 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Compositional Reasoning in Time Series Foundation Models
Feb 09, 2025



Large pre-trained time series foundation models (TSFMs) have demonstrated promising zero-shot performance across a wide range of domains. However, a question remains: Do TSFMs succeed solely by memorizing training patterns, or do they possess the ability to reason? While reasoning is a topic of great interest in the study of Large Language Models (LLMs), it is undefined and largely unexplored in the context of TSFMs. In this work, inspired by language modeling literature, we formally define compositional reasoning in forecasting and distinguish it from in-distribution generalization. We evaluate the reasoning and generalization capabilities of 23 popular deep learning forecasting models on multiple synthetic and real-world datasets. Additionally, through controlled studies, we systematically examine which design choices in TSFMs contribute to improved reasoning abilities. Our study yields key insights into the impact of TSFM architecture design on compositional reasoning and generalization. We find that patch-based Transformers have the best reasoning performance, closely followed by residualized MLP-based architectures, which are 97\% less computationally complex in terms of FLOPs and 86\% smaller in terms of the number of trainable parameters. Interestingly, in some zero-shot out-of-distribution scenarios, these models can outperform moving average and exponential smoothing statistical baselines trained on in-distribution data. Only a few design choices, such as the tokenization method, had a significant (negative) impact on Transformer model performance.
Implicit Reasoning in Deep Time Series Forecasting
Sep 18, 2024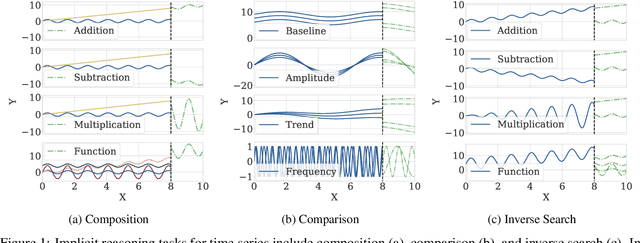

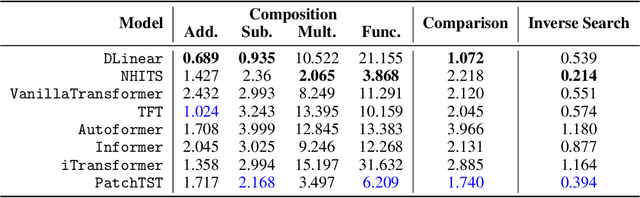
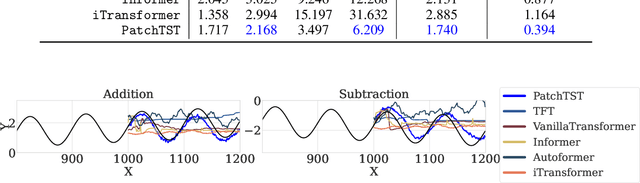
Recently, time series foundation models have shown promising zero-shot forecasting performance on time series from a wide range of domains. However, it remains unclear whether their success stems from a true understanding of temporal dynamics or simply from memorizing the training data. While implicit reasoning in language models has been studied, similar evaluations for time series models have been largely unexplored. This work takes an initial step toward assessing the reasoning abilities of deep time series forecasting models. We find that certain linear, MLP-based, and patch-based Transformer models generalize effectively in systematically orchestrated out-of-distribution scenarios, suggesting underexplored reasoning capabilities beyond simple pattern memorization.
Forecasting Response to Treatment with Deep Learning and Pharmacokinetic Priors
Sep 22, 2023Forecasting healthcare time series is crucial for early detection of adverse outcomes and for patient monitoring. Forecasting, however, can be difficult in practice due to noisy and intermittent data. The challenges are often exacerbated by change points induced via extrinsic factors, such as the administration of medication. We propose a novel encoder that informs deep learning models of the pharmacokinetic effects of drugs to allow for accurate forecasting of time series affected by treatment. We showcase the effectiveness of our approach in a task to forecast blood glucose using both realistically simulated and real-world data. Our pharmacokinetic encoder helps deep learning models surpass baselines by approximately 11% on simulated data and 8% on real-world data. The proposed approach can have multiple beneficial applications in clinical practice, such as issuing early warnings about unexpected treatment responses, or helping to characterize patient-specific treatment effects in terms of drug absorption and elimination characteristics.
HINT: Hierarchical Mixture Networks For Coherent Probabilistic Forecasting
May 11, 2023



We present the Hierarchical Mixture Networks (HINT), a model family for efficient and accurate coherent forecasting. We specialize the networks on the task via a multivariate mixture optimized with composite likelihood and made coherent via bootstrap reconciliation. Additionally, we robustify the networks to stark time series scale variations, incorporating normalized feature extraction and recomposition of output scales within their architecture. We demonstrate 8% sCRPS improved accuracy across five datasets compared to the existing state-of-the-art. We conduct ablation studies on our model's components and extensively investigate the theoretical properties of the multivariate mixture. HINT's code is available at this https://github.com/Nixtla/neuralforecast.
SpectraNet: Multivariate Forecasting and Imputation under Distribution Shifts and Missing Data
Oct 25, 2022

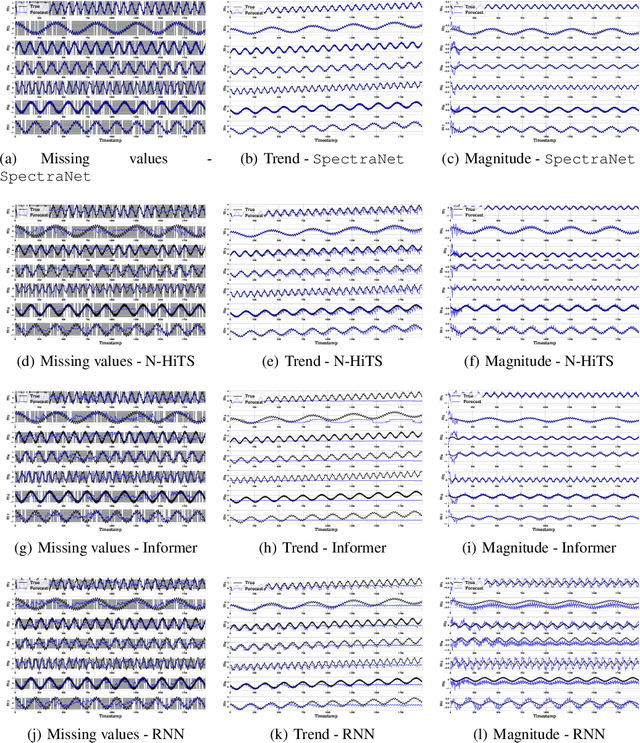

In this work, we tackle two widespread challenges in real applications for time-series forecasting that have been largely understudied: distribution shifts and missing data. We propose SpectraNet, a novel multivariate time-series forecasting model that dynamically infers a latent space spectral decomposition to capture current temporal dynamics and correlations on the recent observed history. A Convolution Neural Network maps the learned representation by sequentially mixing its components and refining the output. Our proposed approach can simultaneously produce forecasts and interpolate past observations and can, therefore, greatly simplify production systems by unifying imputation and forecasting tasks into a single model. SpectraNet achieves SoTA performance simultaneously on both tasks on five benchmark datasets, compared to forecasting and imputation models, with up to 92% fewer parameters and comparable training times. On settings with up to 80% missing data, SpectraNet has average performance improvements of almost 50% over the second-best alternative. Our code is available at https://github.com/cchallu/spectranet.
Unsupervised Model Selection for Time-series Anomaly Detection
Oct 03, 2022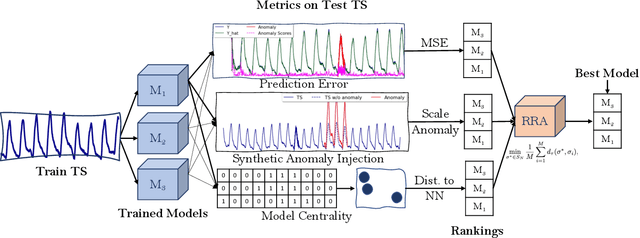
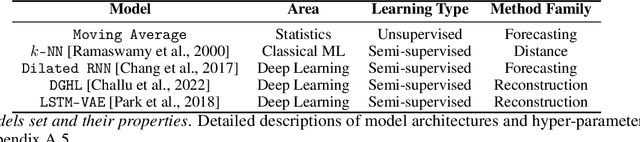
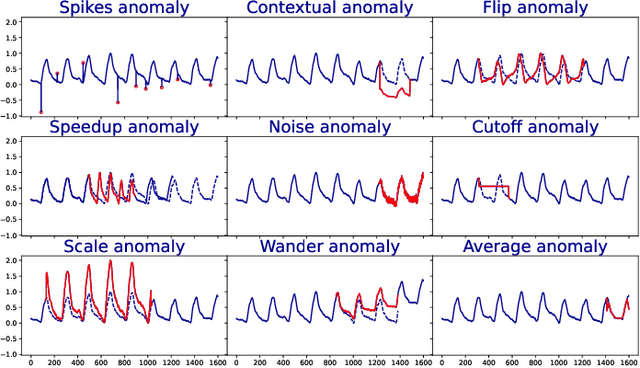
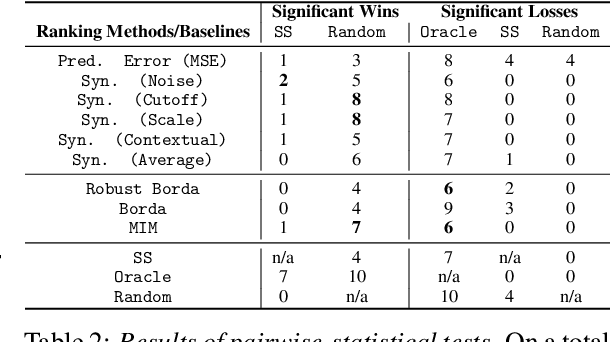
Anomaly detection in time-series has a wide range of practical applications. While numerous anomaly detection methods have been proposed in the literature, a recent survey concluded that no single method is the most accurate across various datasets. To make matters worse, anomaly labels are scarce and rarely available in practice. The practical problem of selecting the most accurate model for a given dataset without labels has received little attention in the literature. This paper answers this question i.e. Given an unlabeled dataset and a set of candidate anomaly detectors, how can we select the most accurate model? To this end, we identify three classes of surrogate (unsupervised) metrics, namely, prediction error, model centrality, and performance on injected synthetic anomalies, and show that some metrics are highly correlated with standard supervised anomaly detection performance metrics such as the $F_1$ score, but to varying degrees. We formulate metric combination with multiple imperfect surrogate metrics as a robust rank aggregation problem. We then provide theoretical justification behind the proposed approach. Large-scale experiments on multiple real-world datasets demonstrate that our proposed unsupervised approach is as effective as selecting the most accurate model based on partially labeled data.
Deep Generative model with Hierarchical Latent Factors for Time Series Anomaly Detection
Feb 25, 2022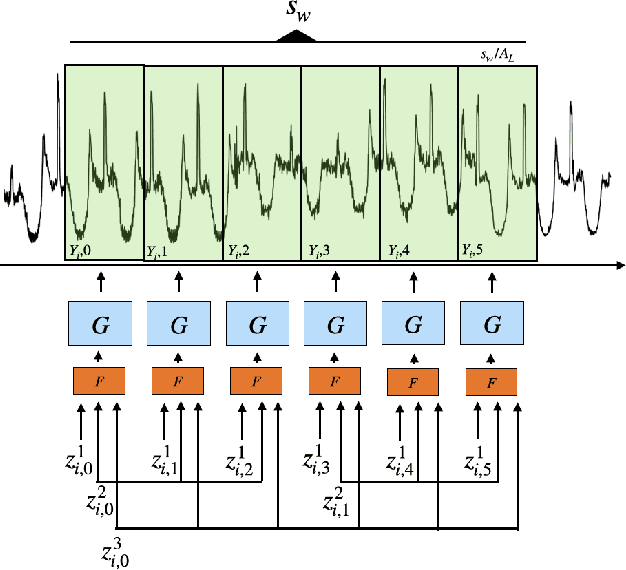
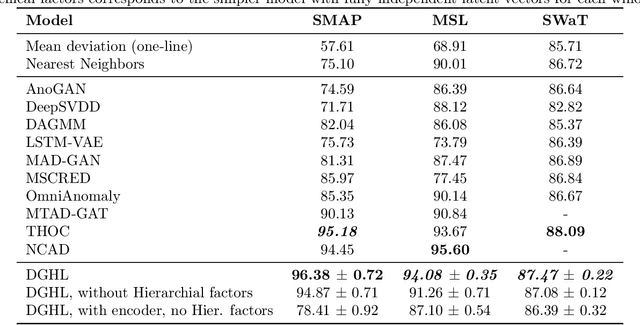

Multivariate time series anomaly detection has become an active area of research in recent years, with Deep Learning models outperforming previous approaches on benchmark datasets. Among reconstruction-based models, most previous work has focused on Variational Autoencoders and Generative Adversarial Networks. This work presents DGHL, a new family of generative models for time series anomaly detection, trained by maximizing the observed likelihood by posterior sampling and alternating back-propagation. A top-down Convolution Network maps a novel hierarchical latent space to time series windows, exploiting temporal dynamics to encode information efficiently. Despite relying on posterior sampling, it is computationally more efficient than current approaches, with up to 10x shorter training times than RNN based models. Our method outperformed current state-of-the-art models on four popular benchmark datasets. Finally, DGHL is robust to variable features between entities and accurate even with large proportions of missing values, settings with increasing relevance with the advent of IoT. We demonstrate the superior robustness of DGHL with novel occlusion experiments in this literature. Our code is available at https://github.com/cchallu/dghl.
N-HiTS: Neural Hierarchical Interpolation for Time Series Forecasting
Feb 02, 2022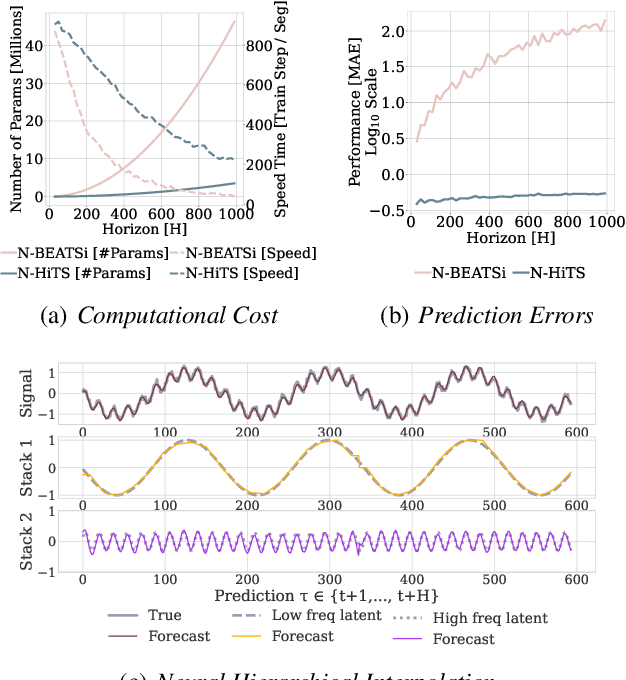

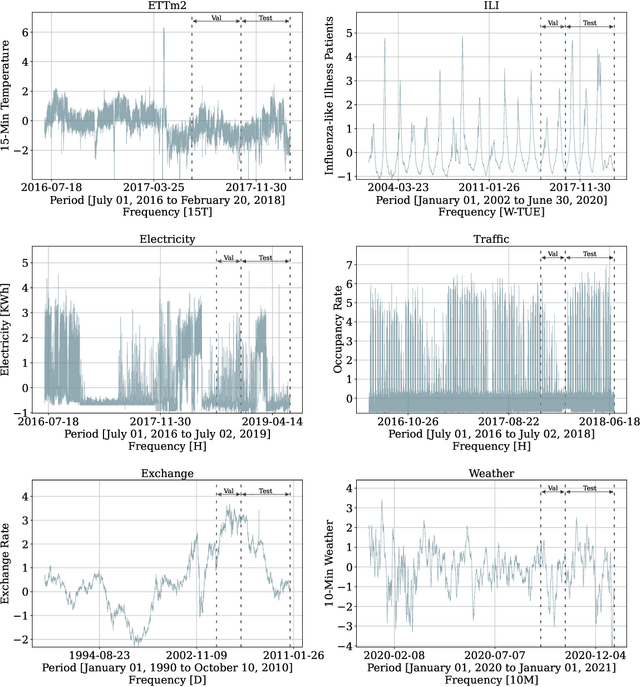
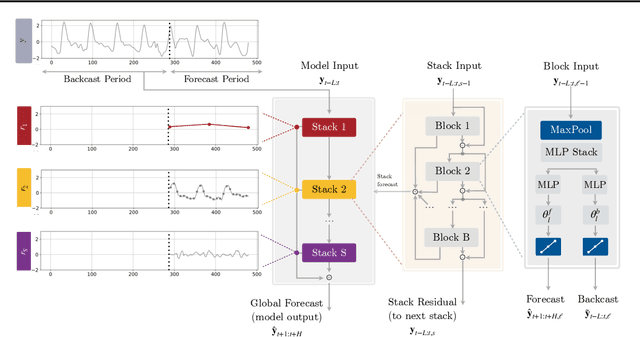
Recent progress in neural forecasting accelerated improvements in the performance of large-scale forecasting systems. Yet, long-horizon forecasting remains a very difficult task. Two common challenges afflicting long-horizon forecasting are the volatility of the predictions and their computational complexity. In this paper, we introduce N-HiTS, a model which addresses both challenges by incorporating novel hierarchical interpolation and multi-rate data sampling techniques. These techniques enable the proposed method to assemble its predictions sequentially, selectively emphasizing components with different frequencies and scales, while decomposing the input signal and synthesizing the forecast. We conduct an extensive empirical evaluation demonstrating the advantages of N-HiTS over the state-of-the-art long-horizon forecasting methods. On an array of multivariate forecasting tasks, the proposed method provides an average accuracy improvement of 25% over the latest Transformer architectures while reducing the computation time by an order of magnitude. Our code is available at https://github.com/cchallu/n-hits.
DMIDAS: Deep Mixed Data Sampling Regression for Long Multi-Horizon Time Series Forecasting
Jun 07, 2021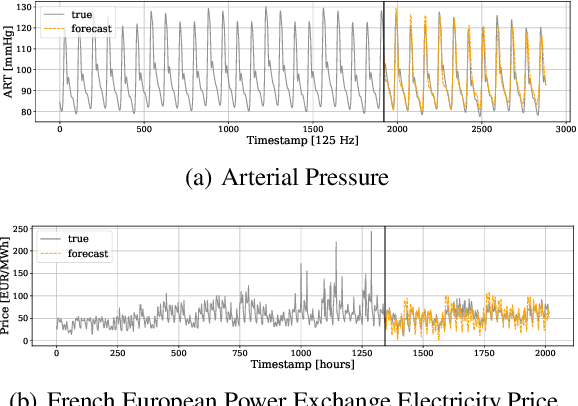
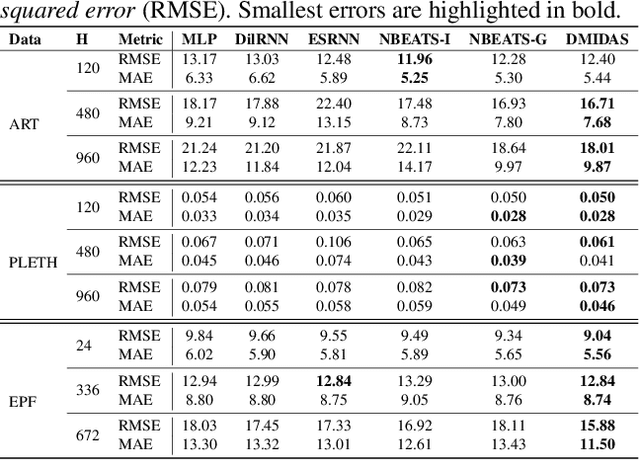
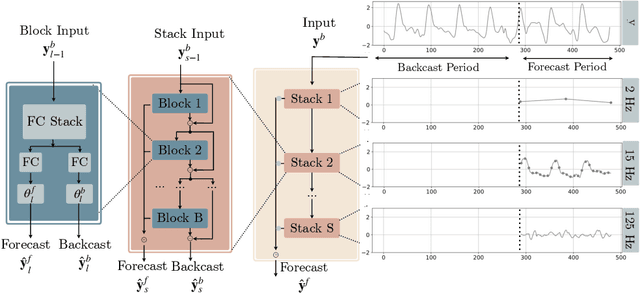
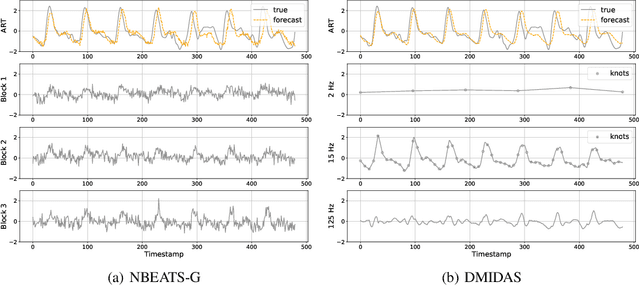
Neural forecasting has shown significant improvements in the accuracy of large-scale systems, yet predicting extremely long horizons remains a challenging task. Two common problems are the volatility of the predictions and their computational complexity; we addressed them by incorporating smoothness regularization and mixed data sampling techniques to a well-performing multi-layer perceptron based architecture (NBEATS). We validate our proposed method, DMIDAS, on high-frequency healthcare and electricity price data with long forecasting horizons (~1000 timestamps) where we improve the prediction accuracy by 5% over state-of-the-art models, reducing the number of parameters of NBEATS by nearly 70%.
Neural basis expansion analysis with exogenous variables: Forecasting electricity prices with NBEATSx
Apr 23, 2021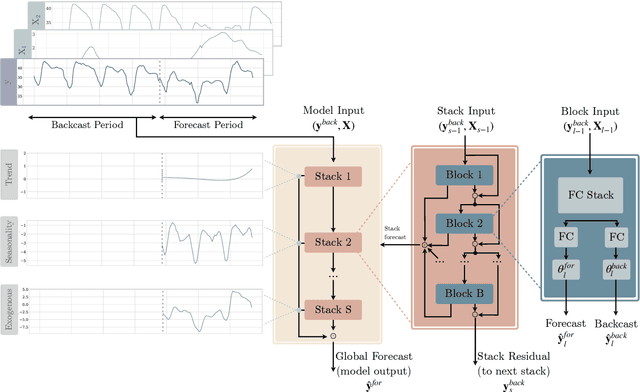

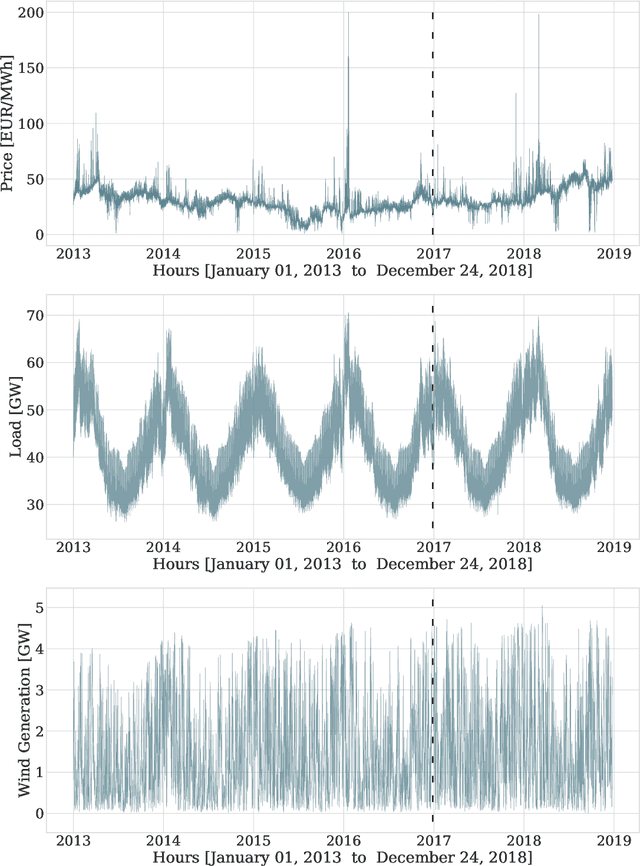

We extend the neural basis expansion analysis (NBEATS) to incorporate exogenous factors. The resulting method, called NBEATSx, improves on a well performing deep learning model, extending its capabilities by including exogenous variables and allowing it to integrate multiple sources of useful information. To showcase the utility of the NBEATSx model, we conduct a comprehensive study of its application to electricity price forecasting (EPF) tasks across a broad range of years and markets. We observe state-of-the-art performance, significantly improving the forecast accuracy by nearly 20% over the original NBEATS model, and by up to 5% over other well established statistical and machine learning methods specialized for these tasks. Additionally, the proposed neural network has an interpretable configuration that can structurally decompose time series, visualizing the relative impact of trend and seasonal components and revealing the modeled processes' interactions with exogenous factors. To assist related work we made the code available in https://github.com/cchallu/nbeatsx.