 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREDO: Execution-Free Runtime Error Detection for COding Agents
Oct 10, 2024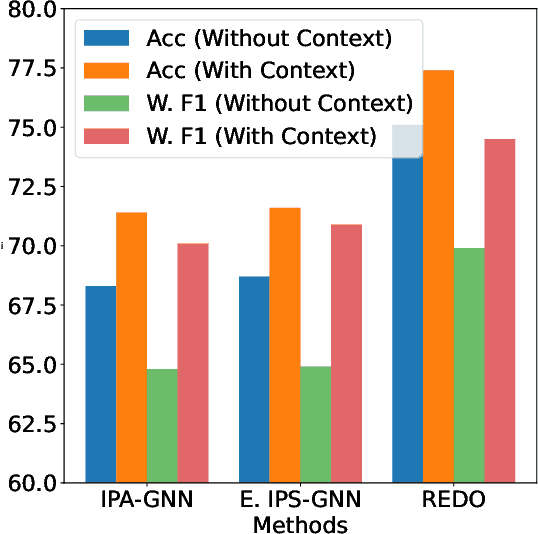

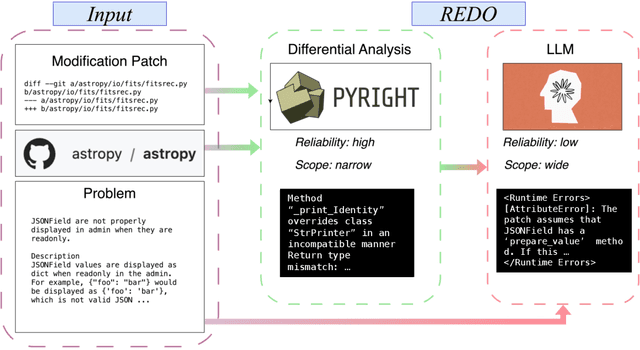
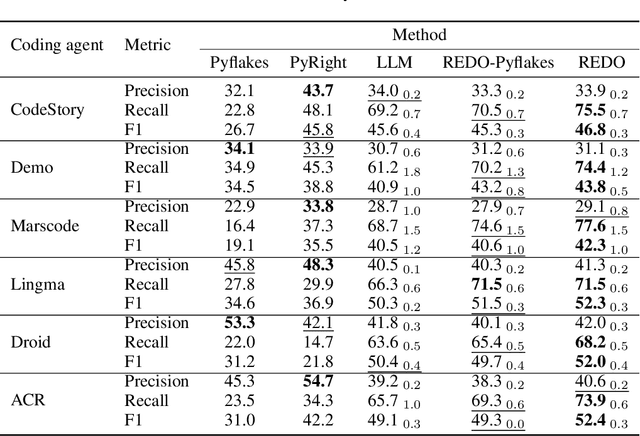
As LLM-based agents exhibit exceptional capabilities in addressing complex problems, there is a growing focus on developing coding agents to tackle increasingly sophisticated tasks. Despite their promising performance, these coding agents often produce programs or modifications that contain runtime errors, which can cause code failures and are difficult for static analysis tools to detect. Enhancing the ability of coding agents to statically identify such errors could significantly improve their overall performance. In this work, we introduce Execution-free Runtime Error Detection for COding Agents (REDO), a method that integrates LLMs with static analysis tools to detect runtime errors for coding agents, without code execution. Additionally, we propose a benchmark task, SWE-Bench-Error-Detection (SWEDE), based on SWE-Bench (lite), to evaluate error detection in repository-level problems with complex external dependencies. Finally, through both quantitative and qualitative analyses across various error detection tasks, we demonstrate that REDO outperforms current state-of-the-art methods by achieving a 11.0% higher accuracy and 9.1% higher weighted F1 score; and provide insights into the advantages of incorporating LLMs for error detection.
Progressive Query Expansion for Retrieval Over Cost-constrained Data Sources
Jun 11, 2024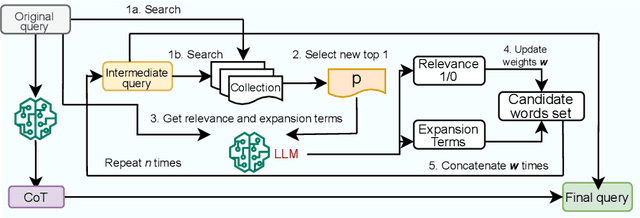
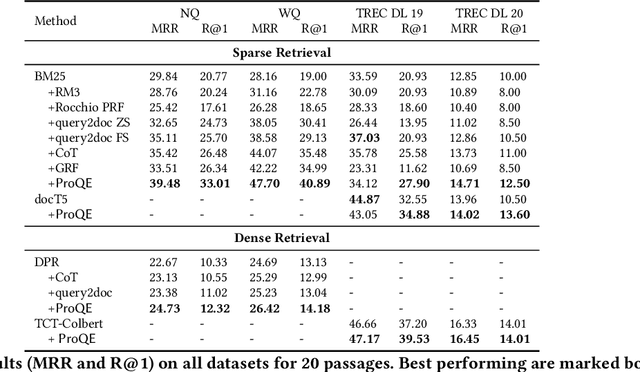
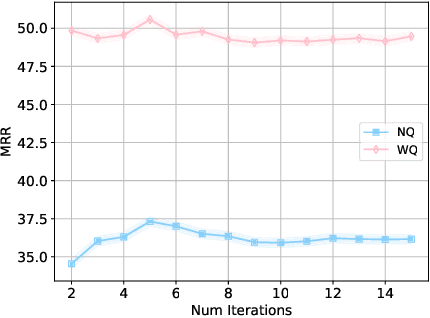
Query expansion has been employed for a long time to improve the accuracy of query retrievers. Earlier works relied on pseudo-relevance feedback (PRF) techniques, which augment a query with terms extracted from documents retrieved in a first stage. However, the documents may be noisy hindering the effectiveness of the ranking. To avoid this, recent studies have instead used Large Language Models (LLMs) to generate additional content to expand a query. These techniques are prone to hallucination and also focus on the LLM usage cost. However, the cost may be dominated by the retrieval in several important practical scenarios, where the corpus is only available via APIs which charge a fee per retrieved document. We propose combining classic PRF techniques with LLMs and create a progressive query expansion algorithm ProQE that iteratively expands the query as it retrieves more documents. ProQE is compatible with both sparse and dense retrieval systems. Our experimental results on four retrieval datasets show that ProQE outperforms state-of-the-art baselines by 37% and is the most cost-effective.
EcoRank: Budget-Constrained Text Re-ranking Using Large Language Models
Feb 16, 2024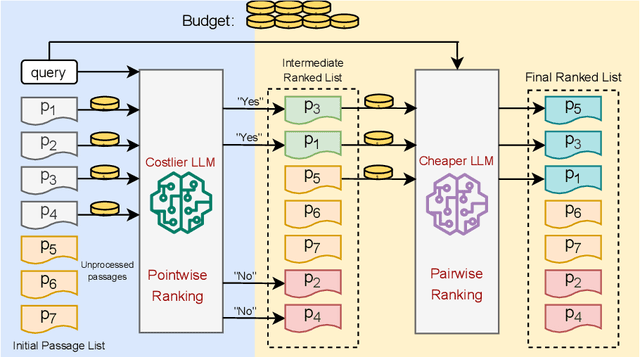
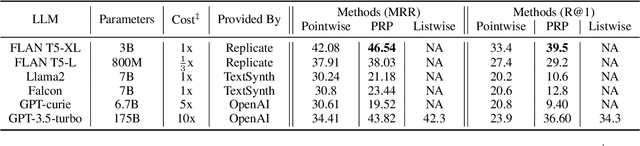

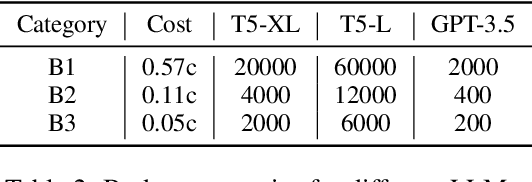
Large Language Models (LLMs) have achieved state-of-the-art performance in text re-ranking. This process includes queries and candidate passages in the prompts, utilizing pointwise, listwise, and pairwise prompting strategies. A limitation of these ranking strategies with LLMs is their cost: the process can become expensive due to API charges, which are based on the number of input and output tokens. We study how to maximize the re-ranking performance given a budget, by navigating the vast search spaces of prompt choices, LLM APIs, and budget splits. We propose a suite of budget-constrained methods to perform text re-ranking using a set of LLM APIs. Our most efficient method, called EcoRank, is a two-layered pipeline that jointly optimizes decisions regarding budget allocation across prompt strategies and LLM APIs. Our experimental results on four popular QA and passage reranking datasets show that EcoRank outperforms other budget-aware supervised and unsupervised baselines.
PAT-Questions: A Self-Updating Benchmark for Present-Anchored Temporal Question-Answering
Feb 16, 2024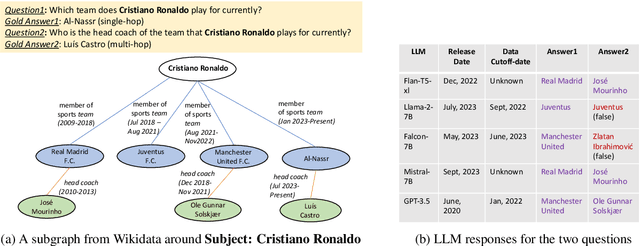
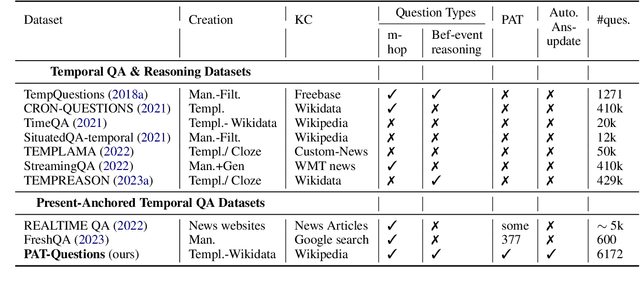


Existing work on Temporal Question Answering (TQA) has predominantly focused on questions anchored to specific timestamps or events (e.g. "Who was the US president in 1970?"). Little work has studied questions whose temporal context is relative to the present time (e.g. "Who was the previous US president?"). We refer to this problem as Present-Anchored Temporal QA (PATQA). PATQA poses unique challenges: (1) large language models (LLMs) may have outdated knowledge, (2) complex temporal relationships (e.g. 'before', 'previous') are hard to reason, (3) multi-hop reasoning may be required, and (4) the gold answers of benchmarks must be continuously updated. To address these challenges, we introduce the PAT-Questions benchmark, which includes single and multi-hop temporal questions. The answers in PAT-Questions can be automatically refreshed by re-running SPARQL queries on a knowledge graph, if available. We evaluate several state-of-the-art LLMs and a SOTA temporal reasoning model (TEMPREASON-T5) on PAT-Questions through direct prompting and retrieval-augmented generation (RAG). The results highlight the limitations of existing solutions in PATQA and motivate the need for new methods to improve PATQA reasoning capabilities.
NORMY: Non-Uniform History Modeling for Open Retrieval Conversational Question Answering
Feb 07, 2024

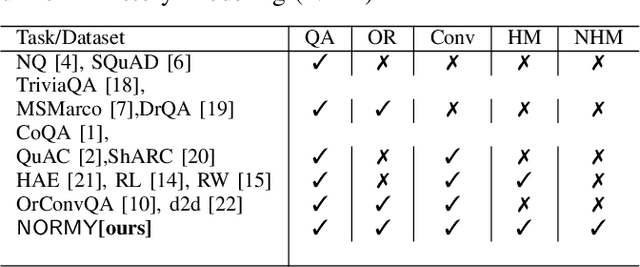

Open Retrieval Conversational Question Answering (OrConvQA) answers a question given a conversation as context and a document collection. A typical OrConvQA pipeline consists of three modules: a Retriever to retrieve relevant documents from the collection, a Reranker to rerank them given the question and the context, and a Reader to extract an answer span. The conversational turns can provide valuable context to answer the final query. State-of-the-art OrConvQA systems use the same history modeling for all three modules of the pipeline. We hypothesize this as suboptimal. Specifically, we argue that a broader context is needed in the first modules of the pipeline to not miss relevant documents, while a narrower context is needed in the last modules to identify the exact answer span. We propose NORMY, the first unsupervised non-uniform history modeling pipeline which generates the best conversational history for each module. We further propose a novel Retriever for NORMY, which employs keyphrase extraction on the conversation history, and leverages passages retrieved in previous turns as additional context. We also created a new dataset for OrConvQA, by expanding the doc2dial dataset. We implemented various state-of-the-art history modeling techniques and comprehensively evaluated them separately for each module of the pipeline on three datasets: OR-QUAC, our doc2dial extension, and ConvMix. Our extensive experiments show that NORMY outperforms the state-of-the-art in the individual modules and in the end-to-end system.