 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Engine Optimization: A VLM and Agent Framework for Pinterest Acquisition Growth
Feb 03, 2026Large Language Models are fundamentally reshaping content discovery through AI-native search systems such as ChatGPT, Gemini, and Claude. Unlike traditional search engines that match keywords to documents, these systems infer user intent, synthesize multimodal evidence, and generate contextual answers directly on the search page, introducing a paradigm shift from Search Engine Optimization (SEO) to Generative Engine Optimization (GEO). For visual content platforms hosting billions of assets, this poses an acute challenge: individual images lack the semantic depth and authority signals that generative search prioritizes, risking disintermediation as user needs are satisfied in-place without site visits. We present Pinterest GEO, a production-scale framework that pioneers reverse search design: rather than generating generic image captions describing what content is, we fine-tune Vision-Language Models (VLMs) to predict what users would actually search for, augmented this with AI agents that mine real-time internet trends to capture emerging search demand. These VLM-generated queries then drive construction of semantically coherent Collection Pages via multimodal embeddings, creating indexable aggregations optimized for generative retrieval. Finally, we employ hybrid VLM and two-tower ANN architectures to build authority-aware interlinking structures that propagate signals across billions of visual assets. Deployed at scale across billions of images and tens of millions of collections, GEO delivers 20\% organic traffic growth contributing to multi-million monthly active user (MAU) growth, demonstrating a principled pathway for visual platforms to thrive in the generative search era.
Image Search with Text Feedback by Additive Attention Compositional Learning
Mar 08, 2022
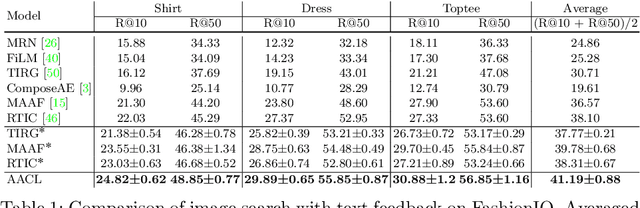
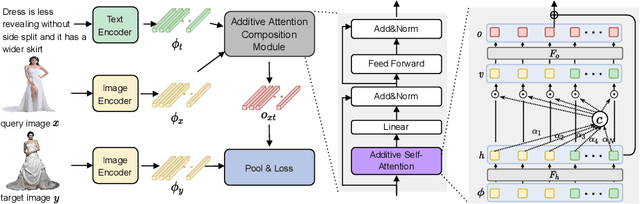
Effective image retrieval with text feedback stands to impact a range of real-world applications, such as e-commerce. Given a source image and text feedback that describes the desired modifications to that image, the goal is to retrieve the target images that resemble the source yet satisfy the given modifications by composing a multi-modal (image-text) query. We propose a novel solution to this problem, Additive Attention Compositional Learning (AACL), that uses a multi-modal transformer-based architecture and effectively models the image-text contexts. Specifically, we propose a novel image-text composition module based on additive attention that can be seamlessly plugged into deep neural networks. We also introduce a new challenging benchmark derived from the Shopping100k dataset. AACL is evaluated on three large-scale datasets (FashionIQ, Fashion200k, and Shopping100k), each with strong baselines. Extensive experiments show that AACL achieves new state-of-the-art results on all three datasets.
Modality-Agnostic Attention Fusion for visual search with text feedback
Jun 30, 2020

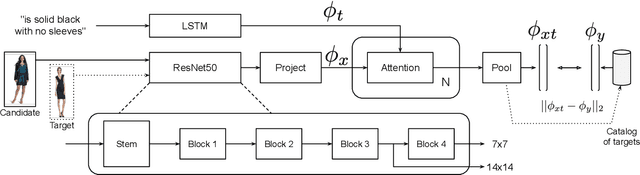
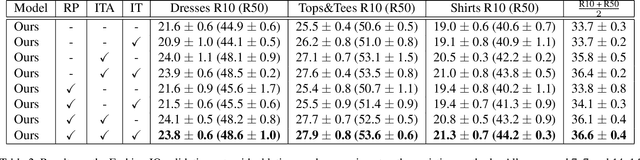
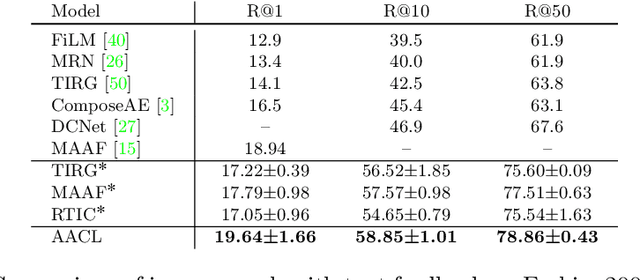
Image retrieval with natural language feedback offers the promise of catalog search based on fine-grained visual features that go beyond objects and binary attributes, facilitating real-world applications such as e-commerce. Our Modality-Agnostic Attention Fusion (MAAF) model combines image and text features and outperforms existing approaches on two visual search with modifying phrase datasets, Fashion IQ and CSS, and performs competitively on a dataset with only single-word modifications, Fashion200k. We also introduce two new challenging benchmarks adapted from Birds-to-Words and Spot-the-Diff, which provide new settings with rich language inputs, and we show that our approach without modification outperforms strong baselines. To better understand our model, we conduct detailed ablations on Fashion IQ and provide visualizations of the surprising phenomenon of words avoiding "attending" to the image region they refer to.
Image Captioning: Transforming Objects into Words
Jun 14, 2019
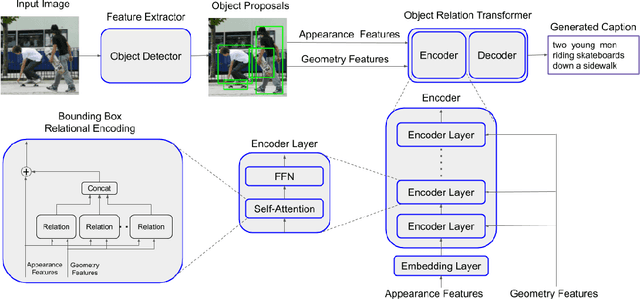
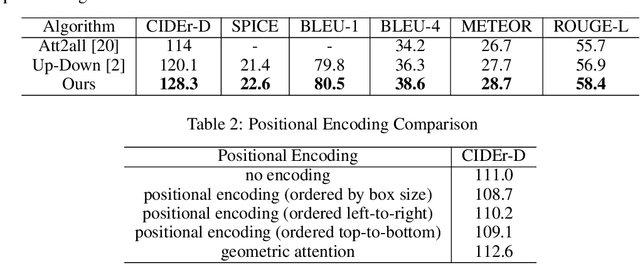
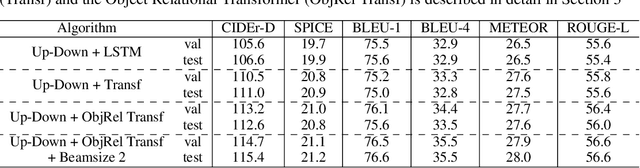
Image captioning models typically follow an encoder-decoder architecture which uses abstract image feature vectors as input to the encoder. One of the most successful algorithms uses feature vectors extracted from the region proposals obtained from an object detector. In this work we introduce the Object Relation Transformer, that builds upon this approach by explicitly incorporating information about the spatial relationship between input detected objects through geometric attention. Quantitative and qualitative results demonstrate the importance of such geometric attention for image captioning, leading to improvements on all common captioning metrics on the MS-COCO dataset.
Tag Prediction at Flickr: a View from the Darkroom
Dec 19, 2017
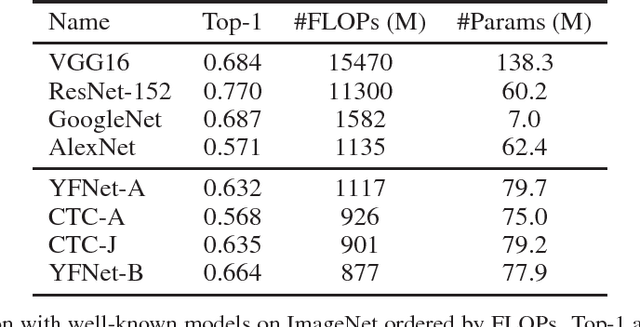

Automated photo tagging has established itself as one of the most compelling applications of deep learning. While deep convolutional neural networks have repeatedly demonstrated top performance on standard datasets for classification, there are a number of often overlooked but important considerations when deploying this technology in a real-world scenario. In this paper, we present our efforts in developing a large-scale photo tagging system for Flickr photo search. We discuss topics including how to 1) select the tags that matter most to our users; 2) develop lightweight, high-performance models for tag prediction; and 3) leverage the power of large amounts of noisy data for training. Our results demonstrate that, for real-world datasets, training exclusively with this noisy data yields performance on par with the standard paradigm of first pre-training on clean data and then fine-tuning. In addition, we observe that the models trained with user-generated data can yield better fine-tuning results when a small amount of clean data is available. As such, we advocate for the approach of harnessing user-generated data in large-scale systems.
A Large Contextual Dataset for Classification, Detection and Counting of Cars with Deep Learning
Sep 14, 2016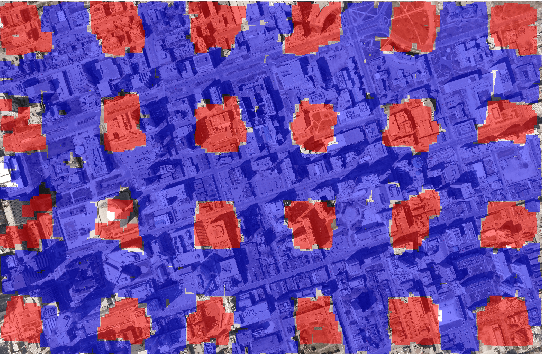



We have created a large diverse set of cars from overhead images, which are useful for training a deep learner to binary classify, detect and count them. The dataset and all related material will be made publically available. The set contains contextual matter to aid in identification of difficult targets. We demonstrate classification and detection on this dataset using a neural network we call ResCeption. This network combines residual learning with Inception-style layers and is used to count cars in one look. This is a new way to count objects rather than by localization or density estimation. It is fairly accurate, fast and easy to implement. Additionally, the counting method is not car or scene specific. It would be easy to train this method to count other kinds of objects and counting over new scenes requires no extra set up or assumptions about object locations.
Large-Scale Deep Learning on the YFCC100M Dataset
Feb 11, 2015


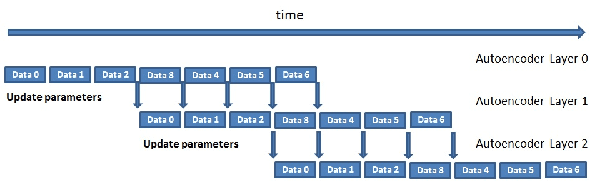
We present a work-in-progress snapshot of learning with a 15 billion parameter deep learning network on HPC architectures applied to the largest publicly available natural image and video dataset released to-date. Recent advancements in unsupervised deep neural networks suggest that scaling up such networks in both model and training dataset size can yield significant improvements in the learning of concepts at the highest layers. We train our three-layer deep neural network on the Yahoo! Flickr Creative Commons 100M dataset. The dataset comprises approximately 99.2 million images and 800,000 user-created videos from Yahoo's Flickr image and video sharing platform. Training of our network takes eight days on 98 GPU nodes at the High Performance Computing Center at Lawrence Livermore National Laboratory. Encouraging preliminary results and future research directions are presented and discussed.