 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonaural Audio Speaker Separation with Source Contrastive Estimation
May 12, 2017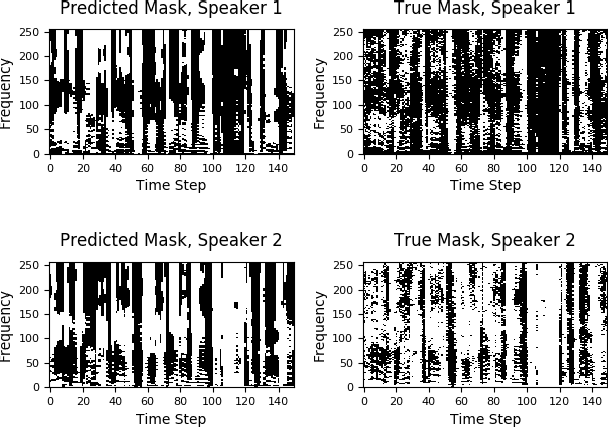
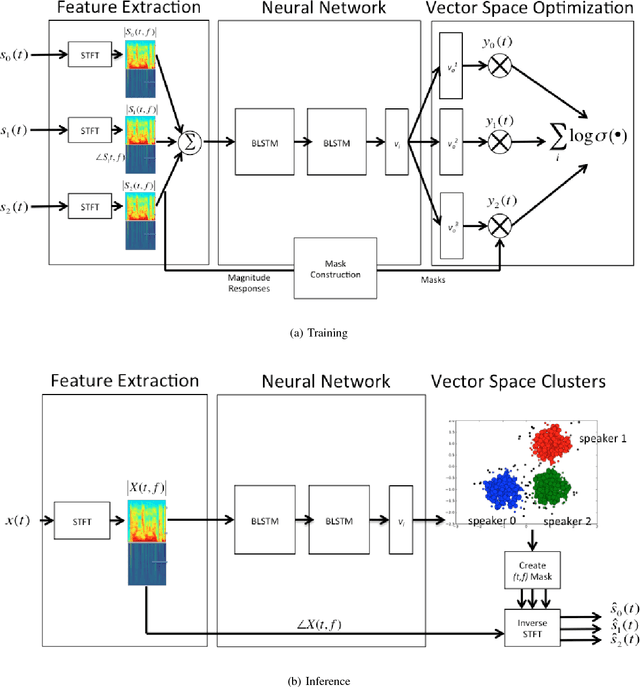
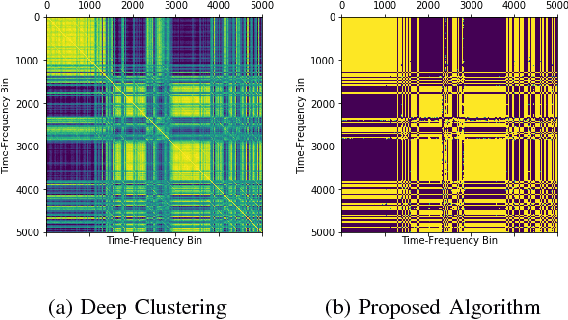
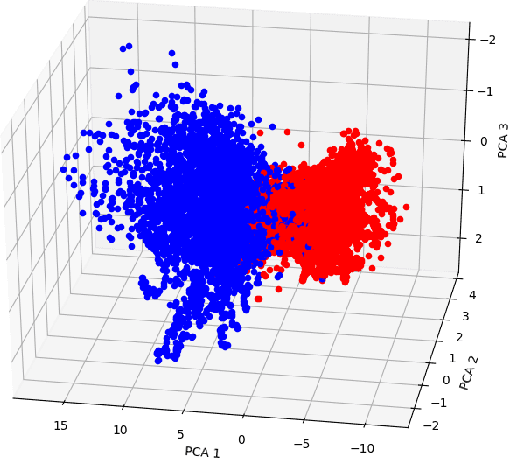
We propose an algorithm to separate simultaneously speaking persons from each other, the "cocktail party problem", using a single microphone. Our approach involves a deep recurrent neural networks regression to a vector space that is descriptive of independent speakers. Such a vector space can embed empirically determined speaker characteristics and is optimized by distinguishing between speaker masks. We call this technique source-contrastive estimation. The methodology is inspired by negative sampling, which has seen success in natural language processing, where an embedding is learned by correlating and de-correlating a given input vector with output weights. Although the matrix determined by the output weights is dependent on a set of known speakers, we only use the input vectors during inference. Doing so will ensure that source separation is explicitly speaker-independent. Our approach is similar to recent deep neural network clustering and permutation-invariant training research; we use weighted spectral features and masks to augment individual speaker frequencies while filtering out other speakers. We avoid, however, the severe computational burden of other approaches with our technique. Furthermore, by training a vector space rather than combinations of different speakers or differences thereof, we avoid the so-called permutation problem during training. Our algorithm offers an intuitive, computationally efficient response to the cocktail party problem, and most importantly boasts better empirical performance than other current techniques.