 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfident Sinkhorn Allocation for Pseudo-Labeling
Paper and Code

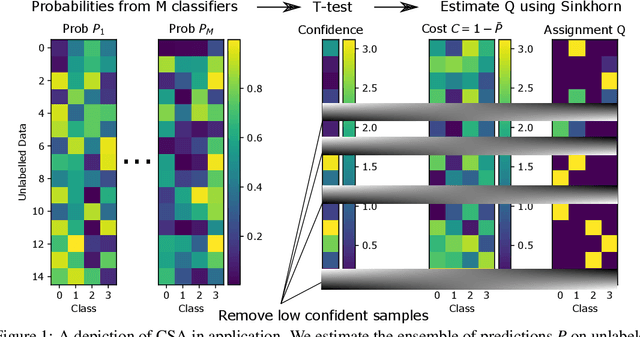
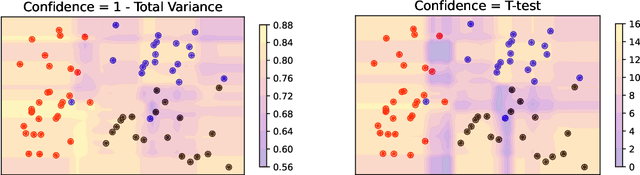
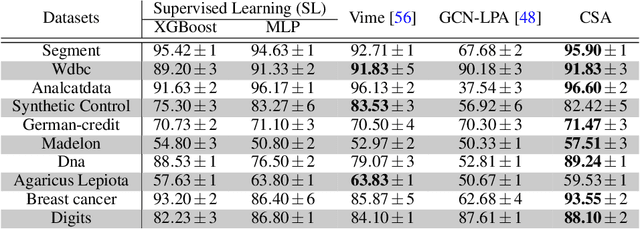
Semi-supervised learning is a critical tool in reducing machine learning's dependence on labeled data. It has, however, been applied primarily to image and language data, by exploiting the inherent spatial and semantic structure therein. These methods do not apply to tabular data because these domain structures are not available. Existing pseudo-labeling (PL) methods can be effective for tabular data but are vulnerable to noise samples and to greedy assignments given a predefined threshold which is unknown. This paper addresses this problem by proposing a Confident Sinkhorn Allocation (CSA), which assigns labels to only samples with high confidence scores and learns the best label allocation via optimal transport. CSA outperforms the current state-of-the-art in this practically important area.