 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForking-Sequences
Oct 06, 2025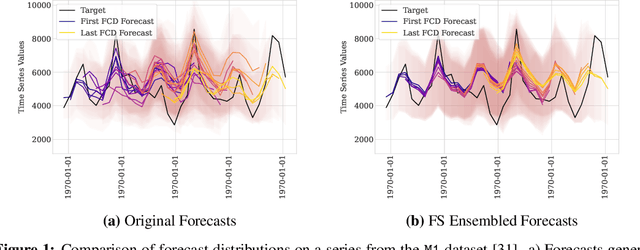
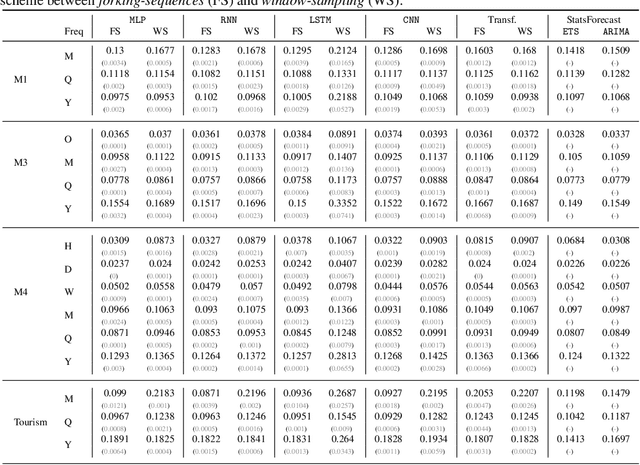
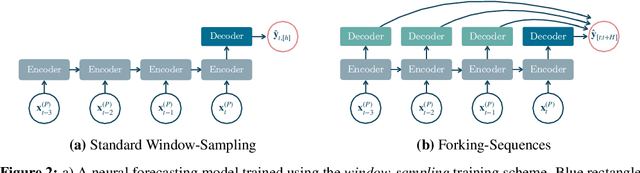
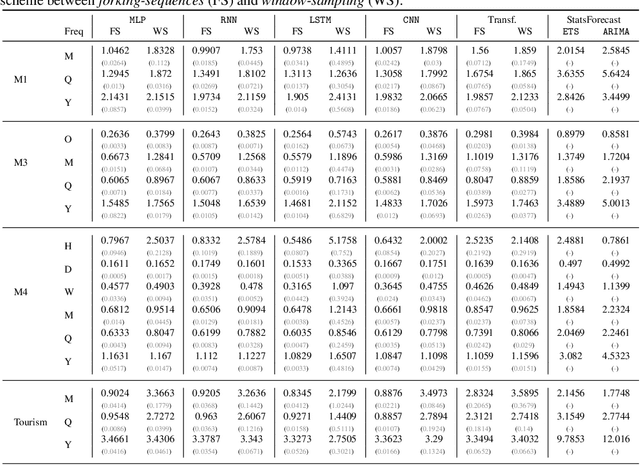
While accuracy is a critical requirement for time series forecasting models, an equally important (yet often overlooked) desideratum is forecast stability across forecast creation dates (FCDs). Even highly accurate models can produce erratic revisions between FCDs, undermining stakeholder trust and disrupting downstream decision-making. To improve forecast stability, models like MQCNN, MQT, and SPADE employ a little-known but highly effective technique: forking-sequences. Unlike standard statistical and neural forecasting methods that treat each FCD independently, the forking-sequences method jointly encodes and decodes the entire time series across all FCDs, in a way mirroring time series cross-validation. Since forking sequences remains largely unknown in the broader neural forecasting community, in this work, we formalize the forking-sequences approach, and we make a case for its broader adoption. We demonstrate three key benefits of forking-sequences: (i) more stable and consistent gradient updates during training; (ii) reduced forecast variance through ensembling; and (iii) improved inference computational efficiency. We validate forking-sequences' benefits using 16 datasets from the M1, M3, M4, and Tourism competitions, showing improvements in forecast percentage change stability of 28.8%, 28.8%, 37.9%, and 31.3%, and 8.8%, on average, for MLP, RNN, LSTM, CNN, and Transformer-based architectures, respectively.
Efficiently Generating Correlated Sample Paths from Multi-step Time Series Foundation Models
Oct 02, 2025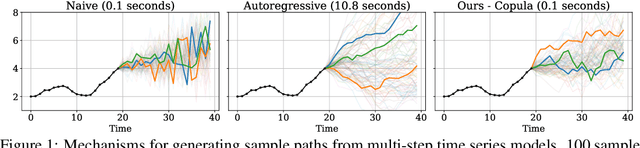
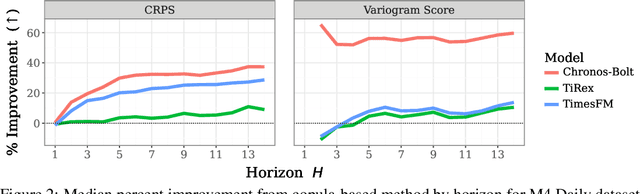
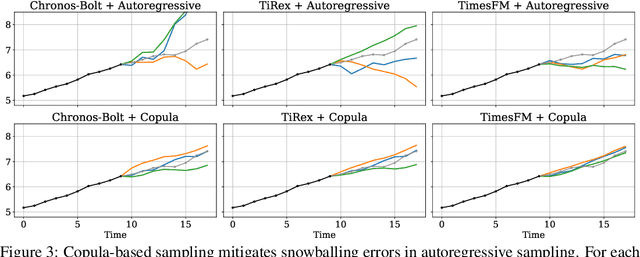
Many time series applications require access to multi-step forecast trajectories in the form of sample paths. Recently, time series foundation models have leveraged multi-step lookahead predictions to improve the quality and efficiency of multi-step forecasts. However, these models only predict independent marginal distributions for each time step, rather than a full joint predictive distribution. To generate forecast sample paths with realistic correlation structures, one typically resorts to autoregressive sampling, which can be extremely expensive. In this paper, we present a copula-based approach to efficiently generate accurate, correlated sample paths from existing multi-step time series foundation models in one forward pass. Our copula-based approach generates correlated sample paths orders of magnitude faster than autoregressive sampling, and it yields improved sample path quality by mitigating the snowballing error phenomenon.
Quantile Regression with Large Language Models for Price Prediction
Jun 07, 2025Large Language Models (LLMs) have shown promise in structured prediction tasks, including regression, but existing approaches primarily focus on point estimates and lack systematic comparison across different methods. We investigate probabilistic regression using LLMs for unstructured inputs, addressing challenging text-to-distribution prediction tasks such as price estimation where both nuanced text understanding and uncertainty quantification are critical. We propose a novel quantile regression approach that enables LLMs to produce full predictive distributions, improving upon traditional point estimates. Through extensive experiments across three diverse price prediction datasets, we demonstrate that a Mistral-7B model fine-tuned with quantile heads significantly outperforms traditional approaches for both point and distributional estimations, as measured by three established metrics each for prediction accuracy and distributional calibration. Our systematic comparison of LLM approaches, model architectures, training approaches, and data scaling reveals that Mistral-7B consistently outperforms encoder architectures, embedding-based methods, and few-shot learning methods. Our experiments also reveal the effectiveness of LLM-assisted label correction in achieving human-level accuracy without systematic bias. Our curated datasets are made available at https://github.com/vnik18/llm-price-quantile-reg/ to support future research.
$\spadesuit$ SPADE $\spadesuit$ Split Peak Attention DEcomposition
Nov 06, 2024Demand forecasting faces challenges induced by Peak Events (PEs) corresponding to special periods such as promotions and holidays. Peak events create significant spikes in demand followed by demand ramp down periods. Neural networks like MQCNN and MQT overreact to demand peaks by carrying over the elevated PE demand into subsequent Post-Peak-Event (PPE) periods, resulting in significantly over-biased forecasts. To tackle this challenge, we introduce a neural forecasting model called Split Peak Attention DEcomposition, SPADE. This model reduces the impact of PEs on subsequent forecasts by modeling forecasting as consisting of two separate tasks: one for PEs; and the other for the rest. Its architecture then uses masked convolution filters and a specialized Peak Attention module. We show SPADE's performance on a worldwide retail dataset with hundreds of millions of products. Our results reveal a reduction in PPE degradation by 4.5% and an improvement in PE accuracy by 3.9%, relative to current production models.
Online Posterior Sampling with a Diffusion Prior
Oct 04, 2024
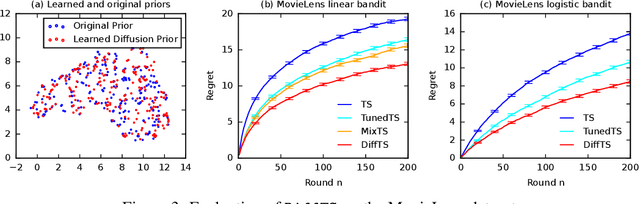


Posterior sampling in contextual bandits with a Gaussian prior can be implemented exactly or approximately using the Laplace approximation. The Gaussian prior is computationally efficient but it cannot describe complex distributions. In this work, we propose approximate posterior sampling algorithms for contextual bandits with a diffusion model prior. The key idea is to sample from a chain of approximate conditional posteriors, one for each stage of the reverse process, which are estimated in a closed form using the Laplace approximation. Our approximations are motivated by posterior sampling with a Gaussian prior, and inherit its simplicity and efficiency. They are asymptotically consistent and perform well empirically on a variety of contextual bandit problems.
DECoVaC: Design of Experiments with Controlled Variability Components
Sep 21, 2019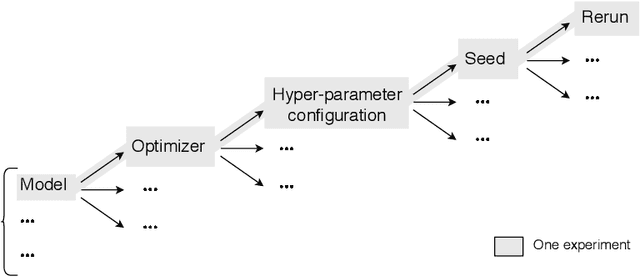
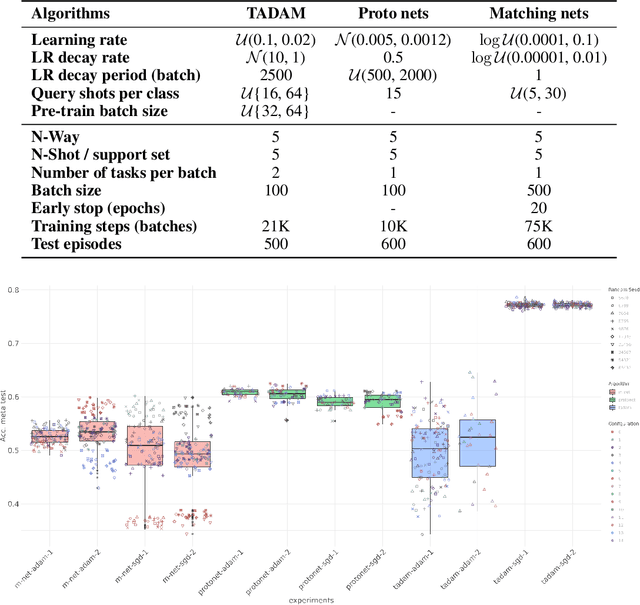

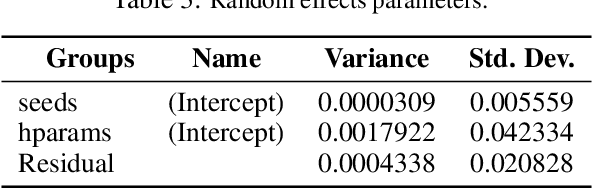
Reproducible research in Machine Learning has seen a salutary abundance of progress lately: workflows, transparency, and statistical analysis of validation and test performance. We build on these efforts and take them further. We offer a principled experimental design methodology, based on linear mixed models, to study and separate the effects of multiple factors of variation in machine learning experiments. This approach allows to account for the effects of architecture, optimizer, hyper-parameters, intentional randomization, as well as unintended lack of determinism across reruns. We illustrate that methodology by analyzing Matching Networks, Prototypical Networks and TADAM on the miniImagenet dataset.
Adaptive Masked Weight Imprinting for Few-Shot Segmentation
Feb 19, 2019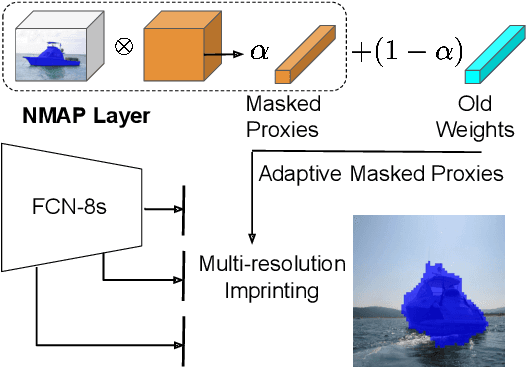



Deep learning has mainly thrived by training on large-scale datasets. However, for a continual learning agent it is critical to incrementally update its model in a sample efficient manner. Learning semantic segmentation from few labelled samples can be a significant step toward such goal. We propose a novel method that constructs the new class weights from few labelled samples in the support set without back-propagation, while updating the previously learned classes. Inspiring from the work on adaptive correlation filters, an adaptive masked imprinted weights method is designed. It utilizes a masked average pooling layer on the output embeddings and acts as a positive proxy for that class. Our proposed method is evaluated on PASCAL-5i dataset and outperforms the state of the art in the 5-shot semantic segmentation. Unlike previous methods, our proposed approach does not require a second branch to estimate parameters or prototypes, and enables the adaptation of previously learned weights. Our adaptation scheme is evaluated on DAVIS video segmentation benchmark and our proposed incremental version of PASCAL and has shown to outperform the baseline model.
Uncertainty in Multitask Transfer Learning
Jul 06, 2018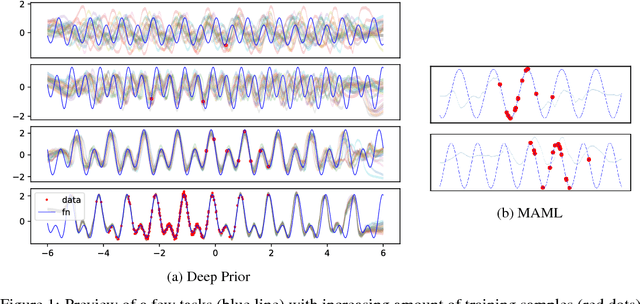
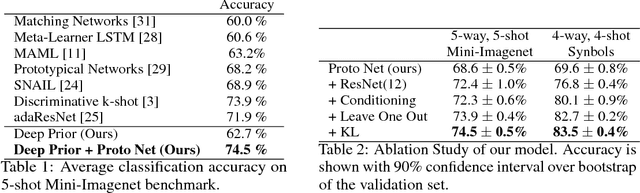
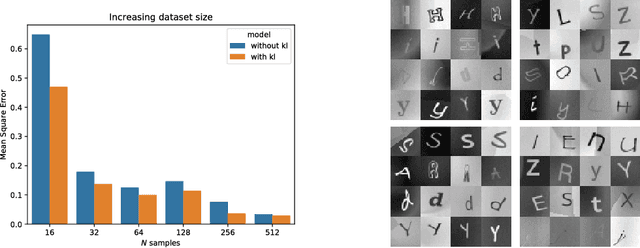
Using variational Bayes neural networks, we develop an algorithm capable of accumulating knowledge into a prior from multiple different tasks. The result is a rich and meaningful prior capable of few-shot learning on new tasks. The posterior can go beyond the mean field approximation and yields good uncertainty on the performed experiments. Analysis on toy tasks shows that it can learn from significantly different tasks while finding similarities among them. Experiments of Mini-Imagenet yields the new state of the art with 74.5% accuracy on 5 shot learning. Finally, we provide experiments showing that other existing methods can fail to perform well in different benchmarks.
Deep Prior
Dec 16, 2017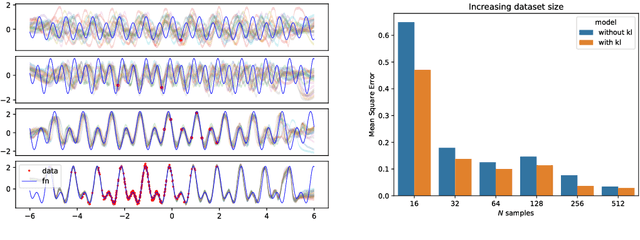
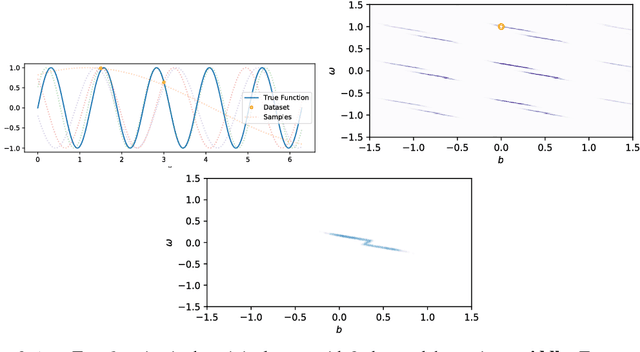
The recent literature on deep learning offers new tools to learn a rich probability distribution over high dimensional data such as images or sounds. In this work we investigate the possibility of learning the prior distribution over neural network parameters using such tools. Our resulting variational Bayes algorithm generalizes well to new tasks, even when very few training examples are provided. Furthermore, this learned prior allows the model to extrapolate correctly far from a given task's training data on a meta-dataset of periodic signals.
Greedy Gossip with Eavesdropping
Sep 09, 2009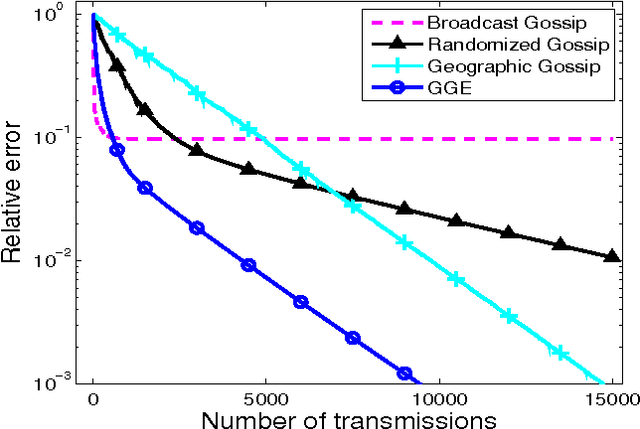



This paper presents greedy gossip with eavesdropping (GGE), a novel randomized gossip algorithm for distributed computation of the average consensus problem. In gossip algorithms, nodes in the network randomly communicate with their neighbors and exchange information iteratively. The algorithms are simple and decentralized, making them attractive for wireless network applications. In general, gossip algorithms are robust to unreliable wireless conditions and time varying network topologies. In this paper we introduce GGE and demonstrate that greedy updates lead to rapid convergence. We do not require nodes to have any location information. Instead, greedy updates are made possible by exploiting the broadcast nature of wireless communications. During the operation of GGE, when a node decides to gossip, instead of choosing one of its neighbors at random, it makes a greedy selection, choosing the node which has the value most different from its own. In order to make this selection, nodes need to know their neighbors' values. Therefore, we assume that all transmissions are wireless broadcasts and nodes keep track of their neighbors' values by eavesdropping on their communications. We show that the convergence of GGE is guaranteed for connected network topologies. We also study the rates of convergence and illustrate, through theoretical bounds and numerical simulations, that GGE consistently outperforms randomized gossip and performs comparably to geographic gossip on moderate-sized random geometric graph topologies.