 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModality-Agnostic Attention Fusion for visual search with text feedback
Paper and Code


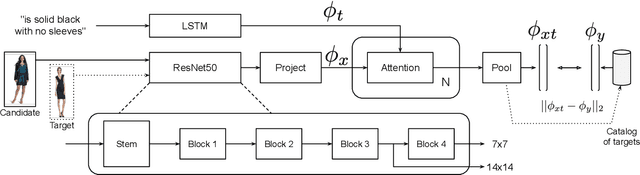
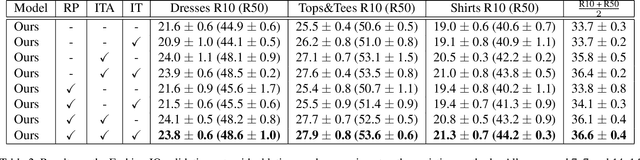
Image retrieval with natural language feedback offers the promise of catalog search based on fine-grained visual features that go beyond objects and binary attributes, facilitating real-world applications such as e-commerce. Our Modality-Agnostic Attention Fusion (MAAF) model combines image and text features and outperforms existing approaches on two visual search with modifying phrase datasets, Fashion IQ and CSS, and performs competitively on a dataset with only single-word modifications, Fashion200k. We also introduce two new challenging benchmarks adapted from Birds-to-Words and Spot-the-Diff, which provide new settings with rich language inputs, and we show that our approach without modification outperforms strong baselines. To better understand our model, we conduct detailed ablations on Fashion IQ and provide visualizations of the surprising phenomenon of words avoiding "attending" to the image region they refer to.