 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime-Aware Prior Fitted Networks for Zero-Shot Forecasting with Exogenous Variables
Mar 16, 2026In many time series forecasting settings, the target time series is accompanied by exogenous covariates, such as promotions and prices in retail demand; temperature in energy load; calendar and holiday indicators for traffic or sales; and grid load or fuel costs in electricity pricing. Ignoring these exogenous signals can substantially degrade forecasting accuracy, particularly when they drive spikes, discontinuities, or regime and phase changes in the target series. Most current time series foundation models (e.g., Chronos, Sundial, TimesFM, TimeMoE, TimeLLM, and LagLlama) ignore exogenous covariates and make forecasts solely from the numerical time series history, thereby limiting their performance. In this paper, we develop ApolloPFN, a prior-data fitted network (PFN) that is time-aware (unlike prior PFNs) and that natively incorporates exogenous covariates (unlike prior univariate forecasters). Our design introduces two major advances: (i) a synthetic data generation procedure tailored to resolve the failure modes that arise when tabular (non-temporal) PFNs are applied to time series; and (ii) time-aware architectural modifications that embed inductive biases needed to exploit the time series context. We demonstrate that ApolloPFN achieves state-of-the-art results across benchmarks, such as M5 and electric price forecasting, that contain exogenous information.
Zero-shot Forecasting by Simulation Alone
Jan 02, 2026Zero-shot time-series forecasting holds great promise, but is still in its infancy, hindered by limited and biased data corpora, leakage-prone evaluation, and privacy and licensing constraints. Motivated by these challenges, we propose the first practical univariate time series simulation pipeline which is simultaneously fast enough for on-the-fly data generation and enables notable zero-shot forecasting performance on M-Series and GiftEval benchmarks that capture trend/seasonality/intermittency patterns, typical of industrial forecasting applications across a variety of domains. Our simulator, which we call SarSim0 (SARIMA Simulator for Zero-Shot Forecasting), is based off of a seasonal autoregressive integrated moving average (SARIMA) model as its core data source. Due to instability in the autoregressive component, naive SARIMA simulation often leads to unusable paths. Instead, we follow a three-step procedure: (1) we sample well-behaved trajectories from its characteristic polynomial stability region; (2) we introduce a superposition scheme that combines multiple paths into rich multi-seasonality traces; and (3) we add rate-based heavy-tailed noise models to capture burstiness and intermittency alongside seasonalities and trends. SarSim0 is orders of magnitude faster than kernel-based generators, and it enables training on circa 1B unique purely simulated series, generated on the fly; after which well-established neural network backbones exhibit strong zero-shot generalization, surpassing strong statistical forecasters and recent foundation baselines, while operating under strict zero-shot protocol. Notably, on GiftEval we observe a "student-beats-teacher" effect: models trained on our simulations exceed the forecasting accuracy of the AutoARIMA generating processes.
Forking-Sequences
Oct 06, 2025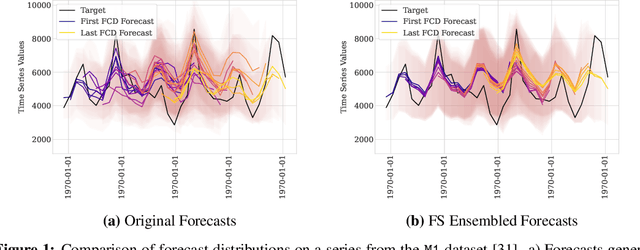
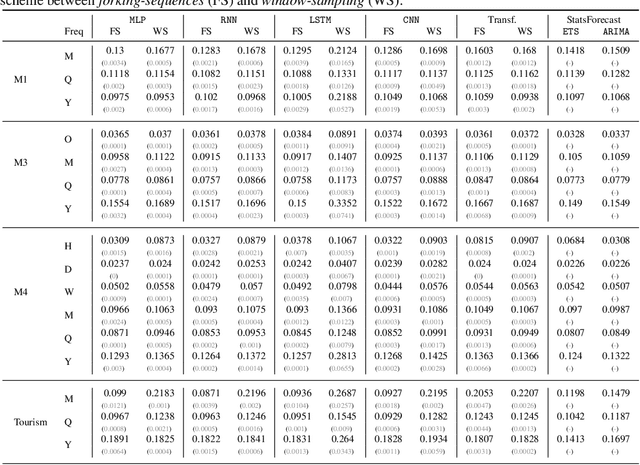
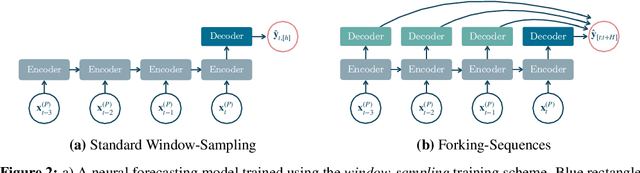
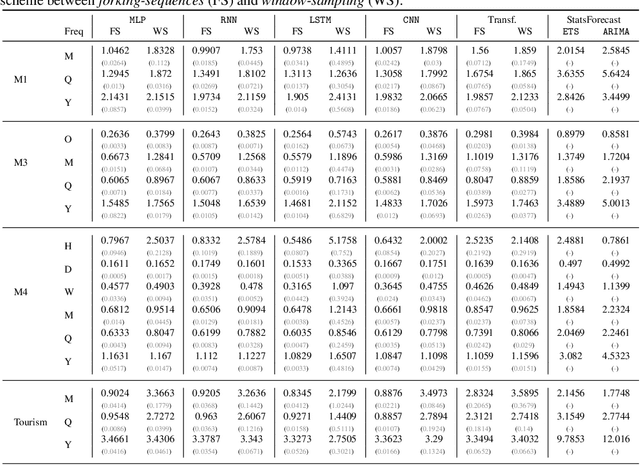
While accuracy is a critical requirement for time series forecasting models, an equally important (yet often overlooked) desideratum is forecast stability across forecast creation dates (FCDs). Even highly accurate models can produce erratic revisions between FCDs, undermining stakeholder trust and disrupting downstream decision-making. To improve forecast stability, models like MQCNN, MQT, and SPADE employ a little-known but highly effective technique: forking-sequences. Unlike standard statistical and neural forecasting methods that treat each FCD independently, the forking-sequences method jointly encodes and decodes the entire time series across all FCDs, in a way mirroring time series cross-validation. Since forking sequences remains largely unknown in the broader neural forecasting community, in this work, we formalize the forking-sequences approach, and we make a case for its broader adoption. We demonstrate three key benefits of forking-sequences: (i) more stable and consistent gradient updates during training; (ii) reduced forecast variance through ensembling; and (iii) improved inference computational efficiency. We validate forking-sequences' benefits using 16 datasets from the M1, M3, M4, and Tourism competitions, showing improvements in forecast percentage change stability of 28.8%, 28.8%, 37.9%, and 31.3%, and 8.8%, on average, for MLP, RNN, LSTM, CNN, and Transformer-based architectures, respectively.
LLMForecaster: Improving Seasonal Event Forecasts with Unstructured Textual Data
Dec 03, 2024



Modern time-series forecasting models often fail to make full use of rich unstructured information about the time series themselves. This lack of proper conditioning can lead to obvious model failures; for example, models may be unaware of the details of a particular product, and hence fail to anticipate seasonal surges in customer demand in the lead up to major exogenous events like holidays for clearly relevant products. To address this shortcoming, this paper introduces a novel forecast post-processor -- which we call LLMForecaster -- that fine-tunes large language models (LLMs) to incorporate unstructured semantic and contextual information and historical data to improve the forecasts from an existing demand forecasting pipeline. In an industry-scale retail application, we demonstrate that our technique yields statistically significantly forecast improvements across several sets of products subject to holiday-driven demand surges.
$\spadesuit$ SPADE $\spadesuit$ Split Peak Attention DEcomposition
Nov 06, 2024Demand forecasting faces challenges induced by Peak Events (PEs) corresponding to special periods such as promotions and holidays. Peak events create significant spikes in demand followed by demand ramp down periods. Neural networks like MQCNN and MQT overreact to demand peaks by carrying over the elevated PE demand into subsequent Post-Peak-Event (PPE) periods, resulting in significantly over-biased forecasts. To tackle this challenge, we introduce a neural forecasting model called Split Peak Attention DEcomposition, SPADE. This model reduces the impact of PEs on subsequent forecasts by modeling forecasting as consisting of two separate tasks: one for PEs; and the other for the rest. Its architecture then uses masked convolution filters and a specialized Peak Attention module. We show SPADE's performance on a worldwide retail dataset with hundreds of millions of products. Our results reveal a reduction in PPE degradation by 4.5% and an improvement in PE accuracy by 3.9%, relative to current production models.
Sequential Deep Learning for Credit Risk Monitoring with Tabular Financial Data
Dec 30, 2020



Machine learning plays an essential role in preventing financial losses in the banking industry. Perhaps the most pertinent prediction task that can result in billions of dollars in losses each year is the assessment of credit risk (i.e., the risk of default on debt). Today, much of the gains from machine learning to predict credit risk are driven by gradient boosted decision tree models. However, these gains begin to plateau without the addition of expensive new data sources or highly engineered features. In this paper, we present our attempts to create a novel approach to assessing credit risk using deep learning that does not rely on new model inputs. We propose a new credit card transaction sampling technique to use with deep recurrent and causal convolution-based neural networks that exploits long historical sequences of financial data without costly resource requirements. We show that our sequential deep learning approach using a temporal convolutional network outperformed the benchmark non-sequential tree-based model, achieving significant financial savings and earlier detection of credit risk. We also demonstrate the potential for our approach to be used in a production environment, where our sampling technique allows for sequences to be stored efficiently in memory and used for fast online learning and inference.
Using generative adversarial networks to synthesize artificial financial datasets
Feb 06, 2020



Generative Adversarial Networks (GANs) became very popular for generation of realistically looking images. In this paper, we propose to use GANs to synthesize artificial financial data for research and benchmarking purposes. We test this approach on three American Express datasets, and show that properly trained GANs can replicate these datasets with high fidelity. For our experiments, we define a novel type of GAN, and suggest methods for data preprocessing that allow good training and testing performance of GANs. We also discuss methods for evaluating the quality of generated data, and their comparison with the original real data.