 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Speech Denoising with Vector Space Projections
Apr 27, 2018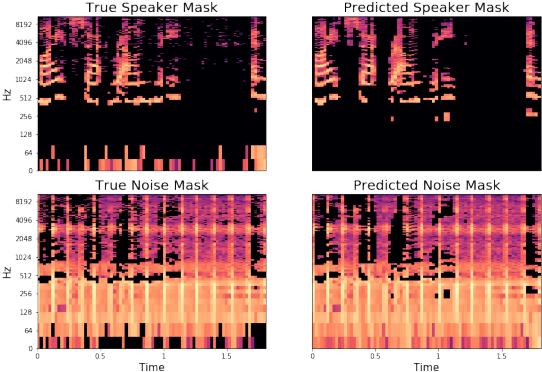
We propose an algorithm to denoise speakers from a single microphone in the presence of non-stationary and dynamic noise. Our approach is inspired by the recent success of neural network models separating speakers from other speakers and singers from instrumental accompaniment. Unlike prior art, we leverage embedding spaces produced with source-contrastive estimation, a technique derived from negative sampling techniques in natural language processing, while simultaneously obtaining a continuous inference mask. Our embedding space directly optimizes for the discrimination of speaker and noise by jointly modeling their characteristics. This space is generalizable in that it is not speaker or noise specific and is capable of denoising speech even if the model has not seen the speaker in the training set. Parameters are trained with dual objectives: one that promotes a selective bandpass filter that eliminates noise at time-frequency positions that exceed signal power, and another that proportionally splits time-frequency content between signal and noise. We compare to state of the art algorithms as well as traditional sparse non-negative matrix factorization solutions. The resulting algorithm avoids severe computational burden by providing a more intuitive and easily optimized approach, while achieving competitive accuracy.
Monaural Audio Speaker Separation with Source Contrastive Estimation
May 12, 2017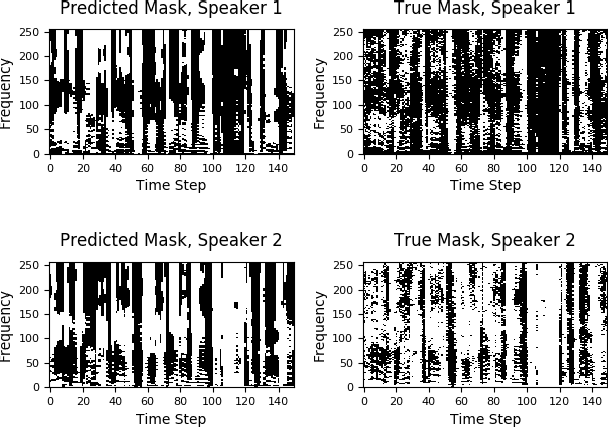
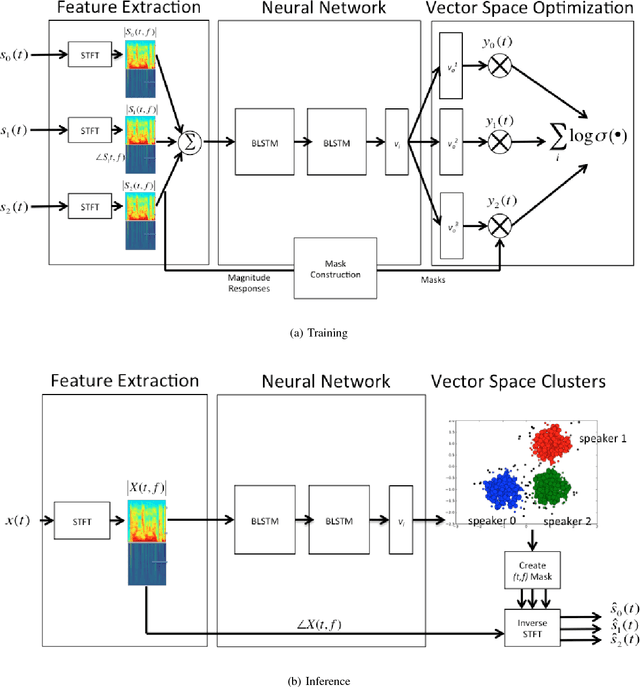
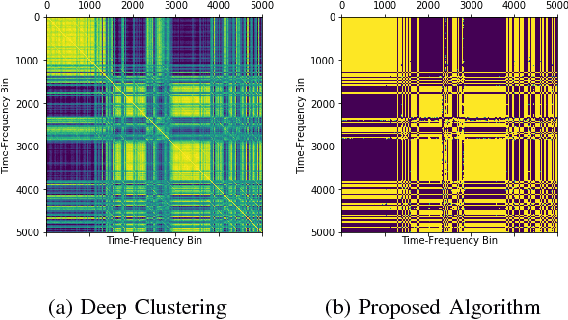
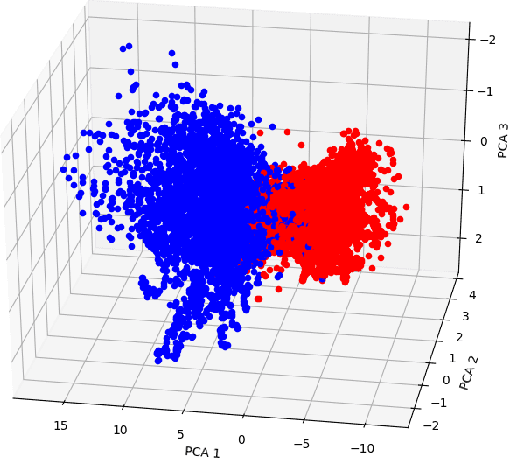
We propose an algorithm to separate simultaneously speaking persons from each other, the "cocktail party problem", using a single microphone. Our approach involves a deep recurrent neural networks regression to a vector space that is descriptive of independent speakers. Such a vector space can embed empirically determined speaker characteristics and is optimized by distinguishing between speaker masks. We call this technique source-contrastive estimation. The methodology is inspired by negative sampling, which has seen success in natural language processing, where an embedding is learned by correlating and de-correlating a given input vector with output weights. Although the matrix determined by the output weights is dependent on a set of known speakers, we only use the input vectors during inference. Doing so will ensure that source separation is explicitly speaker-independent. Our approach is similar to recent deep neural network clustering and permutation-invariant training research; we use weighted spectral features and masks to augment individual speaker frequencies while filtering out other speakers. We avoid, however, the severe computational burden of other approaches with our technique. Furthermore, by training a vector space rather than combinations of different speakers or differences thereof, we avoid the so-called permutation problem during training. Our algorithm offers an intuitive, computationally efficient response to the cocktail party problem, and most importantly boasts better empirical performance than other current techniques.
Sampled Image Tagging and Retrieval Methods on User Generated Content
Dec 02, 2016



Traditional image tagging and retrieval algorithms have limited value as a result of being trained with heavily curated datasets. These limitations are most evident when arbitrary search words are used that do not intersect with training set labels. Weak labels from user generated content (UGC) found in the wild (e.g., Google Photos, FlickR, etc.) have an almost unlimited number of unique words in the metadata tags. Prior work on word embeddings successfully leveraged unstructured text with large vocabularies, and our proposed method seeks to apply similar cost functions to open source imagery. Specifically, we train a deep learning image tagging and retrieval system on large scale, user generated content (UGC) using sampling methods and joint optimization of word embeddings. By using the Yahoo! FlickR Creative Commons (YFCC100M) dataset, such an approach builds robustness to common unstructured data issues that include but are not limited to irrelevant tags, misspellings, multiple languages, polysemy, and tag imbalance. As a result, the final proposed algorithm will not only yield comparable results to state of the art in conventional image tagging, but will enable new capability to train algorithms on large, scale unstructured text in the YFCC100M dataset and outperform cited work in zero-shot capability.
Mapping Images to Sentiment Adjective Noun Pairs with Factorized Neural Nets
Nov 21, 2015
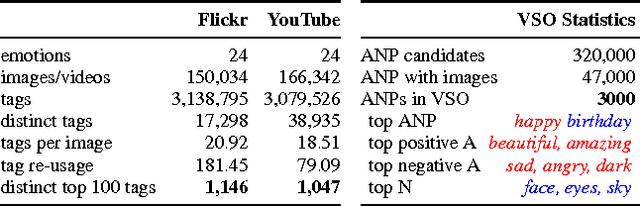

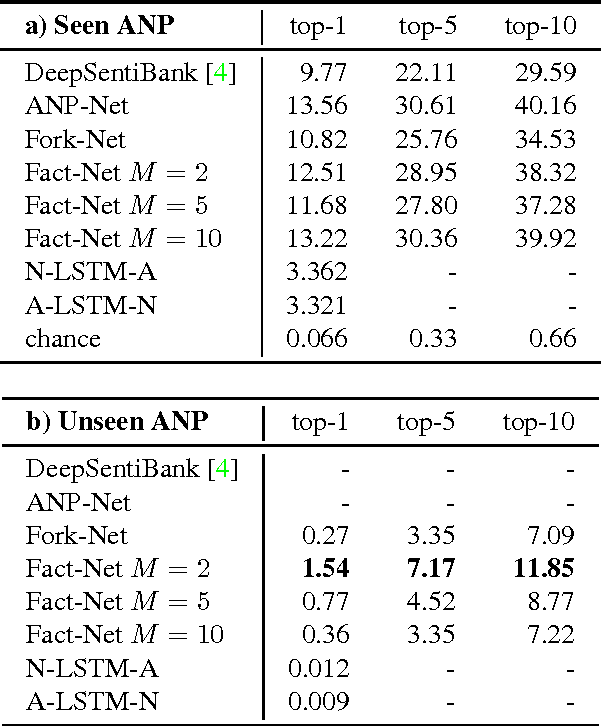
We consider the visual sentiment task of mapping an image to an adjective noun pair (ANP) such as "cute baby". To capture the two-factor structure of our ANP semantics as well as to overcome annotation noise and ambiguity, we propose a novel factorized CNN model which learns separate representations for adjectives and nouns but optimizes the classification performance over their product. Our experiments on the publicly available SentiBank dataset show that our model significantly outperforms not only independent ANP classifiers on unseen ANPs and on retrieving images of novel ANPs, but also image captioning models which capture word semantics from co-occurrence of natural text; the latter turn out to be surprisingly poor at capturing the sentiment evoked by pure visual experience. That is, our factorized ANP CNN not only trains better from noisy labels, generalizes better to new images, but can also expands the ANP vocabulary on its own.
Large-Scale Deep Learning on the YFCC100M Dataset
Feb 11, 2015


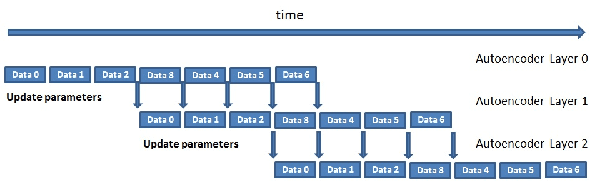
We present a work-in-progress snapshot of learning with a 15 billion parameter deep learning network on HPC architectures applied to the largest publicly available natural image and video dataset released to-date. Recent advancements in unsupervised deep neural networks suggest that scaling up such networks in both model and training dataset size can yield significant improvements in the learning of concepts at the highest layers. We train our three-layer deep neural network on the Yahoo! Flickr Creative Commons 100M dataset. The dataset comprises approximately 99.2 million images and 800,000 user-created videos from Yahoo's Flickr image and video sharing platform. Training of our network takes eight days on 98 GPU nodes at the High Performance Computing Center at Lawrence Livermore National Laboratory. Encouraging preliminary results and future research directions are presented and discussed.