 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Mechanisms of Collaborative Learning in VAE Recommenders
Nov 10, 2025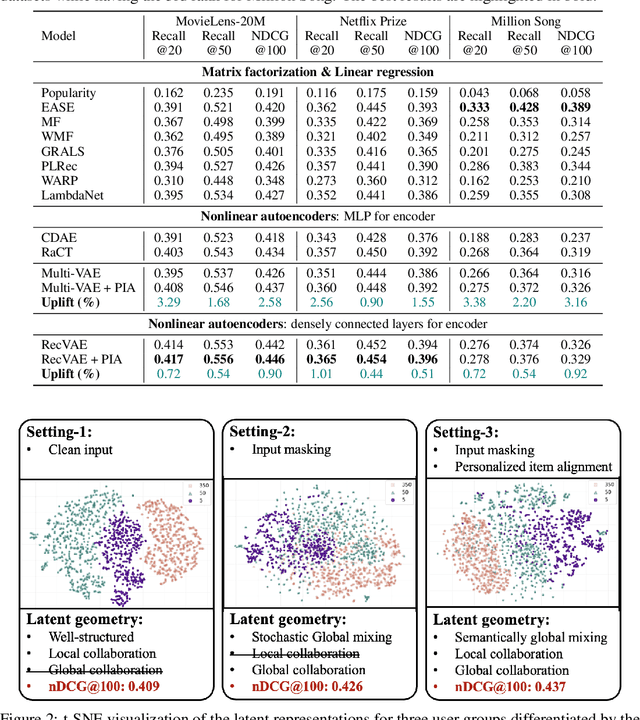
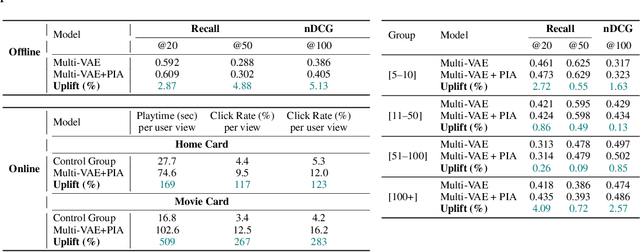

Variational Autoencoders (VAEs) are a powerful alternative to matrix factorization for recommendation. A common technique in VAE-based collaborative filtering (CF) consists in applying binary input masking to user interaction vectors, which improves performance but remains underexplored theoretically. In this work, we analyze how collaboration arises in VAE-based CF and show it is governed by latent proximity: we derive a latent sharing radius that informs when an SGD update on one user strictly reduces the loss on another user, with influence decaying as the latent Wasserstein distance increases. We further study the induced geometry: with clean inputs, VAE-based CF primarily exploits \emph{local} collaboration between input-similar users and under-utilizes global collaboration between far-but-related users. We compare two mechanisms that encourage \emph{global} mixing and characterize their trade-offs: (1) $β$-KL regularization directly tightens the information bottleneck, promoting posterior overlap but risking representational collapse if too large; (2) input masking induces stochastic geometric contractions and expansions, which can bring distant users onto the same latent neighborhood but also introduce neighborhood drift. To preserve user identity while enabling global consistency, we propose an anchor regularizer that aligns user posteriors with item embeddings, stabilizing users under masking and facilitating signal sharing across related items. Our analyses are validated on the Netflix, MovieLens-20M, and Million Song datasets. We also successfully deployed our proposed algorithm on an Amazon streaming platform following a successful online experiment.
MUSS: Multilevel Subset Selection for Relevance and Diversity
Mar 14, 2025The problem of relevant and diverse subset selection has a wide range of applications, including recommender systems and retrieval-augmented generation (RAG). For example, in recommender systems, one is interested in selecting relevant items, while providing a diversified recommendation. Constrained subset selection problem is NP-hard, and popular approaches such as Maximum Marginal Relevance (MMR) are based on greedy selection. Many real-world applications involve large data, but the original MMR work did not consider distributed selection. This limitation was later addressed by a method called DGDS which allows for a distributed setting using random data partitioning. Here, we exploit structure in the data to further improve both scalability and performance on the target application. We propose MUSS, a novel method that uses a multilevel approach to relevant and diverse selection. We provide a rigorous theoretical analysis and show that our method achieves a constant factor approximation of the optimal objective. In a recommender system application, our method can achieve the same level of performance as baselines, but 4.5 to 20 times faster. Our method is also capable of outperforming baselines by up to 6 percent points of RAG-based question answering accuracy.
Self-Supervision Improves Diffusion Models for Tabular Data Imputation
Jul 25, 2024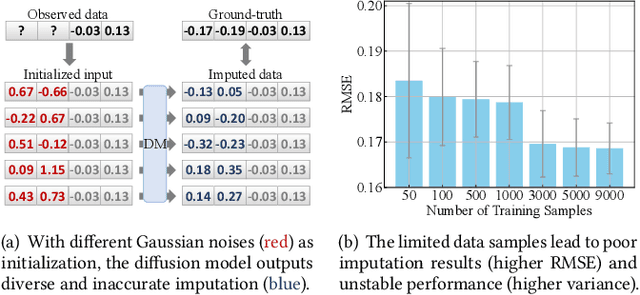
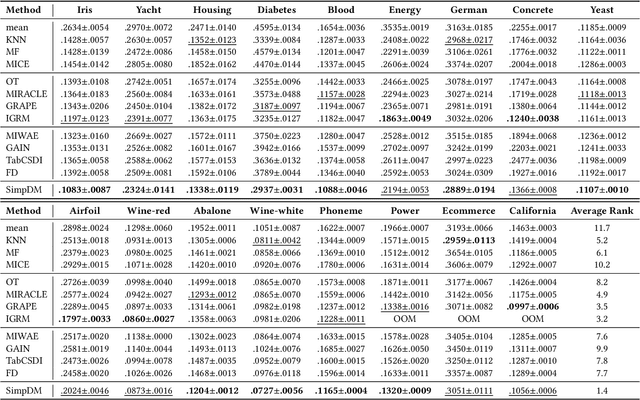
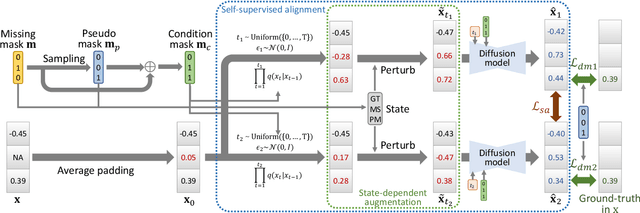
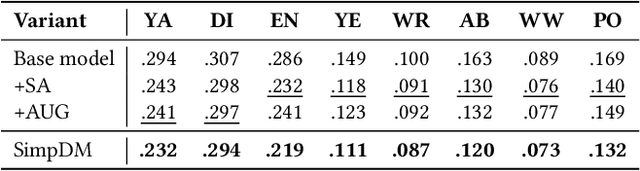
The ubiquity of missing data has sparked considerable attention and focus on tabular data imputation methods. Diffusion models, recognized as the cutting-edge technique for data generation, demonstrate significant potential in tabular data imputation tasks. However, in pursuit of diversity, vanilla diffusion models often exhibit sensitivity to initialized noises, which hinders the models from generating stable and accurate imputation results. Additionally, the sparsity inherent in tabular data poses challenges for diffusion models in accurately modeling the data manifold, impacting the robustness of these models for data imputation. To tackle these challenges, this paper introduces an advanced diffusion model named Self-supervised imputation Diffusion Model (SimpDM for brevity), specifically tailored for tabular data imputation tasks. To mitigate sensitivity to noise, we introduce a self-supervised alignment mechanism that aims to regularize the model, ensuring consistent and stable imputation predictions. Furthermore, we introduce a carefully devised state-dependent data augmentation strategy within SimpDM, enhancing the robustness of the diffusion model when dealing with limited data. Extensive experiments demonstrate that SimpDM matches or outperforms state-of-the-art imputation methods across various scenarios.
SAVA: Scalable Learning-Agnostic Data Valuation
Jun 03, 2024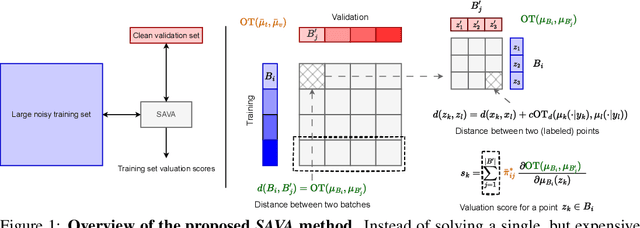

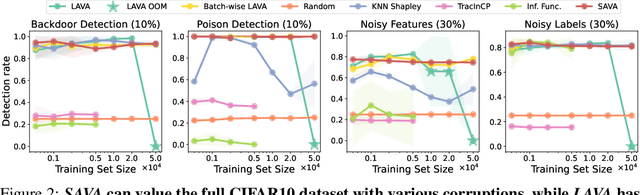
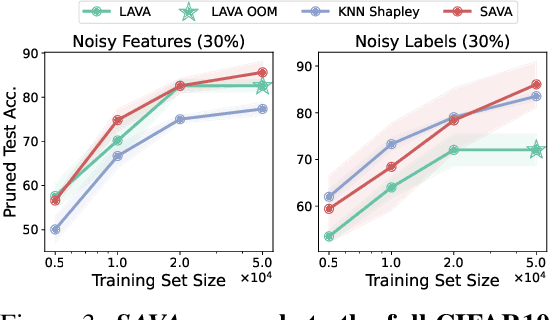
Selecting suitable data for training machine learning models is crucial since large, web-scraped, real datasets contain noisy artifacts that affect the quality and relevance of individual data points. These artifacts will impact the performance and generalization of the model. We formulate this problem as a data valuation task, assigning a value to data points in the training set according to how similar or dissimilar they are to a clean and curated validation set. Recently, LAVA (Just et al. 2023) successfully demonstrated the use of optimal transport (OT) between a large noisy training dataset and a clean validation set, to value training data efficiently, without the dependency on model performance. However, the LAVA algorithm requires the whole dataset as an input, this limits its application to large datasets. Inspired by the scalability of stochastic (gradient) approaches which carry out computations on batches of data points instead of the entire dataset, we analogously propose SAVA, a scalable variant of LAVA with its computation on batches of data points. Intuitively, SAVA follows the same scheme as LAVA which leverages the hierarchically defined OT for data valuation. However, while LAVA processes the whole dataset, SAVA divides the dataset into batches of data points, and carries out the OT problem computation on those batches. We perform extensive experiments, to demonstrate that SAVA can scale to large datasets with millions of data points and doesn't trade off data valuation performance.
Rejection via Learning Density Ratios
May 29, 2024
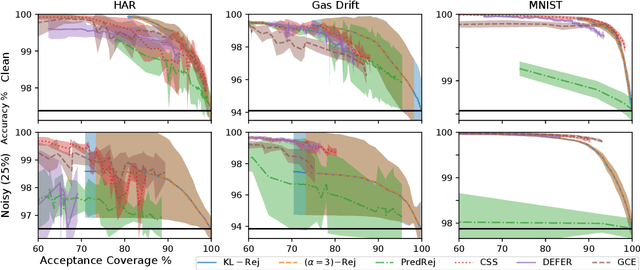

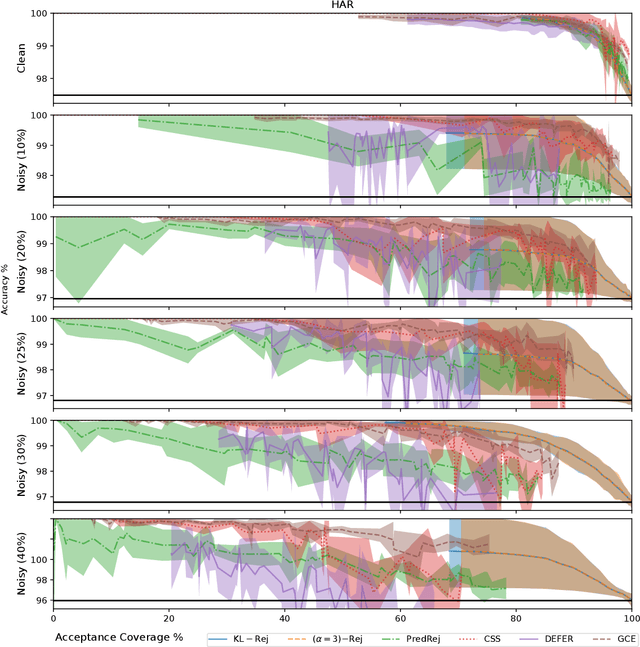
Classification with rejection emerges as a learning paradigm which allows models to abstain from making predictions. The predominant approach is to alter the supervised learning pipeline by augmenting typical loss functions, letting model rejection incur a lower loss than an incorrect prediction. Instead, we propose a different distributional perspective, where we seek to find an idealized data distribution which maximizes a pretrained model's performance. This can be formalized via the optimization of a loss's risk with a $ \phi$-divergence regularization term. Through this idealized distribution, a rejection decision can be made by utilizing the density ratio between this distribution and the data distribution. We focus on the setting where our $ \phi $-divergences are specified by the family of $ \alpha $-divergence. Our framework is tested empirically over clean and noisy datasets.
High-dimensional Bayesian Optimization via Covariance Matrix Adaptation Strategy
Feb 05, 2024Bayesian Optimization (BO) is an effective method for finding the global optimum of expensive black-box functions. However, it is well known that applying BO to high-dimensional optimization problems is challenging. To address this issue, a promising solution is to use a local search strategy that partitions the search domain into local regions with high likelihood of containing the global optimum, and then use BO to optimize the objective function within these regions. In this paper, we propose a novel technique for defining the local regions using the Covariance Matrix Adaptation (CMA) strategy. Specifically, we use CMA to learn a search distribution that can estimate the probabilities of data points being the global optimum of the objective function. Based on this search distribution, we then define the local regions consisting of data points with high probabilities of being the global optimum. Our approach serves as a meta-algorithm as it can incorporate existing black-box BO optimizers, such as BO, TuRBO, and BAxUS, to find the global optimum of the objective function within our derived local regions. We evaluate our proposed method on various benchmark synthetic and real-world problems. The results demonstrate that our method outperforms existing state-of-the-art techniques.
* 31 pages, 17 figures
Provably Efficient Bayesian Optimization with Unbiased Gaussian Process Hyperparameter Estimation
Jun 12, 2023


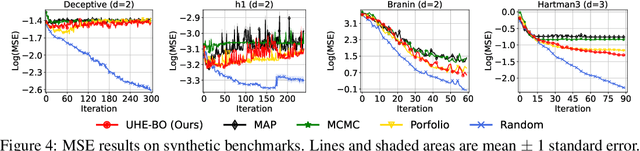
Gaussian process (GP) based Bayesian optimization (BO) is a powerful method for optimizing black-box functions efficiently. The practical performance and theoretical guarantees associated with this approach depend on having the correct GP hyperparameter values, which are usually unknown in advance and need to be estimated from the observed data. However, in practice, these estimations could be incorrect due to biased data sampling strategies commonly used in BO. This can lead to degraded performance and break the sub-linear global convergence guarantee of BO. To address this issue, we propose a new BO method that can sub-linearly converge to the global optimum of the objective function even when the true GP hyperparameters are unknown in advance and need to be estimated from the observed data. Our method uses a multi-armed bandit technique (EXP3) to add random data points to the BO process, and employs a novel training loss function for the GP hyperparameter estimation process that ensures unbiased estimation from the observed data. We further provide theoretical analysis of our proposed method. Finally, we demonstrate empirically that our method outperforms existing approaches on various synthetic and real-world problems.
Zero-shot Object Counting
Mar 03, 2023


Class-agnostic object counting aims to count object instances of an arbitrary class at test time. It is challenging but also enables many potential applications. Current methods require human-annotated exemplars as inputs which are often unavailable for novel categories, especially for autonomous systems. Thus, we propose zero-shot object counting (ZSC), a new setting where only the class name is available during test time. Such a counting system does not require human annotators in the loop and can operate automatically. Starting from a class name, we propose a method that can accurately identify the optimal patches which can then be used as counting exemplars. Specifically, we first construct a class prototype to select the patches that are likely to contain the objects of interest, namely class-relevant patches. Furthermore, we introduce a model that can quantitatively measure how suitable an arbitrary patch is as a counting exemplar. By applying this model to all the candidate patches, we can select the most suitable patches as exemplars for counting. Experimental results on a recent class-agnostic counting dataset, FSC-147, validate the effectiveness of our method. Code is available at https://github.com/cvlab-stonybrook/zero-shot-counting
Bayesian Generational Population-Based Training
Jul 19, 2022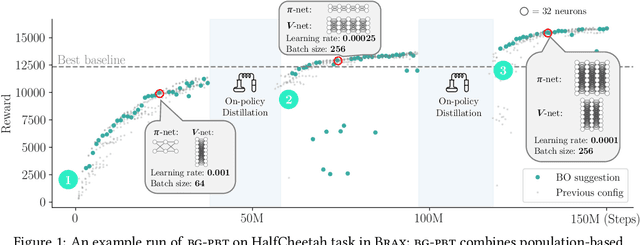

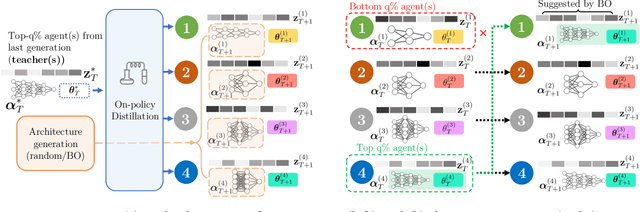
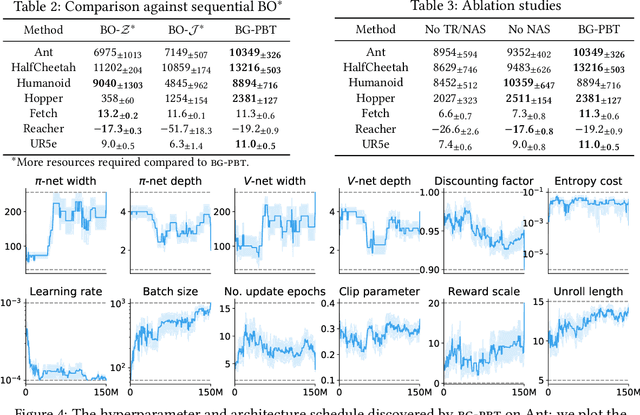
Reinforcement learning (RL) offers the potential for training generally capable agents that can interact autonomously in the real world. However, one key limitation is the brittleness of RL algorithms to core hyperparameters and network architecture choice. Furthermore, non-stationarities such as evolving training data and increased agent complexity mean that different hyperparameters and architectures may be optimal at different points of training. This motivates AutoRL, a class of methods seeking to automate these design choices. One prominent class of AutoRL methods is Population-Based Training (PBT), which have led to impressive performance in several large scale settings. In this paper, we introduce two new innovations in PBT-style methods. First, we employ trust-region based Bayesian Optimization, enabling full coverage of the high-dimensional mixed hyperparameter search space. Second, we show that using a generational approach, we can also learn both architectures and hyperparameters jointly on-the-fly in a single training run. Leveraging the new highly parallelizable Brax physics engine, we show that these innovations lead to large performance gains, significantly outperforming the tuned baseline while learning entire configurations on the fly. Code is available at https://github.com/xingchenwan/bgpbt.
Confident Sinkhorn Allocation for Pseudo-Labeling
Jun 13, 2022
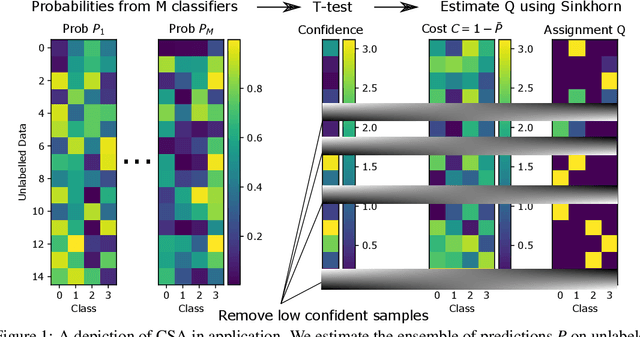
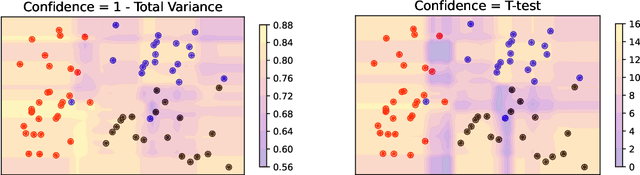
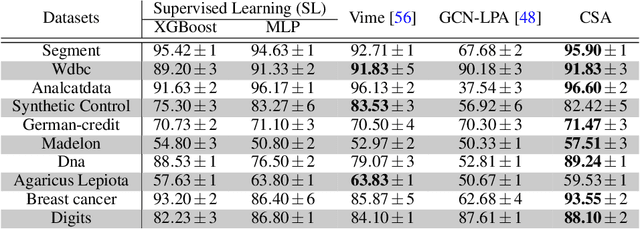
Semi-supervised learning is a critical tool in reducing machine learning's dependence on labeled data. It has, however, been applied primarily to image and language data, by exploiting the inherent spatial and semantic structure therein. These methods do not apply to tabular data because these domain structures are not available. Existing pseudo-labeling (PL) methods can be effective for tabular data but are vulnerable to noise samples and to greedy assignments given a predefined threshold which is unknown. This paper addresses this problem by proposing a Confident Sinkhorn Allocation (CSA), which assigns labels to only samples with high confidence scores and learns the best label allocation via optimal transport. CSA outperforms the current state-of-the-art in this practically important area.