 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAVA: Scalable Learning-Agnostic Data Valuation
Paper and Code
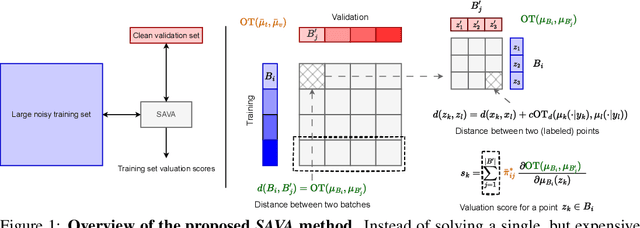

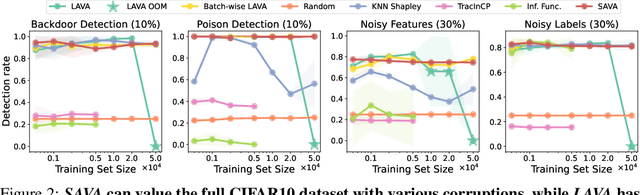
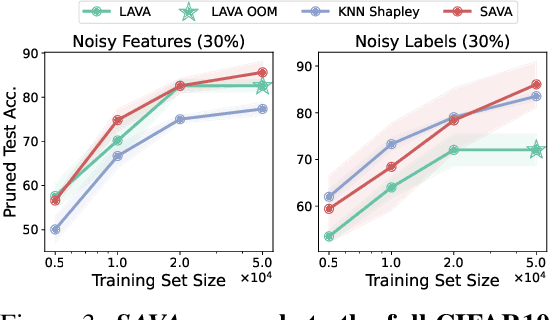
Selecting suitable data for training machine learning models is crucial since large, web-scraped, real datasets contain noisy artifacts that affect the quality and relevance of individual data points. These artifacts will impact the performance and generalization of the model. We formulate this problem as a data valuation task, assigning a value to data points in the training set according to how similar or dissimilar they are to a clean and curated validation set. Recently, LAVA (Just et al. 2023) successfully demonstrated the use of optimal transport (OT) between a large noisy training dataset and a clean validation set, to value training data efficiently, without the dependency on model performance. However, the LAVA algorithm requires the whole dataset as an input, this limits its application to large datasets. Inspired by the scalability of stochastic (gradient) approaches which carry out computations on batches of data points instead of the entire dataset, we analogously propose SAVA, a scalable variant of LAVA with its computation on batches of data points. Intuitively, SAVA follows the same scheme as LAVA which leverages the hierarchically defined OT for data valuation. However, while LAVA processes the whole dataset, SAVA divides the dataset into batches of data points, and carries out the OT problem computation on those batches. We perform extensive experiments, to demonstrate that SAVA can scale to large datasets with millions of data points and doesn't trade off data valuation performance.