 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgressive Query Expansion for Retrieval Over Cost-constrained Data Sources
Paper and Code
Jun 11, 2024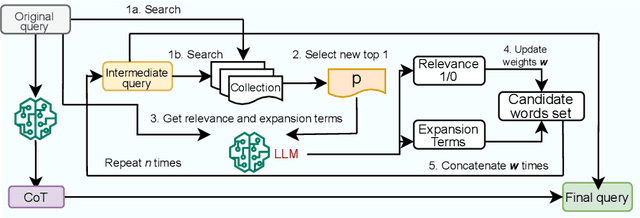
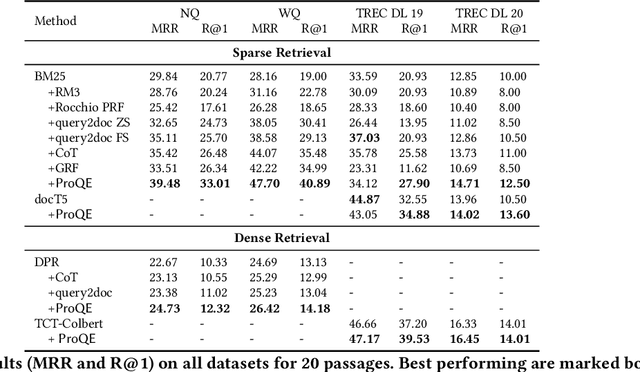
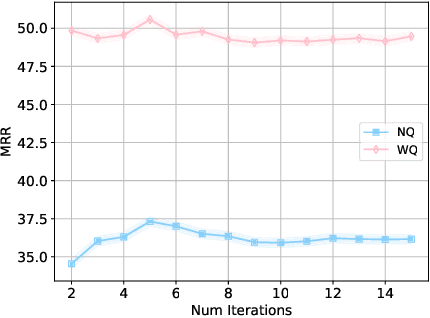
Query expansion has been employed for a long time to improve the accuracy of query retrievers. Earlier works relied on pseudo-relevance feedback (PRF) techniques, which augment a query with terms extracted from documents retrieved in a first stage. However, the documents may be noisy hindering the effectiveness of the ranking. To avoid this, recent studies have instead used Large Language Models (LLMs) to generate additional content to expand a query. These techniques are prone to hallucination and also focus on the LLM usage cost. However, the cost may be dominated by the retrieval in several important practical scenarios, where the corpus is only available via APIs which charge a fee per retrieved document. We propose combining classic PRF techniques with LLMs and create a progressive query expansion algorithm ProQE that iteratively expands the query as it retrieves more documents. ProQE is compatible with both sparse and dense retrieval systems. Our experimental results on four retrieval datasets show that ProQE outperforms state-of-the-art baselines by 37% and is the most cost-effective.