 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$\spadesuit$ SPADE $\spadesuit$ Split Peak Attention DEcomposition
Nov 06, 2024Demand forecasting faces challenges induced by Peak Events (PEs) corresponding to special periods such as promotions and holidays. Peak events create significant spikes in demand followed by demand ramp down periods. Neural networks like MQCNN and MQT overreact to demand peaks by carrying over the elevated PE demand into subsequent Post-Peak-Event (PPE) periods, resulting in significantly over-biased forecasts. To tackle this challenge, we introduce a neural forecasting model called Split Peak Attention DEcomposition, SPADE. This model reduces the impact of PEs on subsequent forecasts by modeling forecasting as consisting of two separate tasks: one for PEs; and the other for the rest. Its architecture then uses masked convolution filters and a specialized Peak Attention module. We show SPADE's performance on a worldwide retail dataset with hundreds of millions of products. Our results reveal a reduction in PPE degradation by 4.5% and an improvement in PE accuracy by 3.9%, relative to current production models.
F-FOMAML: GNN-Enhanced Meta-Learning for Peak Period Demand Forecasting with Proxy Data
Jun 23, 2024Demand prediction is a crucial task for e-commerce and physical retail businesses, especially during high-stake sales events. However, the limited availability of historical data from these peak periods poses a significant challenge for traditional forecasting methods. In this paper, we propose a novel approach that leverages strategically chosen proxy data reflective of potential sales patterns from similar entities during non-peak periods, enriched by features learned from a graph neural networks (GNNs)-based forecasting model, to predict demand during peak events. We formulate the demand prediction as a meta-learning problem and develop the Feature-based First-Order Model-Agnostic Meta-Learning (F-FOMAML) algorithm that leverages proxy data from non-peak periods and GNN-generated relational metadata to learn feature-specific layer parameters, thereby adapting to demand forecasts for peak events. Theoretically, we show that by considering domain similarities through task-specific metadata, our model achieves improved generalization, where the excess risk decreases as the number of training tasks increases. Empirical evaluations on large-scale industrial datasets demonstrate the superiority of our approach. Compared to existing state-of-the-art models, our method demonstrates a notable improvement in demand prediction accuracy, reducing the Mean Absolute Error by 26.24% on an internal vending machine dataset and by 1.04% on the publicly accessible JD.com dataset.
GEANN: Scalable Graph Augmentations for Multi-Horizon Time Series Forecasting
Jul 07, 2023Encoder-decoder deep neural networks have been increasingly studied for multi-horizon time series forecasting, especially in real-world applications. However, to forecast accurately, these sophisticated models typically rely on a large number of time series examples with substantial history. A rapidly growing topic of interest is forecasting time series which lack sufficient historical data -- often referred to as the ``cold start'' problem. In this paper, we introduce a novel yet simple method to address this problem by leveraging graph neural networks (GNNs) as a data augmentation for enhancing the encoder used by such forecasters. These GNN-based features can capture complex inter-series relationships, and their generation process can be optimized end-to-end with the forecasting task. We show that our architecture can use either data-driven or domain knowledge-defined graphs, scaling to incorporate information from multiple very large graphs with millions of nodes. In our target application of demand forecasting for a large e-commerce retailer, we demonstrate on both a small dataset of 100K products and a large dataset with over 2 million products that our method improves overall performance over competitive baseline models. More importantly, we show that it brings substantially more gains to ``cold start'' products such as those newly launched or recently out-of-stock.
MQRetNN: Multi-Horizon Time Series Forecasting with Retrieval Augmentation
Jul 21, 2022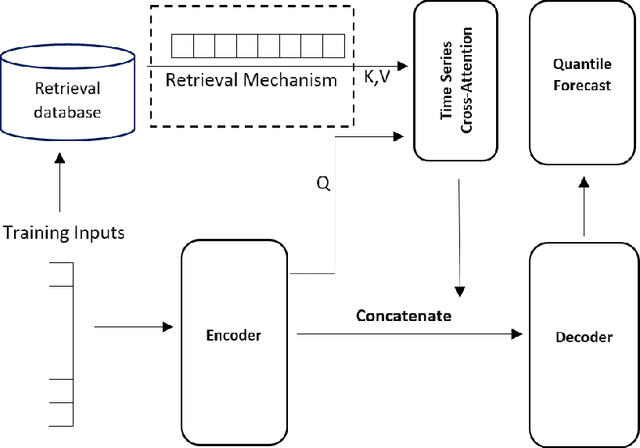
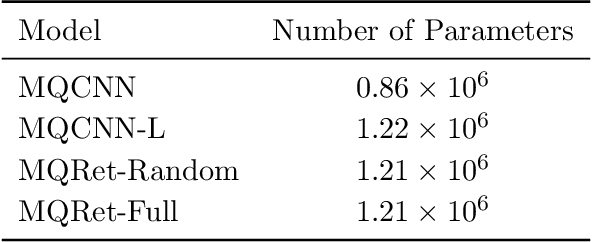
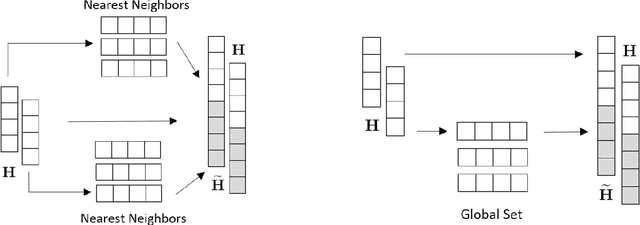
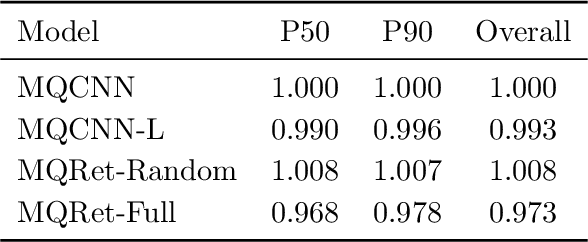
Multi-horizon probabilistic time series forecasting has wide applicability to real-world tasks such as demand forecasting. Recent work in neural time-series forecasting mainly focus on the use of Seq2Seq architectures. For example, MQTransformer - an improvement of MQCNN - has shown the state-of-the-art performance in probabilistic demand forecasting. In this paper, we consider incorporating cross-entity information to enhance model performance by adding a cross-entity attention mechanism along with a retrieval mechanism to select which entities to attend over. We demonstrate how our new neural architecture, MQRetNN, leverages the encoded contexts from a pretrained baseline model on the entire population to improve forecasting accuracy. Using MQCNN as the baseline model (due to computational constraints, we do not use MQTransformer), we first show on a small demand forecasting dataset that it is possible to achieve ~3% improvement in test loss by adding a cross-entity attention mechanism where each entity attends to all others in the population. We then evaluate the model with our proposed retrieval methods - as a means of approximating an attention over a large population - on a large-scale demand forecasting application with over 2 million products and observe ~1% performance gain over the MQCNN baseline.