 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTerraFormer: Automated Infrastructure-as-Code with LLMs Fine-Tuned via Policy-Guided Verifier Feedback
Jan 13, 2026Automating Infrastructure-as-Code (IaC) is challenging, and large language models (LLMs) often produce incorrect configurations from natural language (NL). We present TerraFormer, a neuro-symbolic framework for IaC generation and mutation that combines supervised fine-tuning with verifier-guided reinforcement learning, using formal verification tools to provide feedback on syntax, deployability, and policy compliance. We curate two large, high-quality NL-to-IaC datasets, TF-Gen (152k instances) and TF-Mutn (52k instances), via multi-stage verification and iterative LLM self-correction. Evaluations against 17 state-of-the-art LLMs, including ~50x larger models like Sonnet 3.7, DeepSeek-R1, and GPT-4.1, show that TerraFormer improves correctness over its base LLM by 15.94% on IaC-Eval, 11.65% on TF-Gen (Test), and 19.60% on TF-Mutn (Test). It outperforms larger models on both TF-Gen (Test) and TF-Mutn (Test), ranks third on IaC-Eval, and achieves top best-practices and security compliance.
MUSS: Multilevel Subset Selection for Relevance and Diversity
Mar 14, 2025The problem of relevant and diverse subset selection has a wide range of applications, including recommender systems and retrieval-augmented generation (RAG). For example, in recommender systems, one is interested in selecting relevant items, while providing a diversified recommendation. Constrained subset selection problem is NP-hard, and popular approaches such as Maximum Marginal Relevance (MMR) are based on greedy selection. Many real-world applications involve large data, but the original MMR work did not consider distributed selection. This limitation was later addressed by a method called DGDS which allows for a distributed setting using random data partitioning. Here, we exploit structure in the data to further improve both scalability and performance on the target application. We propose MUSS, a novel method that uses a multilevel approach to relevant and diverse selection. We provide a rigorous theoretical analysis and show that our method achieves a constant factor approximation of the optimal objective. In a recommender system application, our method can achieve the same level of performance as baselines, but 4.5 to 20 times faster. Our method is also capable of outperforming baselines by up to 6 percent points of RAG-based question answering accuracy.
REDO: Execution-Free Runtime Error Detection for COding Agents
Oct 10, 2024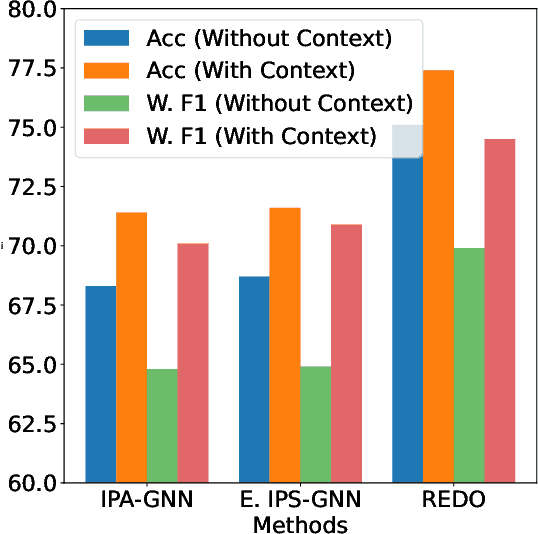

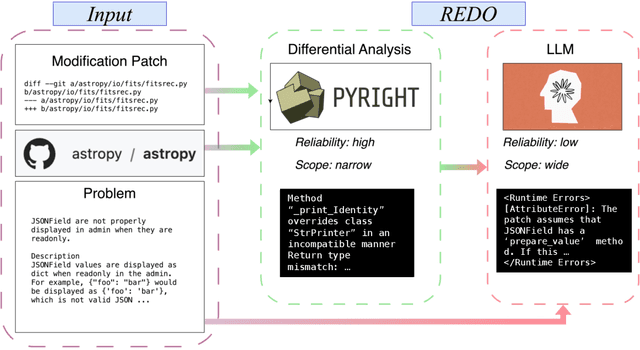
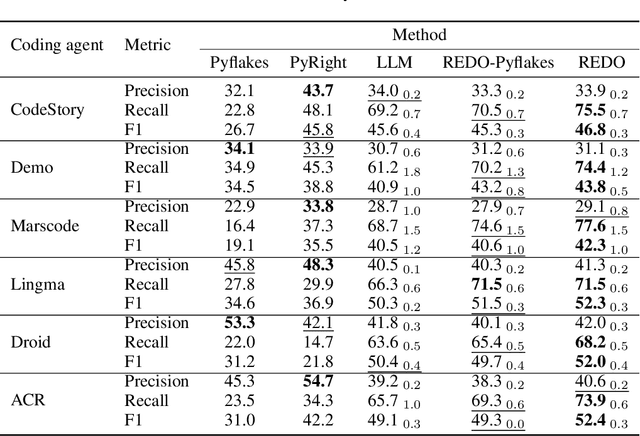
As LLM-based agents exhibit exceptional capabilities in addressing complex problems, there is a growing focus on developing coding agents to tackle increasingly sophisticated tasks. Despite their promising performance, these coding agents often produce programs or modifications that contain runtime errors, which can cause code failures and are difficult for static analysis tools to detect. Enhancing the ability of coding agents to statically identify such errors could significantly improve their overall performance. In this work, we introduce Execution-free Runtime Error Detection for COding Agents (REDO), a method that integrates LLMs with static analysis tools to detect runtime errors for coding agents, without code execution. Additionally, we propose a benchmark task, SWE-Bench-Error-Detection (SWEDE), based on SWE-Bench (lite), to evaluate error detection in repository-level problems with complex external dependencies. Finally, through both quantitative and qualitative analyses across various error detection tasks, we demonstrate that REDO outperforms current state-of-the-art methods by achieving a 11.0% higher accuracy and 9.1% higher weighted F1 score; and provide insights into the advantages of incorporating LLMs for error detection.
MELODY: Robust Semi-Supervised Hybrid Model for Entity-Level Online Anomaly Detection with Multivariate Time Series
Jan 18, 2024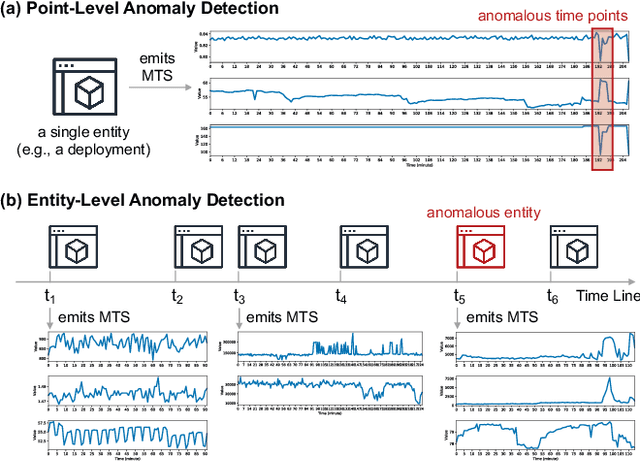

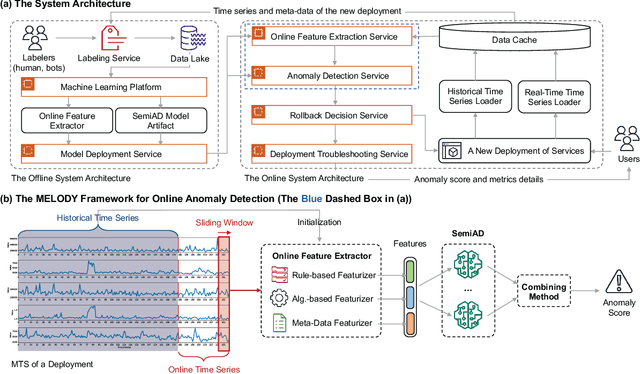
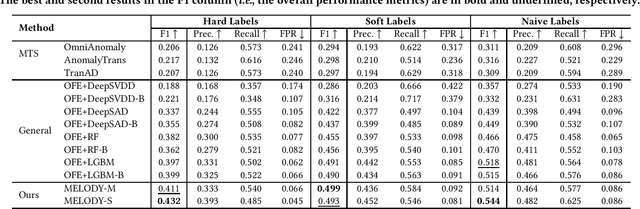
In large IT systems, software deployment is a crucial process in online services as their code is regularly updated. However, a faulty code change may degrade the target service's performance and cause cascading outages in downstream services. Thus, software deployments should be comprehensively monitored, and their anomalies should be detected timely. In this paper, we study the problem of anomaly detection for deployments. We begin by identifying the challenges unique to this anomaly detection problem, which is at entity-level (e.g., deployments), relative to the more typical problem of anomaly detection in multivariate time series (MTS). The unique challenges include the heterogeneity of deployments, the low latency tolerance, the ambiguous anomaly definition, and the limited supervision. To address them, we propose a novel framework, semi-supervised hybrid Model for Entity-Level Online Detection of anomalY (MELODY). MELODY first transforms the MTS of different entities to the same feature space by an online feature extractor, then uses a newly proposed semi-supervised deep one-class model for detecting anomalous entities. We evaluated MELODY on real data of cloud services with 1.2M+ time series. The relative F1 score improvement of MELODY over the state-of-the-art methods ranges from 7.6% to 56.5%. The user evaluation suggests MELODY is suitable for monitoring deployments in large online systems.
Unsupervised Model Selection for Time-series Anomaly Detection
Oct 03, 2022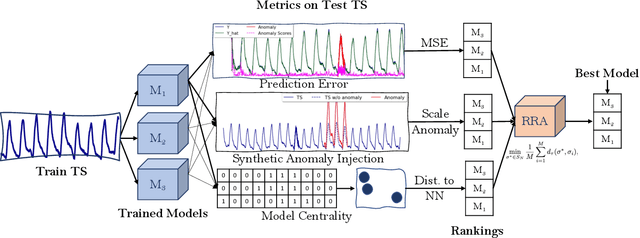
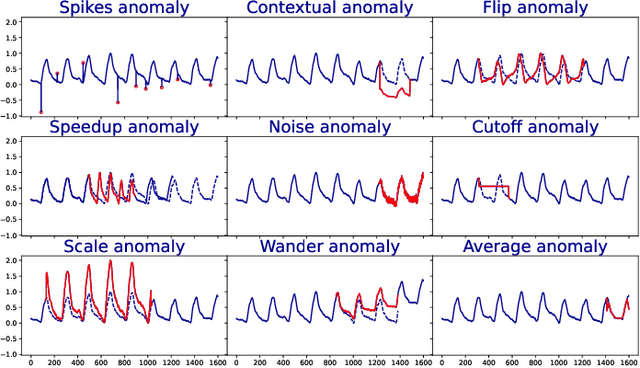
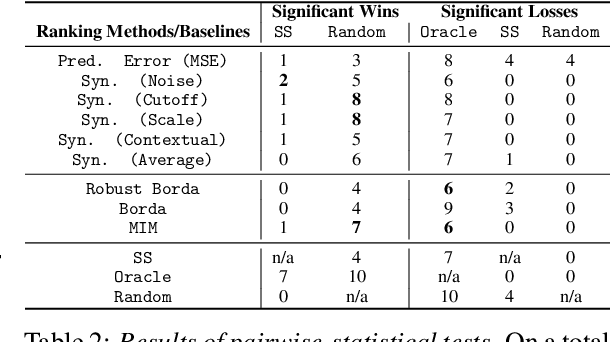
Anomaly detection in time-series has a wide range of practical applications. While numerous anomaly detection methods have been proposed in the literature, a recent survey concluded that no single method is the most accurate across various datasets. To make matters worse, anomaly labels are scarce and rarely available in practice. The practical problem of selecting the most accurate model for a given dataset without labels has received little attention in the literature. This paper answers this question i.e. Given an unlabeled dataset and a set of candidate anomaly detectors, how can we select the most accurate model? To this end, we identify three classes of surrogate (unsupervised) metrics, namely, prediction error, model centrality, and performance on injected synthetic anomalies, and show that some metrics are highly correlated with standard supervised anomaly detection performance metrics such as the $F_1$ score, but to varying degrees. We formulate metric combination with multiple imperfect surrogate metrics as a robust rank aggregation problem. We then provide theoretical justification behind the proposed approach. Large-scale experiments on multiple real-world datasets demonstrate that our proposed unsupervised approach is as effective as selecting the most accurate model based on partially labeled data.
Online Time Series Anomaly Detection with State Space Gaussian Processes
Jan 18, 2022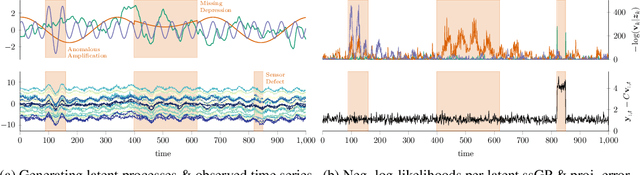
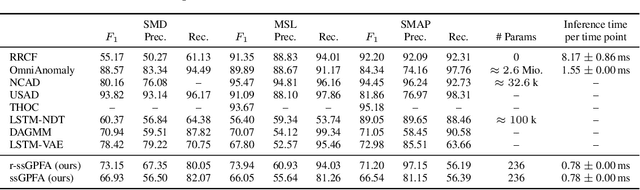
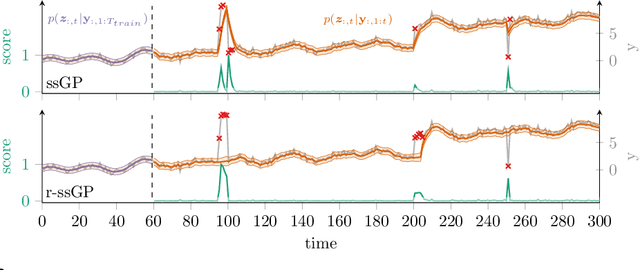
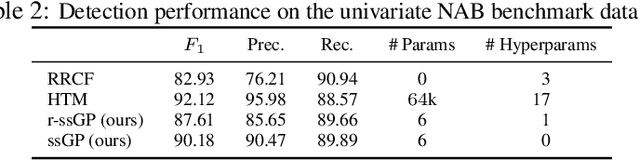
We propose r-ssGPFA, an unsupervised online anomaly detection model for uni- and multivariate time series building on the efficient state space formulation of Gaussian processes. For high-dimensional time series, we propose an extension of Gaussian process factor analysis to identify the common latent processes of the time series, allowing us to detect anomalies efficiently in an interpretable manner. We gain explainability while speeding up computations by imposing an orthogonality constraint on the mapping from the latent to the observed. Our model's robustness is improved by using a simple heuristic to skip Kalman updates when encountering anomalous observations. We investigate the behaviour of our model on synthetic data and show on standard benchmark datasets that our method is competitive with state-of-the-art methods while being computationally cheaper.
J-Recs: Principled and Scalable Recommendation Justification
Nov 11, 2020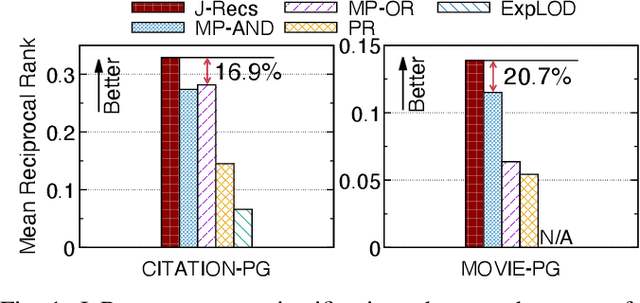
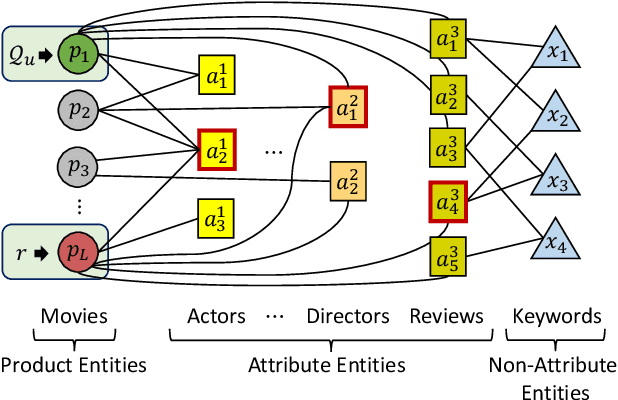

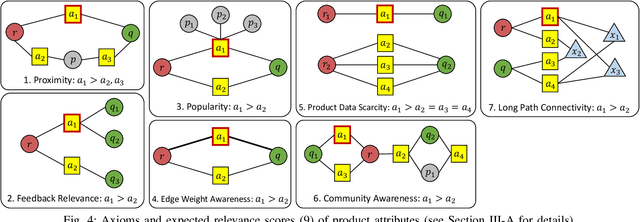
Online recommendation is an essential functionality across a variety of services, including e-commerce and video streaming, where items to buy, watch, or read are suggested to users. Justifying recommendations, i.e., explaining why a user might like the recommended item, has been shown to improve user satisfaction and persuasiveness of the recommendation. In this paper, we develop a method for generating post-hoc justifications that can be applied to the output of any recommendation algorithm. Existing post-hoc methods are often limited in providing diverse justifications, as they either use only one of many available types of input data, or rely on the predefined templates. We address these limitations of earlier approaches by developing J-Recs, a method for producing concise and diverse justifications. J-Recs is a recommendation model-agnostic method that generates diverse justifications based on various types of product and user data (e.g., purchase history and product attributes). The challenge of jointly processing multiple types of data is addressed by designing a principled graph-based approach for justification generation. In addition to theoretical analysis, we present an extensive evaluation on synthetic and real-world data. Our results show that J-Recs satisfies desirable properties of justifications, and efficiently produces effective justifications, matching user preferences up to 20% more accurately than baselines.
AutoKnow: Self-Driving Knowledge Collection for Products of Thousands of Types
Jun 24, 2020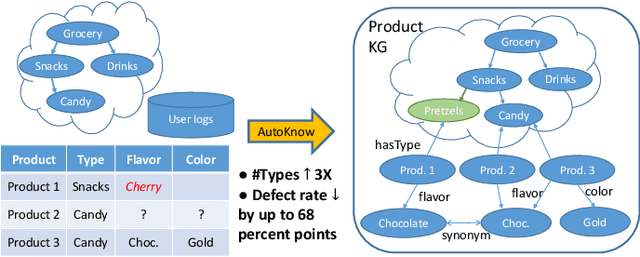

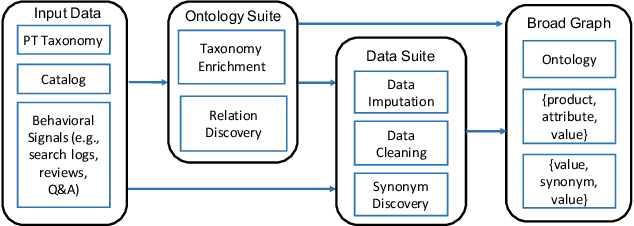
Can one build a knowledge graph (KG) for all products in the world? Knowledge graphs have firmly established themselves as valuable sources of information for search and question answering, and it is natural to wonder if a KG can contain information about products offered at online retail sites. There have been several successful examples of generic KGs, but organizing information about products poses many additional challenges, including sparsity and noise of structured data for products, complexity of the domain with millions of product types and thousands of attributes, heterogeneity across large number of categories, as well as large and constantly growing number of products. We describe AutoKnow, our automatic (self-driving) system that addresses these challenges. The system includes a suite of novel techniques for taxonomy construction, product property identification, knowledge extraction, anomaly detection, and synonym discovery. AutoKnow is (a) automatic, requiring little human intervention, (b) multi-scalable, scalable in multiple dimensions (many domains, many products, and many attributes), and (c) integrative, exploiting rich customer behavior logs. AutoKnow has been operational in collecting product knowledge for over 11K product types.
MultiImport: Inferring Node Importance in a Knowledge Graph from Multiple Input Signals
Jun 22, 2020
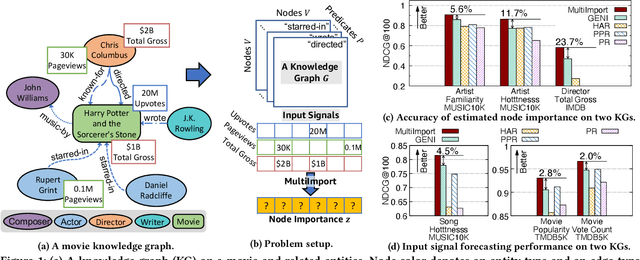
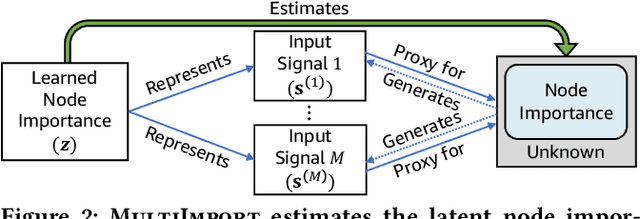

Given multiple input signals, how can we infer node importance in a knowledge graph (KG)? Node importance estimation is a crucial and challenging task that can benefit a lot of applications including recommendation, search, and query disambiguation. A key challenge towards this goal is how to effectively use input from different sources. On the one hand, a KG is a rich source of information, with multiple types of nodes and edges. On the other hand, there are external input signals, such as the number of votes or pageviews, which can directly tell us about the importance of entities in a KG. While several methods have been developed to tackle this problem, their use of these external signals has been limited as they are not designed to consider multiple signals simultaneously. In this paper, we develop an end-to-end model MultiImport, which infers latent node importance from multiple, potentially overlapping, input signals. MultiImport is a latent variable model that captures the relation between node importance and input signals, and effectively learns from multiple signals with potential conflicts. Also, MultiImport provides an effective estimator based on attentive graph neural networks. We ran experiments on real-world KGs to show that MultiImport handles several challenges involved with inferring node importance from multiple input signals, and consistently outperforms existing methods, achieving up to 23.7% higher NDCG@100 than the state-of-the-art method.
Octet: Online Catalog Taxonomy Enrichment with Self-Supervision
Jun 18, 2020
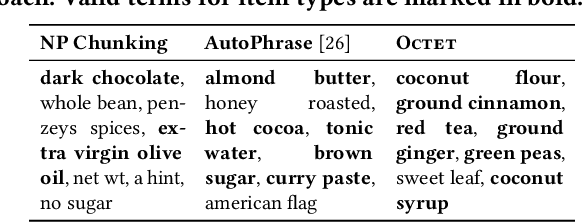
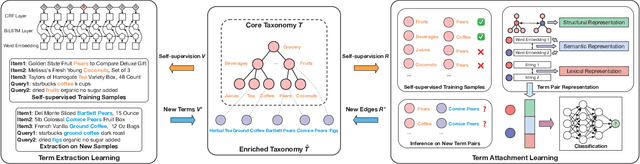
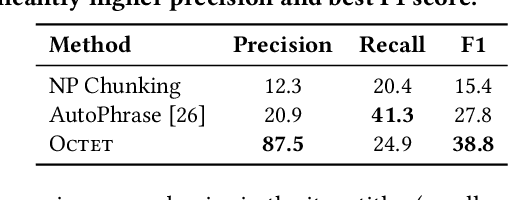
Taxonomies have found wide applications in various domains, especially online for item categorization, browsing, and search. Despite the prevalent use of online catalog taxonomies, most of them in practice are maintained by humans, which is labor-intensive and difficult to scale. While taxonomy construction from scratch is considerably studied in the literature, how to effectively enrich existing incomplete taxonomies remains an open yet important research question. Taxonomy enrichment not only requires the robustness to deal with emerging terms but also the consistency between existing taxonomy structure and new term attachment. In this paper, we present a self-supervised end-to-end framework, Octet, for Online Catalog Taxonomy EnrichmenT. Octet leverages heterogeneous information unique to online catalog taxonomies such as user queries, items, and their relations to the taxonomy nodes while requiring no other supervision than the existing taxonomies. We propose to distantly train a sequence labeling model for term extraction and employ graph neural networks (GNNs) to capture the taxonomy structure as well as the query-item-taxonomy interactions for term attachment. Extensive experiments in different online domains demonstrate the superiority of Octet over state-of-the-art methods via both automatic and human evaluations. Notably, Octet enriches an online catalog taxonomy in production to 2 times larger in the open-world evaluation.