 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage to Video Domain Adaptation Using Web Supervision
Aug 05, 2019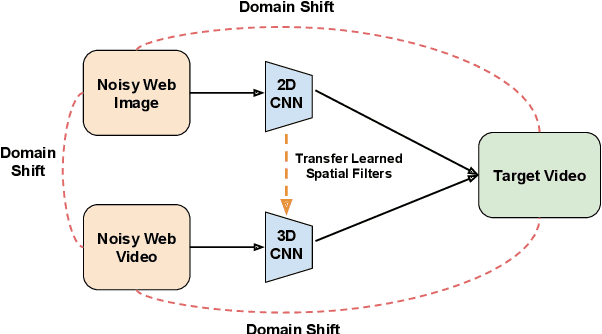
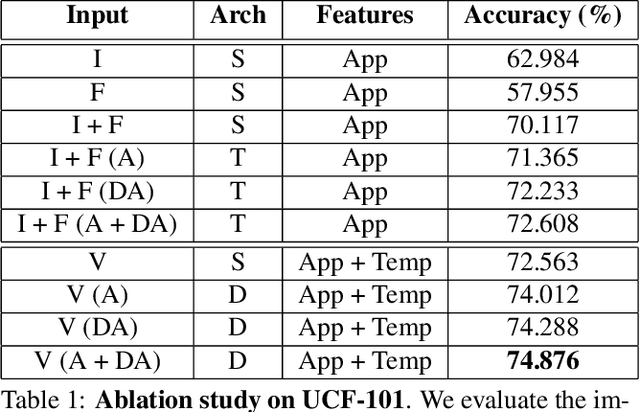
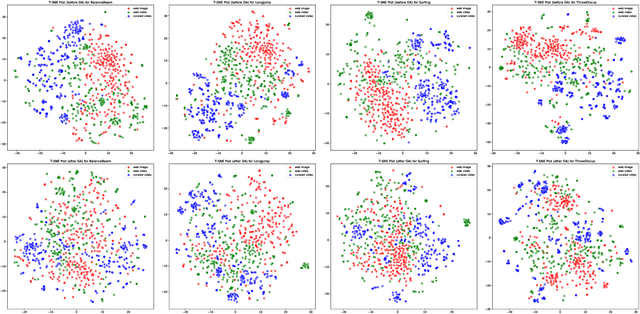

Training deep neural networks typically requires large amounts of labeled data which may be scarce or expensive to obtain for a particular target domain. As an alternative, we can leverage webly-supervised data (i.e. results from a public search engine) which are relatively plentiful but may contain noisy results. In this work, we propose a novel two-stage approach to learn a video classifier using webly-supervised data. We argue that learning appearance features and then temporal features sequentially, rather than simultaneously, is an easier optimization for this task. We show this by first learning an image model from web images, which is used to initialize and train a video model. Our model applies domain adaptation to account for potential domain shift present between the source domain (webly-supervised data) and target domain and also accounts for noise by adding a novel attention component. We report results competitive with state-of-the-art for webly-supervised approaches on UCF-101 (while simplifying the training process) and also evaluate on Kinetics for comparison.
Learning Embeddings for Product Visual Search with Triplet Loss and Online Sampling
Oct 10, 2018
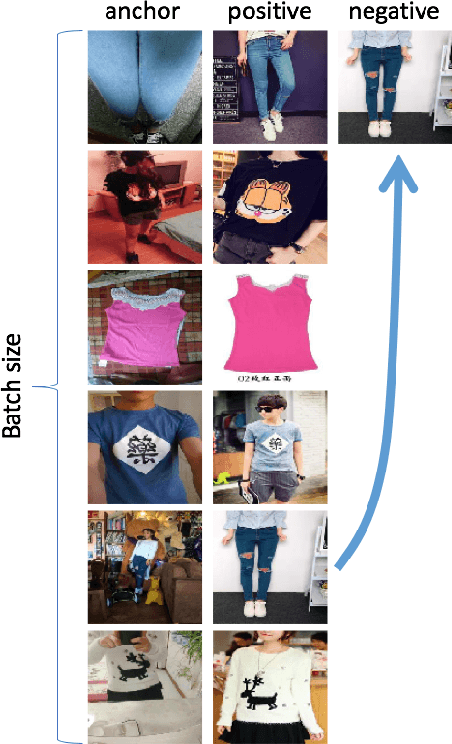
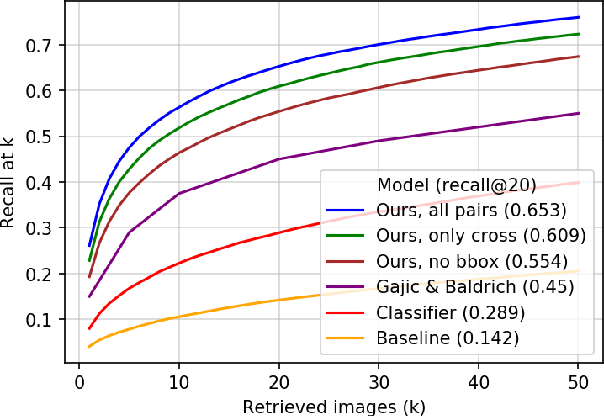
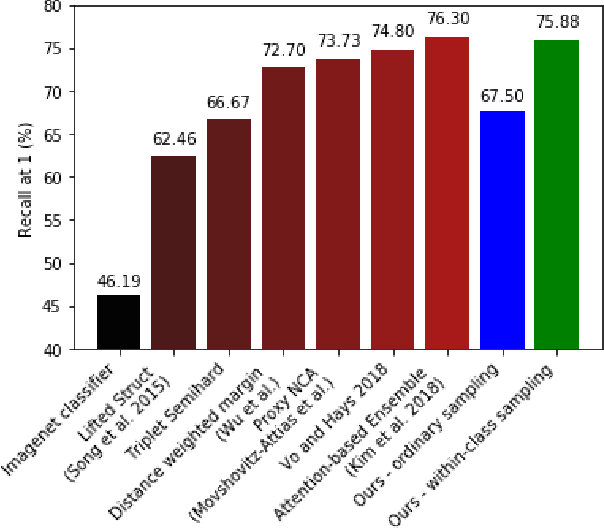
In this paper, we propose learning an embedding function for content-based image retrieval within the e-commerce domain using the triplet loss and an online sampling method that constructs triplets from within a minibatch. We compare our method to several strong baselines as well as recent works on the DeepFashion and Stanford Online Product datasets. Our approach significantly outperforms the state-of-the-art on the DeepFashion dataset. With a modification to favor sampling minibatches from a single product category, the same approach demonstrates competitive results when compared to the state-of-the-art for the Stanford Online Products dataset.
Bounding the Probability of Error for High Precision Recognition
Jul 02, 2009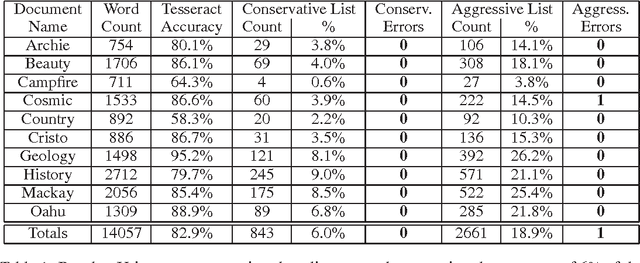
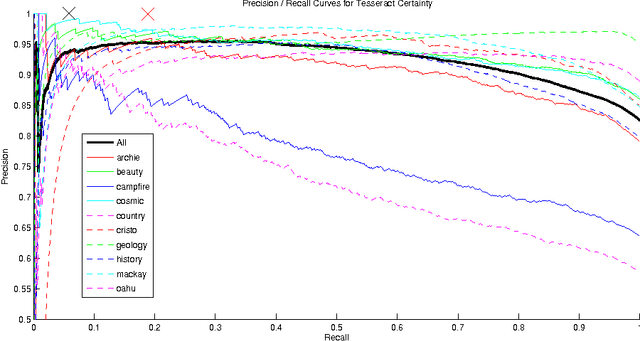
We consider models for which it is important, early in processing, to estimate some variables with high precision, but perhaps at relatively low rates of recall. If some variables can be identified with near certainty, then they can be conditioned upon, allowing further inference to be done efficiently. Specifically, we consider optical character recognition (OCR) systems that can be bootstrapped by identifying a subset of correctly translated document words with very high precision. This "clean set" is subsequently used as document-specific training data. While many current OCR systems produce measures of confidence for the identity of each letter or word, thresholding these confidence values, even at very high values, still produces some errors. We introduce a novel technique for identifying a set of correct words with very high precision. Rather than estimating posterior probabilities, we bound the probability that any given word is incorrect under very general assumptions, using an approximate worst case analysis. As a result, the parameters of the model are nearly irrelevant, and we are able to identify a subset of words, even in noisy documents, of which we are highly confident. On our set of 10 documents, we are able to identify about 6% of the words on average without making a single error. This ability to produce word lists with very high precision allows us to use a family of models which depends upon such clean word lists.