 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfident Sinkhorn Allocation for Pseudo-Labeling
Jun 13, 2022
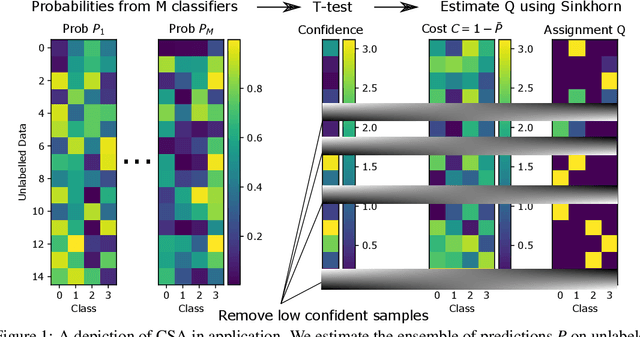
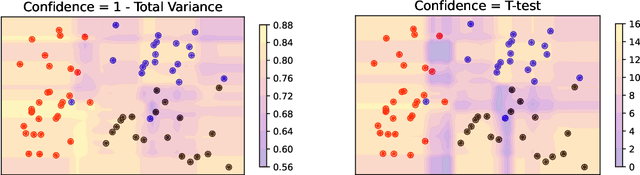
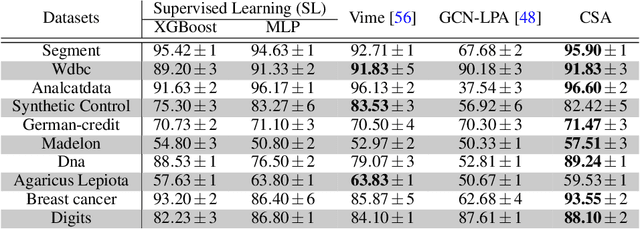
Semi-supervised learning is a critical tool in reducing machine learning's dependence on labeled data. It has, however, been applied primarily to image and language data, by exploiting the inherent spatial and semantic structure therein. These methods do not apply to tabular data because these domain structures are not available. Existing pseudo-labeling (PL) methods can be effective for tabular data but are vulnerable to noise samples and to greedy assignments given a predefined threshold which is unknown. This paper addresses this problem by proposing a Confident Sinkhorn Allocation (CSA), which assigns labels to only samples with high confidence scores and learns the best label allocation via optimal transport. CSA outperforms the current state-of-the-art in this practically important area.
Tag Prediction at Flickr: a View from the Darkroom
Dec 19, 2017

Automated photo tagging has established itself as one of the most compelling applications of deep learning. While deep convolutional neural networks have repeatedly demonstrated top performance on standard datasets for classification, there are a number of often overlooked but important considerations when deploying this technology in a real-world scenario. In this paper, we present our efforts in developing a large-scale photo tagging system for Flickr photo search. We discuss topics including how to 1) select the tags that matter most to our users; 2) develop lightweight, high-performance models for tag prediction; and 3) leverage the power of large amounts of noisy data for training. Our results demonstrate that, for real-world datasets, training exclusively with this noisy data yields performance on par with the standard paradigm of first pre-training on clean data and then fine-tuning. In addition, we observe that the models trained with user-generated data can yield better fine-tuning results when a small amount of clean data is available. As such, we advocate for the approach of harnessing user-generated data in large-scale systems.
MemexQA: Visual Memex Question Answering
Aug 04, 2017


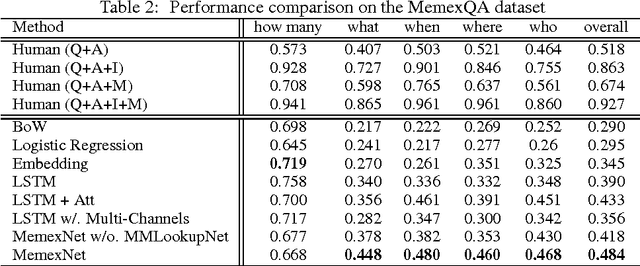
This paper proposes a new task, MemexQA: given a collection of photos or videos from a user, the goal is to automatically answer questions that help users recover their memory about events captured in the collection. Towards solving the task, we 1) present the MemexQA dataset, a large, realistic multimodal dataset consisting of real personal photos and crowd-sourced questions/answers, 2) propose MemexNet, a unified, end-to-end trainable network architecture for image, text and video question answering. Experimental results on the MemexQA dataset demonstrate that MemexNet outperforms strong baselines and yields the state-of-the-art on this novel and challenging task. The promising results on TextQA and VideoQA suggest MemexNet's efficacy and scalability across various QA tasks.