approach to improve robustness and perforamce across domains. We also present a dataset of 25k real-life utterances that have been labelled via crowd sourcing. Our experiments across different domains and real-world datasets show the effectiveness of our approach, with less than 100 annotated examples needed per unique domain to recognize diverse intents. The approach outperforms state-of-the-art baselines by 5-15% F1 score points.