 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTag Prediction at Flickr: a View from the Darkroom
Paper and Code
Dec 19, 2017
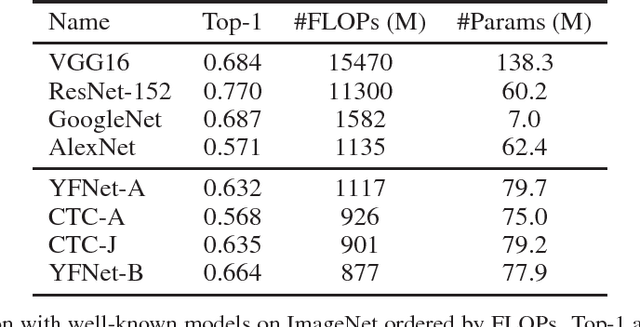

Automated photo tagging has established itself as one of the most compelling applications of deep learning. While deep convolutional neural networks have repeatedly demonstrated top performance on standard datasets for classification, there are a number of often overlooked but important considerations when deploying this technology in a real-world scenario. In this paper, we present our efforts in developing a large-scale photo tagging system for Flickr photo search. We discuss topics including how to 1) select the tags that matter most to our users; 2) develop lightweight, high-performance models for tag prediction; and 3) leverage the power of large amounts of noisy data for training. Our results demonstrate that, for real-world datasets, training exclusively with this noisy data yields performance on par with the standard paradigm of first pre-training on clean data and then fine-tuning. In addition, we observe that the models trained with user-generated data can yield better fine-tuning results when a small amount of clean data is available. As such, we advocate for the approach of harnessing user-generated data in large-scale systems.