 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the geometry of generalization and memorization in deep neural networks
May 30, 2021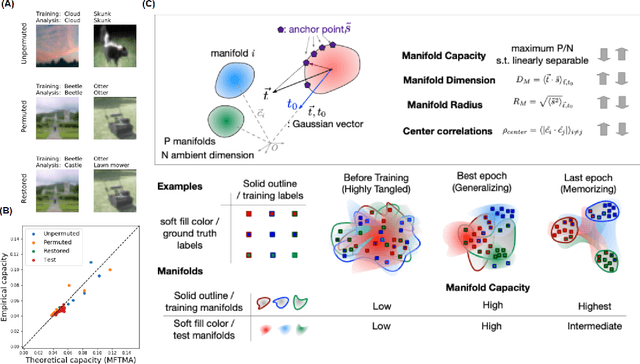
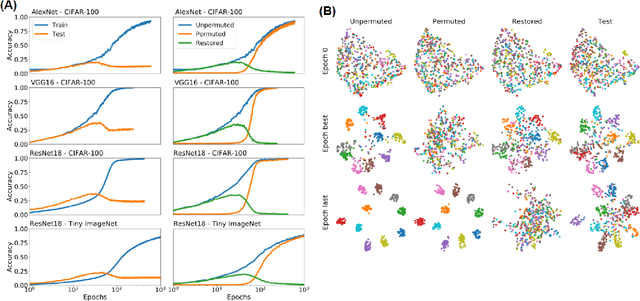
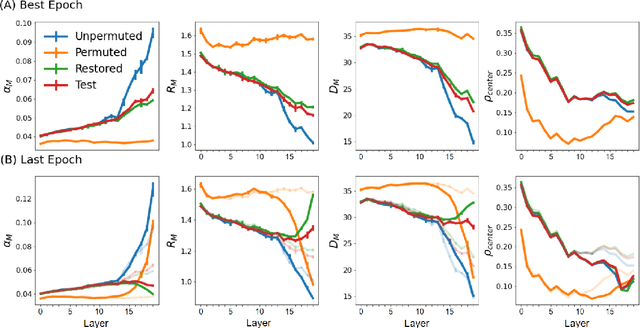
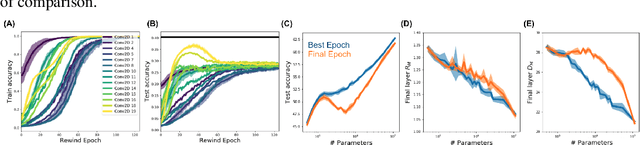
Understanding how large neural networks avoid memorizing training data is key to explaining their high generalization performance. To examine the structure of when and where memorization occurs in a deep network, we use a recently developed replica-based mean field theoretic geometric analysis method. We find that all layers preferentially learn from examples which share features, and link this behavior to generalization performance. Memorization predominately occurs in the deeper layers, due to decreasing object manifolds' radius and dimension, whereas early layers are minimally affected. This predicts that generalization can be restored by reverting the final few layer weights to earlier epochs before significant memorization occurred, which is confirmed by the experiments. Additionally, by studying generalization under different model sizes, we reveal the connection between the double descent phenomenon and the underlying model geometry. Finally, analytical analysis shows that networks avoid memorization early in training because close to initialization, the gradient contribution from permuted examples are small. These findings provide quantitative evidence for the structure of memorization across layers of a deep neural network, the drivers for such structure, and its connection to manifold geometric properties.
Generalization to Novel Objects using Prior Relational Knowledge
Jun 26, 2019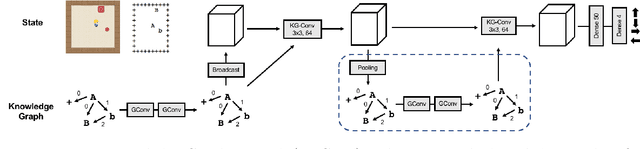
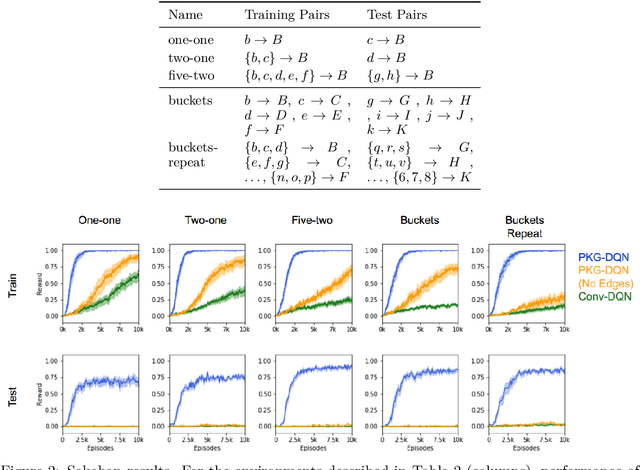
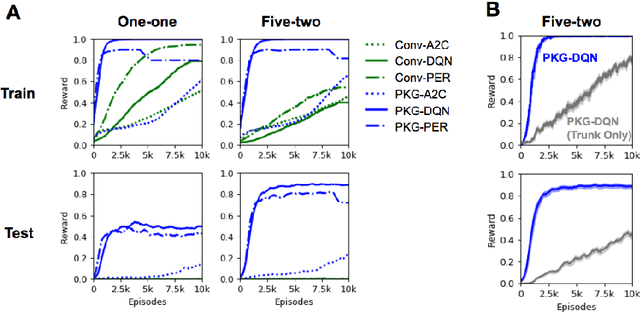

To solve tasks in new environments involving objects unseen during training, agents must reason over prior information about those objects and their relations. We introduce the Prior Knowledge Graph network, an architecture for combining prior information, structured as a knowledge graph, with a symbolic parsing of the visual scene, and demonstrate that this approach is able to apply learned relations to novel objects whereas the baseline algorithms fail. Ablation experiments show that the agents ground the knowledge graph relations to semantically-relevant behaviors. In both a Sokoban game and the more complex Pacman environment, our network is also more sample efficient than the baselines, reaching the same performance in 5-10x fewer episodes. Once the agents are trained with our approach, we can manipulate agent behavior by modifying the knowledge graph in semantically meaningful ways. These results suggest that our network provides a framework for agents to reason over structured knowledge graphs while still leveraging gradient based learning approaches.
Monaural Audio Speaker Separation with Source Contrastive Estimation
May 12, 2017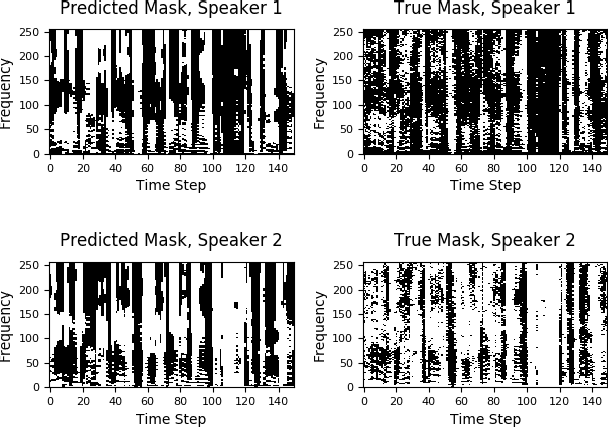
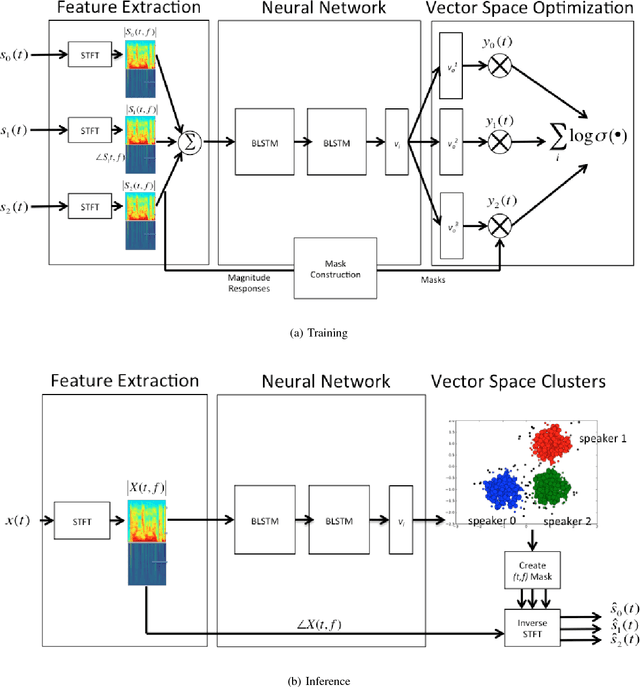
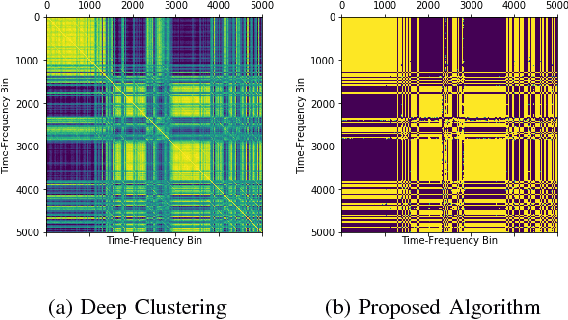
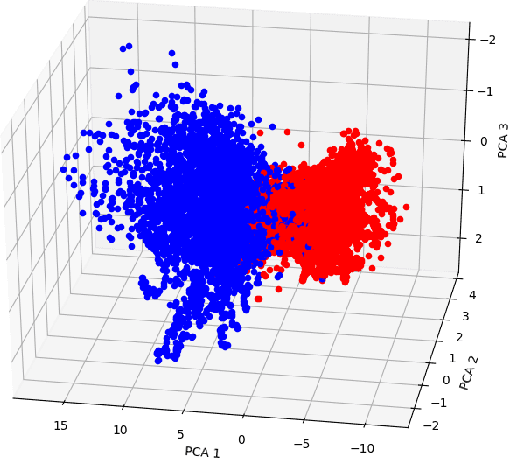
We propose an algorithm to separate simultaneously speaking persons from each other, the "cocktail party problem", using a single microphone. Our approach involves a deep recurrent neural networks regression to a vector space that is descriptive of independent speakers. Such a vector space can embed empirically determined speaker characteristics and is optimized by distinguishing between speaker masks. We call this technique source-contrastive estimation. The methodology is inspired by negative sampling, which has seen success in natural language processing, where an embedding is learned by correlating and de-correlating a given input vector with output weights. Although the matrix determined by the output weights is dependent on a set of known speakers, we only use the input vectors during inference. Doing so will ensure that source separation is explicitly speaker-independent. Our approach is similar to recent deep neural network clustering and permutation-invariant training research; we use weighted spectral features and masks to augment individual speaker frequencies while filtering out other speakers. We avoid, however, the severe computational burden of other approaches with our technique. Furthermore, by training a vector space rather than combinations of different speakers or differences thereof, we avoid the so-called permutation problem during training. Our algorithm offers an intuitive, computationally efficient response to the cocktail party problem, and most importantly boasts better empirical performance than other current techniques.