 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime-Aware Prior Fitted Networks for Zero-Shot Forecasting with Exogenous Variables
Mar 16, 2026In many time series forecasting settings, the target time series is accompanied by exogenous covariates, such as promotions and prices in retail demand; temperature in energy load; calendar and holiday indicators for traffic or sales; and grid load or fuel costs in electricity pricing. Ignoring these exogenous signals can substantially degrade forecasting accuracy, particularly when they drive spikes, discontinuities, or regime and phase changes in the target series. Most current time series foundation models (e.g., Chronos, Sundial, TimesFM, TimeMoE, TimeLLM, and LagLlama) ignore exogenous covariates and make forecasts solely from the numerical time series history, thereby limiting their performance. In this paper, we develop ApolloPFN, a prior-data fitted network (PFN) that is time-aware (unlike prior PFNs) and that natively incorporates exogenous covariates (unlike prior univariate forecasters). Our design introduces two major advances: (i) a synthetic data generation procedure tailored to resolve the failure modes that arise when tabular (non-temporal) PFNs are applied to time series; and (ii) time-aware architectural modifications that embed inductive biases needed to exploit the time series context. We demonstrate that ApolloPFN achieves state-of-the-art results across benchmarks, such as M5 and electric price forecasting, that contain exogenous information.
Zero-shot Forecasting by Simulation Alone
Jan 02, 2026Zero-shot time-series forecasting holds great promise, but is still in its infancy, hindered by limited and biased data corpora, leakage-prone evaluation, and privacy and licensing constraints. Motivated by these challenges, we propose the first practical univariate time series simulation pipeline which is simultaneously fast enough for on-the-fly data generation and enables notable zero-shot forecasting performance on M-Series and GiftEval benchmarks that capture trend/seasonality/intermittency patterns, typical of industrial forecasting applications across a variety of domains. Our simulator, which we call SarSim0 (SARIMA Simulator for Zero-Shot Forecasting), is based off of a seasonal autoregressive integrated moving average (SARIMA) model as its core data source. Due to instability in the autoregressive component, naive SARIMA simulation often leads to unusable paths. Instead, we follow a three-step procedure: (1) we sample well-behaved trajectories from its characteristic polynomial stability region; (2) we introduce a superposition scheme that combines multiple paths into rich multi-seasonality traces; and (3) we add rate-based heavy-tailed noise models to capture burstiness and intermittency alongside seasonalities and trends. SarSim0 is orders of magnitude faster than kernel-based generators, and it enables training on circa 1B unique purely simulated series, generated on the fly; after which well-established neural network backbones exhibit strong zero-shot generalization, surpassing strong statistical forecasters and recent foundation baselines, while operating under strict zero-shot protocol. Notably, on GiftEval we observe a "student-beats-teacher" effect: models trained on our simulations exceed the forecasting accuracy of the AutoARIMA generating processes.
Forking-Sequences
Oct 06, 2025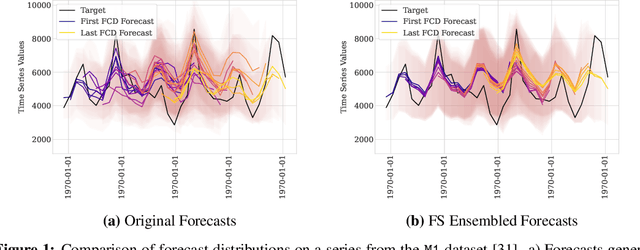
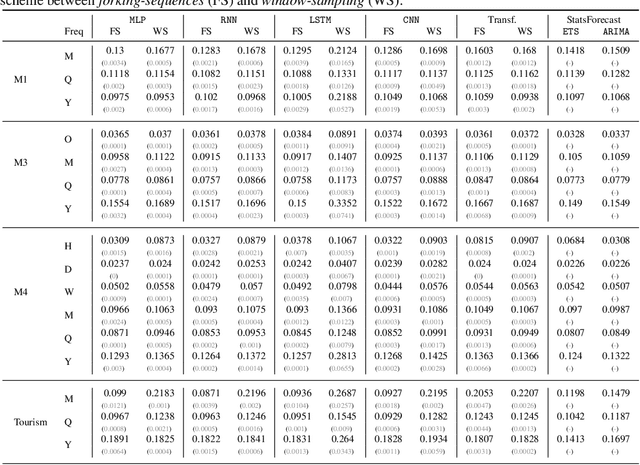
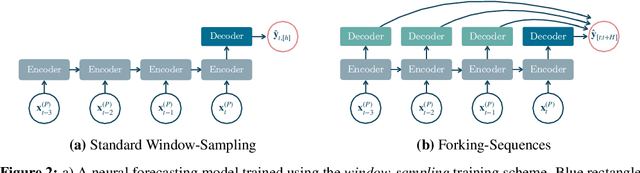
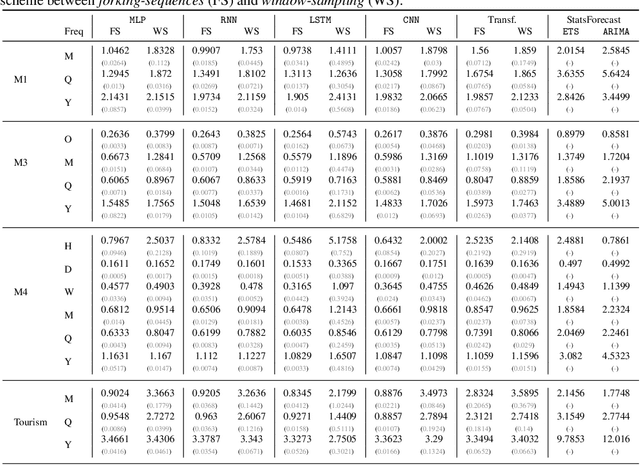
While accuracy is a critical requirement for time series forecasting models, an equally important (yet often overlooked) desideratum is forecast stability across forecast creation dates (FCDs). Even highly accurate models can produce erratic revisions between FCDs, undermining stakeholder trust and disrupting downstream decision-making. To improve forecast stability, models like MQCNN, MQT, and SPADE employ a little-known but highly effective technique: forking-sequences. Unlike standard statistical and neural forecasting methods that treat each FCD independently, the forking-sequences method jointly encodes and decodes the entire time series across all FCDs, in a way mirroring time series cross-validation. Since forking sequences remains largely unknown in the broader neural forecasting community, in this work, we formalize the forking-sequences approach, and we make a case for its broader adoption. We demonstrate three key benefits of forking-sequences: (i) more stable and consistent gradient updates during training; (ii) reduced forecast variance through ensembling; and (iii) improved inference computational efficiency. We validate forking-sequences' benefits using 16 datasets from the M1, M3, M4, and Tourism competitions, showing improvements in forecast percentage change stability of 28.8%, 28.8%, 37.9%, and 31.3%, and 8.8%, on average, for MLP, RNN, LSTM, CNN, and Transformer-based architectures, respectively.
Investigating Compositional Reasoning in Time Series Foundation Models
Feb 09, 2025



Large pre-trained time series foundation models (TSFMs) have demonstrated promising zero-shot performance across a wide range of domains. However, a question remains: Do TSFMs succeed solely by memorizing training patterns, or do they possess the ability to reason? While reasoning is a topic of great interest in the study of Large Language Models (LLMs), it is undefined and largely unexplored in the context of TSFMs. In this work, inspired by language modeling literature, we formally define compositional reasoning in forecasting and distinguish it from in-distribution generalization. We evaluate the reasoning and generalization capabilities of 23 popular deep learning forecasting models on multiple synthetic and real-world datasets. Additionally, through controlled studies, we systematically examine which design choices in TSFMs contribute to improved reasoning abilities. Our study yields key insights into the impact of TSFM architecture design on compositional reasoning and generalization. We find that patch-based Transformers have the best reasoning performance, closely followed by residualized MLP-based architectures, which are 97\% less computationally complex in terms of FLOPs and 86\% smaller in terms of the number of trainable parameters. Interestingly, in some zero-shot out-of-distribution scenarios, these models can outperform moving average and exponential smoothing statistical baselines trained on in-distribution data. Only a few design choices, such as the tokenization method, had a significant (negative) impact on Transformer model performance.
$\spadesuit$ SPADE $\spadesuit$ Split Peak Attention DEcomposition
Nov 06, 2024Demand forecasting faces challenges induced by Peak Events (PEs) corresponding to special periods such as promotions and holidays. Peak events create significant spikes in demand followed by demand ramp down periods. Neural networks like MQCNN and MQT overreact to demand peaks by carrying over the elevated PE demand into subsequent Post-Peak-Event (PPE) periods, resulting in significantly over-biased forecasts. To tackle this challenge, we introduce a neural forecasting model called Split Peak Attention DEcomposition, SPADE. This model reduces the impact of PEs on subsequent forecasts by modeling forecasting as consisting of two separate tasks: one for PEs; and the other for the rest. Its architecture then uses masked convolution filters and a specialized Peak Attention module. We show SPADE's performance on a worldwide retail dataset with hundreds of millions of products. Our results reveal a reduction in PPE degradation by 4.5% and an improvement in PE accuracy by 3.9%, relative to current production models.
Forecasting Response to Treatment with Deep Learning and Pharmacokinetic Priors
Sep 22, 2023Forecasting healthcare time series is crucial for early detection of adverse outcomes and for patient monitoring. Forecasting, however, can be difficult in practice due to noisy and intermittent data. The challenges are often exacerbated by change points induced via extrinsic factors, such as the administration of medication. We propose a novel encoder that informs deep learning models of the pharmacokinetic effects of drugs to allow for accurate forecasting of time series affected by treatment. We showcase the effectiveness of our approach in a task to forecast blood glucose using both realistically simulated and real-world data. Our pharmacokinetic encoder helps deep learning models surpass baselines by approximately 11% on simulated data and 8% on real-world data. The proposed approach can have multiple beneficial applications in clinical practice, such as issuing early warnings about unexpected treatment responses, or helping to characterize patient-specific treatment effects in terms of drug absorption and elimination characteristics.
HINT: Hierarchical Mixture Networks For Coherent Probabilistic Forecasting
May 11, 2023



We present the Hierarchical Mixture Networks (HINT), a model family for efficient and accurate coherent forecasting. We specialize the networks on the task via a multivariate mixture optimized with composite likelihood and made coherent via bootstrap reconciliation. Additionally, we robustify the networks to stark time series scale variations, incorporating normalized feature extraction and recomposition of output scales within their architecture. We demonstrate 8% sCRPS improved accuracy across five datasets compared to the existing state-of-the-art. We conduct ablation studies on our model's components and extensively investigate the theoretical properties of the multivariate mixture. HINT's code is available at this https://github.com/Nixtla/neuralforecast.
HierarchicalForecast: A Python Benchmarking Framework for Hierarchical Forecasting
Jul 07, 2022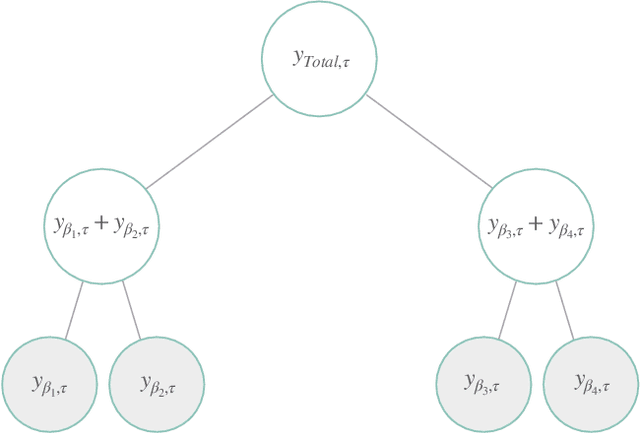
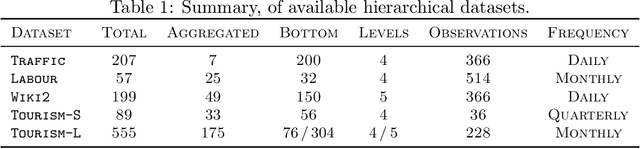
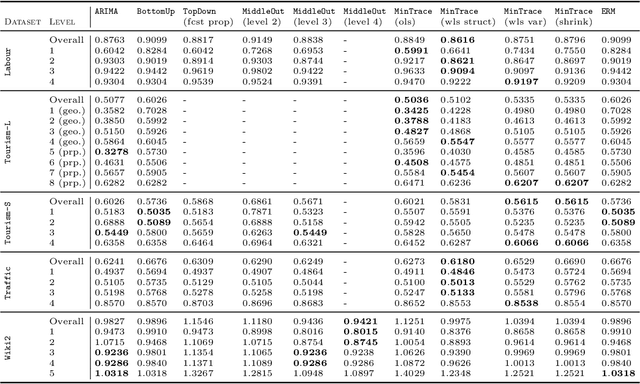
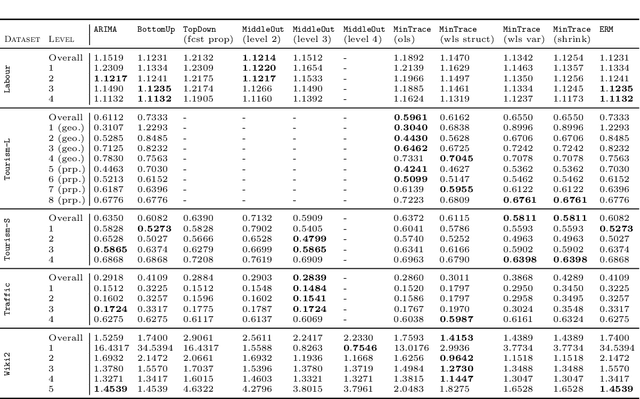
Large collections of time series data are commonly organized into cross-sectional structures with different levels of aggregation; examples include product and geographical groupings. A necessary condition for coherent decision-making and planning, with such data sets, is for the dis-aggregated series' forecasts to add up exactly to the aggregated series forecasts, which motivates the creation of novel hierarchical forecasting algorithms. The growing interest of the Machine Learning community in cross-sectional hierarchical forecasting systems states that we are in a propitious moment to ensure that scientific endeavors are grounded on sound baselines. For this reason, we put forward the HierarchicalForecast library, which contains preprocessed publicly available datasets, evaluation metrics, and a compiled set of statistical baseline models. Our Python-based framework aims to bridge the gap between statistical, econometric modeling, and Machine Learning forecasting research. Code and documentation are available in https://github.com/Nixtla/hierarchicalforecast.
N-HiTS: Neural Hierarchical Interpolation for Time Series Forecasting
Feb 02, 2022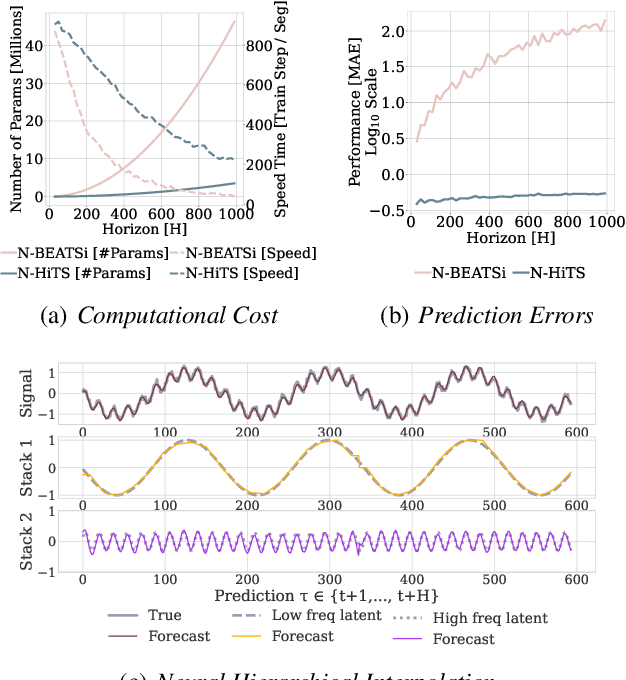

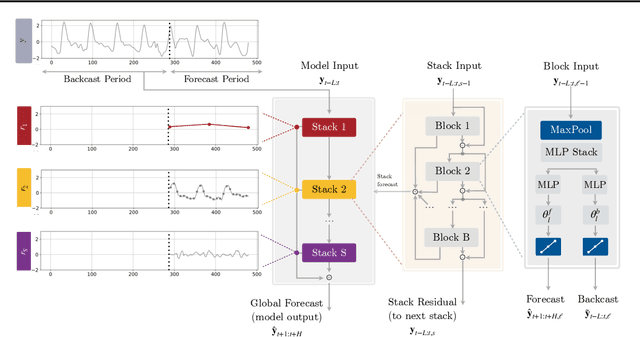
Recent progress in neural forecasting accelerated improvements in the performance of large-scale forecasting systems. Yet, long-horizon forecasting remains a very difficult task. Two common challenges afflicting long-horizon forecasting are the volatility of the predictions and their computational complexity. In this paper, we introduce N-HiTS, a model which addresses both challenges by incorporating novel hierarchical interpolation and multi-rate data sampling techniques. These techniques enable the proposed method to assemble its predictions sequentially, selectively emphasizing components with different frequencies and scales, while decomposing the input signal and synthesizing the forecast. We conduct an extensive empirical evaluation demonstrating the advantages of N-HiTS over the state-of-the-art long-horizon forecasting methods. On an array of multivariate forecasting tasks, the proposed method provides an average accuracy improvement of 25% over the latest Transformer architectures while reducing the computation time by an order of magnitude. Our code is available at https://github.com/cchallu/n-hits.
Probabilistic Hierarchical Forecasting with Deep Poisson Mixtures
Oct 29, 2021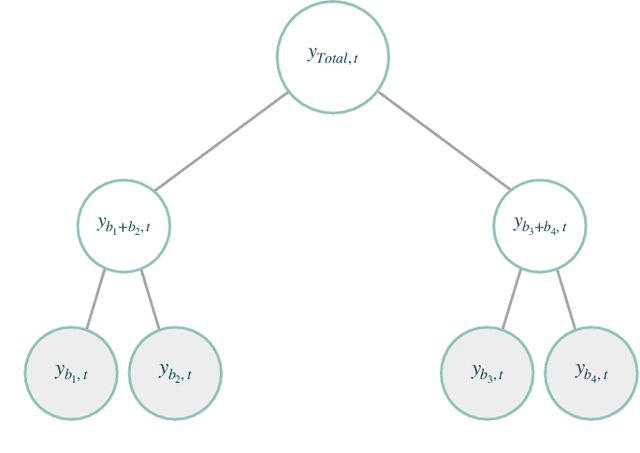
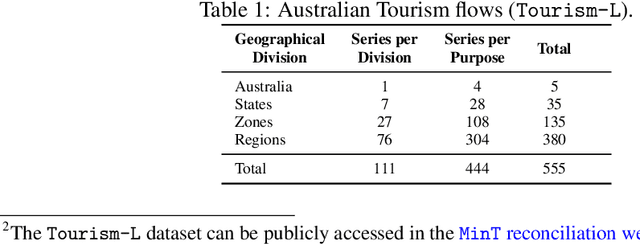
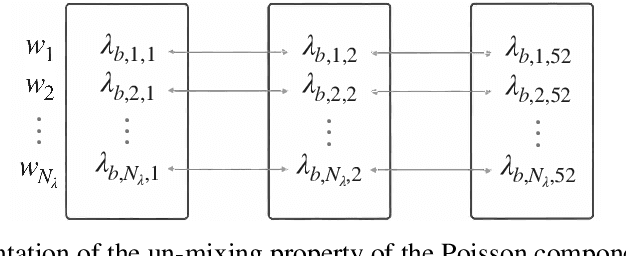
Hierarchical forecasting problems arise when time series compose a group structure that naturally defines aggregation and disaggregation coherence constraints for the predictions. In this work, we explore a new forecast representation, the Poisson Mixture Mesh (PMM), that can produce probabilistic, coherent predictions; it is compatible with the neural forecasting innovations, and defines simple aggregation and disaggregation rules capable of accommodating hierarchical structures, unknown during its optimization. We performed an empirical evaluation to compare the PMM to other hierarchical forecasting methods on Australian domestic tourism data, where we obtain a 20 percent relative improvement.