 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Embeddings for Product Visual Search with Triplet Loss and Online Sampling
Oct 10, 2018
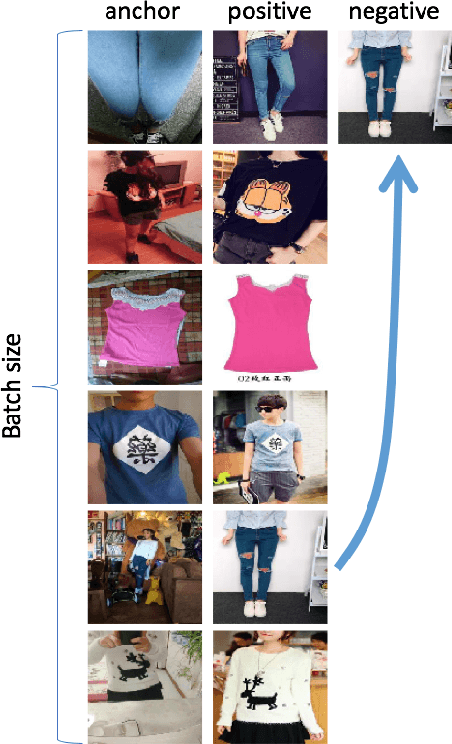
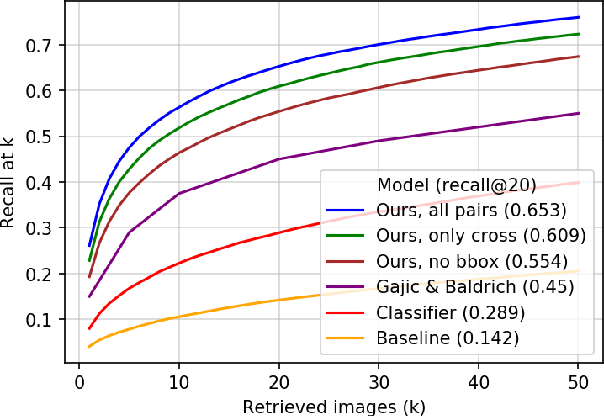
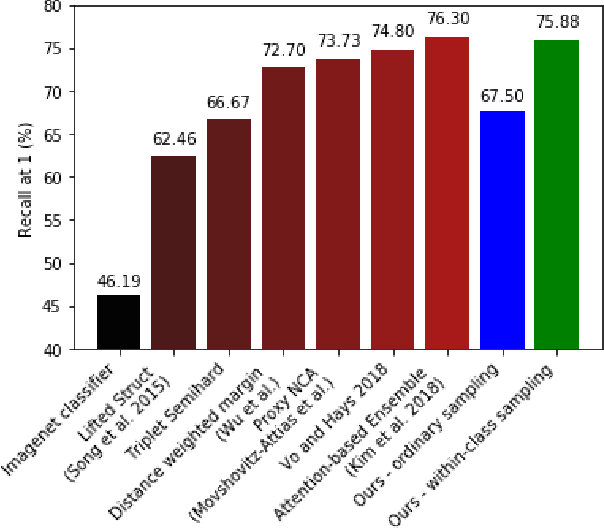
In this paper, we propose learning an embedding function for content-based image retrieval within the e-commerce domain using the triplet loss and an online sampling method that constructs triplets from within a minibatch. We compare our method to several strong baselines as well as recent works on the DeepFashion and Stanford Online Product datasets. Our approach significantly outperforms the state-of-the-art on the DeepFashion dataset. With a modification to favor sampling minibatches from a single product category, the same approach demonstrates competitive results when compared to the state-of-the-art for the Stanford Online Products dataset.
VISER: Visual Self-Regularization
Feb 07, 2018
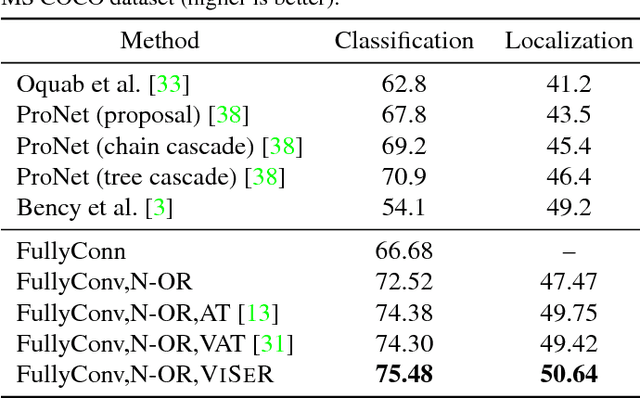


In this work, we propose the use of large set of unlabeled images as a source of regularization data for learning robust visual representation. Given a visual model trained by a labeled dataset in a supervised fashion, we augment our training samples by incorporating large number of unlabeled data and train a semi-supervised model. We demonstrate that our proposed learning approach leverages an abundance of unlabeled images and boosts the visual recognition performance which alleviates the need to rely on large labeled datasets for learning robust representation. To increment the number of image instances needed to learn robust visual models in our approach, each labeled image propagates its label to its nearest unlabeled image instances. These retrieved unlabeled images serve as local perturbations of each labeled image to perform Visual Self-Regularization (VISER). To retrieve such visual self regularizers, we compute the cosine similarity in a semantic space defined by the penultimate layer in a fully convolutional neural network. We use the publicly available Yahoo Flickr Creative Commons 100M dataset as the source of our unlabeled image set and propose a distributed approximate nearest neighbor algorithm to make retrieval practical at that scale. Using the labeled instances and their regularizer samples we show that we significantly improve object categorization and localization performance on the MS COCO and Visual Genome datasets where objects appear in context.
The New Modality: Emoji Challenges in Prediction, Anticipation, and Retrieval
Feb 02, 2018
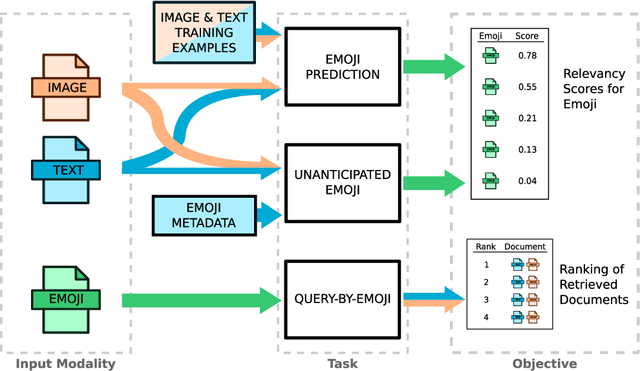
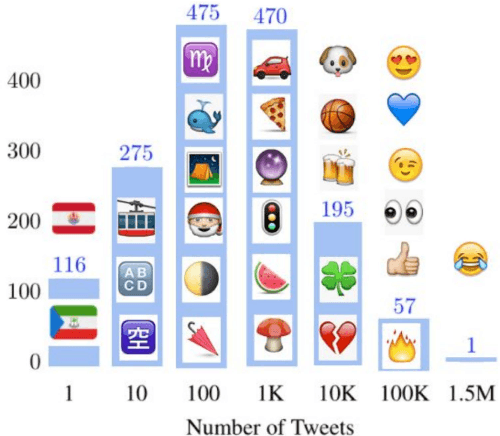
Over the past decade, emoji have emerged as a new and widespread form of digital communication, spanning diverse social networks and spoken languages. We propose to treat these ideograms as a new modality in their own right, distinct in their semantic structure from both the text in which they are often embedded as well as the images which they resemble. As a new modality, emoji present rich novel possibilities for representation and interaction. In this paper, we explore the challenges that arise naturally from considering the emoji modality through the lens of multimedia research. Specifically, the ways in which emoji can be related to other common modalities such as text and images. To do so, we first present a large scale dataset of real-world emoji usage collected from Twitter. This dataset contains examples of both text-emoji and image-emoji relationships. We present baseline results on the challenge of predicting emoji from both text and images, using state-of-the-art neural networks. Further, we offer a first consideration into the problem of how to account for new, unseen emoji - a relevant issue as the emoji vocabulary continues to expand on a yearly basis. Finally, we present results for multimedia retrieval using emoji as queries.
Tag Prediction at Flickr: a View from the Darkroom
Dec 19, 2017
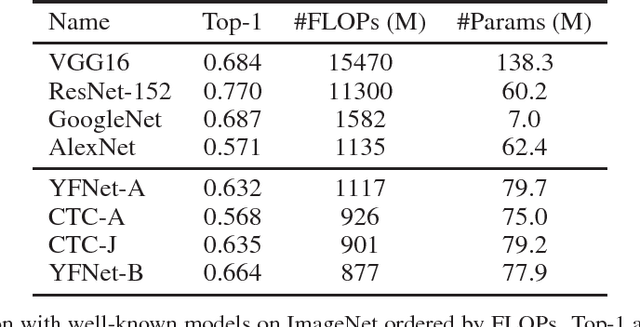

Automated photo tagging has established itself as one of the most compelling applications of deep learning. While deep convolutional neural networks have repeatedly demonstrated top performance on standard datasets for classification, there are a number of often overlooked but important considerations when deploying this technology in a real-world scenario. In this paper, we present our efforts in developing a large-scale photo tagging system for Flickr photo search. We discuss topics including how to 1) select the tags that matter most to our users; 2) develop lightweight, high-performance models for tag prediction; and 3) leverage the power of large amounts of noisy data for training. Our results demonstrate that, for real-world datasets, training exclusively with this noisy data yields performance on par with the standard paradigm of first pre-training on clean data and then fine-tuning. In addition, we observe that the models trained with user-generated data can yield better fine-tuning results when a small amount of clean data is available. As such, we advocate for the approach of harnessing user-generated data in large-scale systems.
Analog Sparse Approximation with Applications to Compressed Sensing
Nov 17, 2011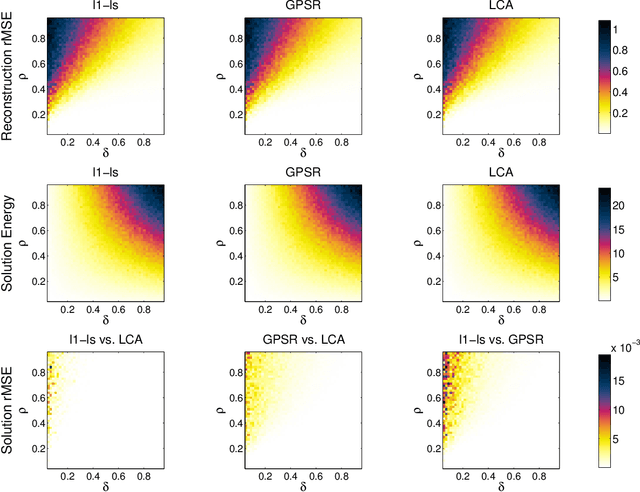
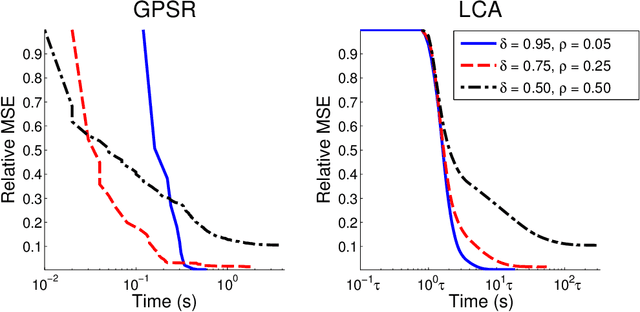
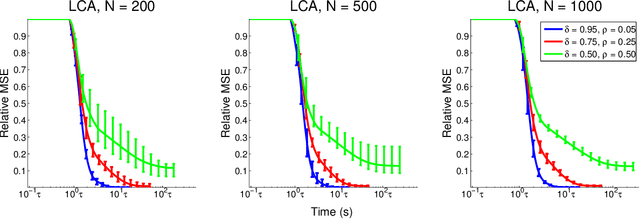
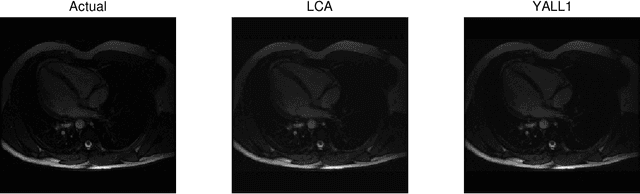
Recent research has shown that performance in signal processing tasks can often be significantly improved by using signal models based on sparse representations, where a signal is approximated using a small number of elements from a fixed dictionary. Unfortunately, inference in this model involves solving non-smooth optimization problems that are computationally expensive. While significant efforts have focused on developing digital algorithms specifically for this problem, these algorithms are inappropriate for many applications because of the time and power requirements necessary to solve large optimization problems. Based on recent work in computational neuroscience, we explore the potential advantages of continuous time dynamical systems for solving sparse approximation problems if they were implemented in analog VLSI. Specifically, in the simulated task of recovering synthetic and MRI data acquired via compressive sensing techniques, we show that these systems can potentially perform recovery at time scales of 10-20{\mu}s, supporting datarates of 50-100 kHz (orders of magnitude faster that digital algorithms). Furthermore, we show analytically that a wide range of sparse approximation problems can be solved in the same basic architecture, including approximate $\ell^p$ norms, modified $\ell^1$ norms, re-weighted $\ell^1$ and $\ell^2$, the block $\ell^1$ norm and classic Tikhonov regularization.