 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNonprehensile Riemannian Motion Predictive Control
Nov 15, 2021



Nonprehensile manipulation involves long horizon underactuated object interactions and physical contact with different objects that can inherently introduce a high degree of uncertainty. In this work, we introduce a novel Real-to-Sim reward analysis technique, called Riemannian Motion Predictive Control (RMPC), to reliably imagine and predict the outcome of taking possible actions for a real robotic platform. Our proposed RMPC benefits from Riemannian motion policy and second order dynamic model to compute the acceleration command and control the robot at every location on the surface. Our approach creates a 3D object-level recomposed model of the real scene where we can simulate the effect of different trajectories. We produce a closed-loop controller to reactively push objects in a continuous action space. We evaluate the performance of our RMPC approach by conducting experiments on a real robot platform as well as simulation and compare against several baselines. We observe that RMPC is robust in cluttered as well as occluded environments and outperforms the baselines.
Scene Recomposition by Learning-based ICP
Dec 13, 2018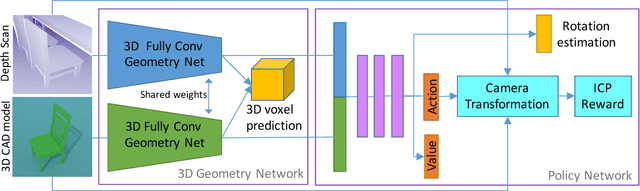


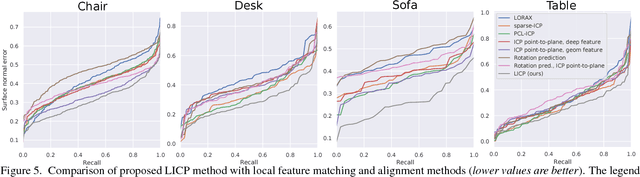
By moving a depth sensor around a room, we compute a 3D CAD model of the environment, capturing the room shape and contents such as chairs, desks, sofas, and tables. Rather than reconstructing geometry, we match, place, and align each object in the scene to thousands of CAD models of objects. In addition to the end-to-end system, the key technical contribution is a novel approach for aligning CAD models to 3D scans, based on deep reinforcement learning. This approach, which we call Learning-based ICP, outperforms prior ICP methods in the literature, by learning the best points to match and conditioning on object viewpoint. LICP learns to align using only synthetic data and does not require ground-truth annotation of object pose or keypoint pair matching in real scene scans. While LICP is trained on synthetic data and without 3D real scene annotations, it outperforms both learned local deep feature matching and geometric based alignment methods in real scenes. Proposed method is evaluated on publicly available real scenes datasets of SceneNN and ScanNet as well as synthetic scenes of SUNCG. High quality results are demonstrated on a range of real world scenes, with robustness to clutter, viewpoint, and occlusion.
VISER: Visual Self-Regularization
Feb 07, 2018
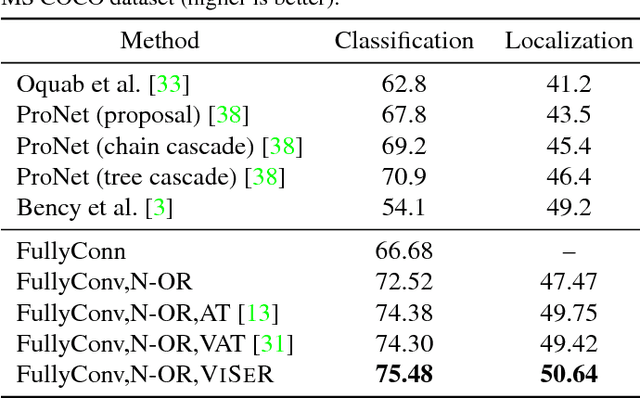


In this work, we propose the use of large set of unlabeled images as a source of regularization data for learning robust visual representation. Given a visual model trained by a labeled dataset in a supervised fashion, we augment our training samples by incorporating large number of unlabeled data and train a semi-supervised model. We demonstrate that our proposed learning approach leverages an abundance of unlabeled images and boosts the visual recognition performance which alleviates the need to rely on large labeled datasets for learning robust representation. To increment the number of image instances needed to learn robust visual models in our approach, each labeled image propagates its label to its nearest unlabeled image instances. These retrieved unlabeled images serve as local perturbations of each labeled image to perform Visual Self-Regularization (VISER). To retrieve such visual self regularizers, we compute the cosine similarity in a semantic space defined by the penultimate layer in a fully convolutional neural network. We use the publicly available Yahoo Flickr Creative Commons 100M dataset as the source of our unlabeled image set and propose a distributed approximate nearest neighbor algorithm to make retrieval practical at that scale. Using the labeled instances and their regularizer samples we show that we significantly improve object categorization and localization performance on the MS COCO and Visual Genome datasets where objects appear in context.
Tag Prediction at Flickr: a View from the Darkroom
Dec 19, 2017
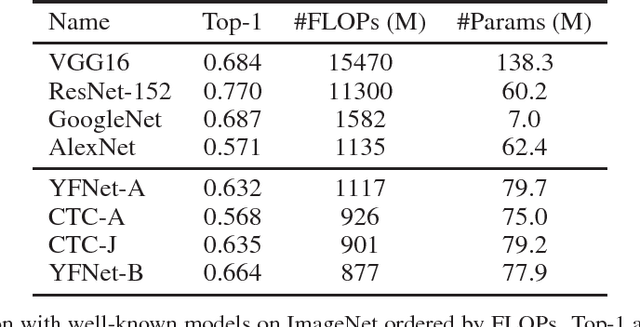

Automated photo tagging has established itself as one of the most compelling applications of deep learning. While deep convolutional neural networks have repeatedly demonstrated top performance on standard datasets for classification, there are a number of often overlooked but important considerations when deploying this technology in a real-world scenario. In this paper, we present our efforts in developing a large-scale photo tagging system for Flickr photo search. We discuss topics including how to 1) select the tags that matter most to our users; 2) develop lightweight, high-performance models for tag prediction; and 3) leverage the power of large amounts of noisy data for training. Our results demonstrate that, for real-world datasets, training exclusively with this noisy data yields performance on par with the standard paradigm of first pre-training on clean data and then fine-tuning. In addition, we observe that the models trained with user-generated data can yield better fine-tuning results when a small amount of clean data is available. As such, we advocate for the approach of harnessing user-generated data in large-scale systems.
IM2CAD
Apr 24, 2017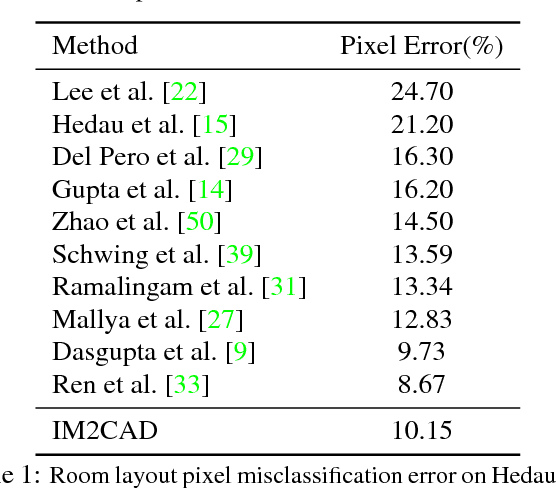

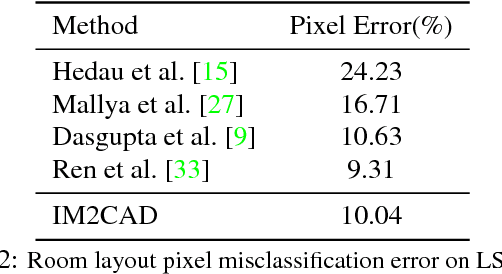
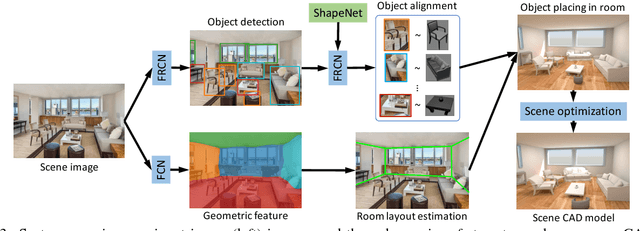
Given a single photo of a room and a large database of furniture CAD models, our goal is to reconstruct a scene that is as similar as possible to the scene depicted in the photograph, and composed of objects drawn from the database. We present a completely automatic system to address this IM2CAD problem that produces high quality results on challenging imagery from interior home design and remodeling websites. Our approach iteratively optimizes the placement and scale of objects in the room to best match scene renderings to the input photo, using image comparison metrics trained via deep convolutional neural nets. By operating jointly on the full scene at once, we account for inter-object occlusions. We also show the applicability of our method in standard scene understanding benchmarks where we obtain significant improvement.
Segment-Phrase Table for Semantic Segmentation, Visual Entailment and Paraphrasing
Sep 27, 2015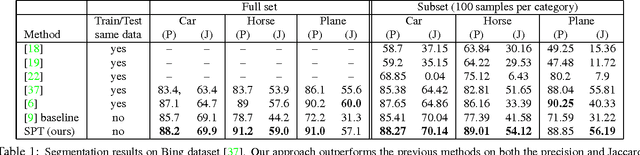



We introduce Segment-Phrase Table (SPT), a large collection of bijective associations between textual phrases and their corresponding segmentations. Leveraging recent progress in object recognition and natural language semantics, we show how we can successfully build a high-quality segment-phrase table using minimal human supervision. More importantly, we demonstrate the unique value unleashed by this rich bimodal resource, for both vision as well as natural language understanding. First, we show that fine-grained textual labels facilitate contextual reasoning that helps in satisfying semantic constraints across image segments. This feature enables us to achieve state-of-the-art segmentation results on benchmark datasets. Next, we show that the association of high-quality segmentations to textual phrases aids in richer semantic understanding and reasoning of these textual phrases. Leveraging this feature, we motivate the problem of visual entailment and visual paraphrasing, and demonstrate its utility on a large dataset.
Image Classification and Retrieval from User-Supplied Tags
Nov 25, 2014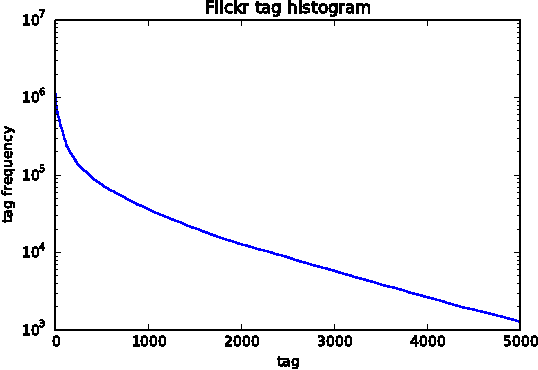
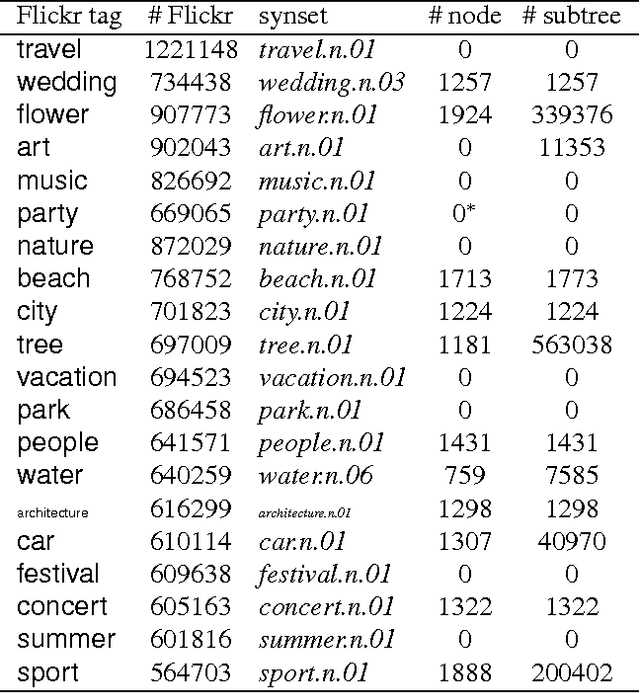
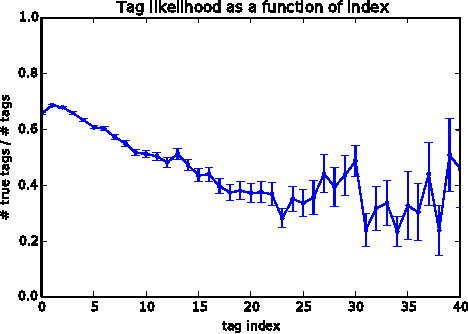
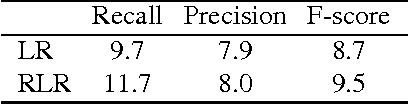
This paper proposes direct learning of image classification from user-supplied tags, without filtering. Each tag is supplied by the user who shared the image online. Enormous numbers of these tags are freely available online, and they give insight about the image categories important to users and to image classification. Our approach is complementary to the conventional approach of manual annotation, which is extremely costly. We analyze of the Flickr 100 Million Image dataset, making several useful observations about the statistics of these tags. We introduce a large-scale robust classification algorithm, in order to handle the inherent noise in these tags, and a calibration procedure to better predict objective annotations. We show that freely available, user-supplied tags can obtain similar or superior results to large databases of costly manual annotations.