 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoSANE: Learning Geospatial Representations from Models, Not Data
Mar 24, 2026Recent advances in remote sensing have led to an increase in the number of available foundation models; each trained on different modalities, datasets, and objectives, yet capturing only part of the vast geospatial knowledge landscape. While these models show strong results within their respective domains, their capabilities remain complementary rather than unified. Therefore, instead of choosing one model over another, we aim to combine their strengths into a single shared representation. We introduce GeoSANE, a geospatial model foundry that learns a unified neural representation from the weights of existing foundation models and task-specific models, able to generate novel neural networks weights on-demand. Given a target architecture, GeoSANE generates weights ready for finetuning for classification, segmentation, and detection tasks across multiple modalities. Models generated by GeoSANE consistently outperform their counterparts trained from scratch, match or surpass state-of-the-art remote sensing foundation models, and outperform models obtained through pruning or knowledge distillation when generating lightweight networks. Evaluations across ten diverse datasets and on GEO-Bench confirm its strong generalization capabilities. By shifting from pre-training to weight generation, GeoSANE introduces a new framework for unifying and transferring geospatial knowledge across models and tasks. Code is available at \href{https://hsg-aiml.github.io/GeoSANE/}{hsg-aiml.github.io/GeoSANE/}.
A Survey of Weight Space Learning: Understanding, Representation, and Generation
Mar 10, 2026Neural network weights are typically viewed as the end product of training, while most deep learning research focuses on data, features, and architectures. However, recent advances show that the set of all possible weight values (weight space) itself contains rich structure: pretrained models form organized distributions, exhibit symmetries, and can be embedded, compared, or even generated. Understanding such structures has tremendous impact on how neural networks are analyzed and compared, and on how knowledge is transferred across models, beyond individual training instances. This emerging research direction, which we refer to as Weight Space Learning (WSL), treats neural weights as a meaningful domain for analysis and modeling. This survey provides the first unified taxonomy of WSL. We categorize existing methods into three core dimensions: Weight Space Understanding (WSU), which studies the geometry and symmetries of weights; Weight Space Representation (WSR), which learns embeddings over model weights; and Weight Space Generation (WSG), which synthesizes new weights through hypernetworks or generative models. We further show how these developments enable practical applications, including model retrieval, continual and federated learning, neural architecture search, and data-free reconstruction. By consolidating fragmented progress under a coherent framework, this survey highlights weight space as a learnable, structured domain with growing impact across model analysis, transferring, and weight generation. We release an accompanying resource at https://github.com/Zehong-Wang/Awesome-Weight-Space-Learning.
Learning Model Representations Using Publicly Available Model Hubs
Oct 02, 2025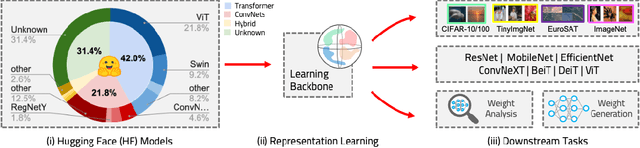

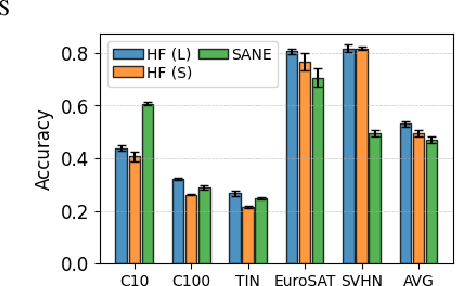
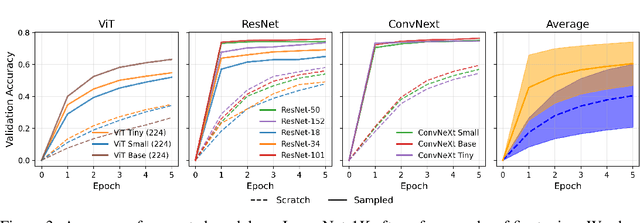
The weights of neural networks have emerged as a novel data modality, giving rise to the field of weight space learning. A central challenge in this area is that learning meaningful representations of weights typically requires large, carefully constructed collections of trained models, typically referred to as model zoos. These model zoos are often trained ad-hoc, requiring large computational resources, constraining the learned weight space representations in scale and flexibility. In this work, we drop this requirement by training a weight space learning backbone on arbitrary models downloaded from large, unstructured model repositories such as Hugging Face. Unlike curated model zoos, these repositories contain highly heterogeneous models: they vary in architecture and dataset, and are largely undocumented. To address the methodological challenges posed by such heterogeneity, we propose a new weight space backbone designed to handle unstructured model populations. We demonstrate that weight space representations trained on models from Hugging Face achieve strong performance, often outperforming backbones trained on laboratory-generated model zoos. Finally, we show that the diversity of the model weights in our training set allows our weight space model to generalize to unseen data modalities. By demonstrating that high-quality weight space representations can be learned in the wild, we show that curated model zoos are not indispensable, thereby overcoming a strong limitation currently faced by the weight space learning community.
Diffusion-Scheduled Denoising Autoencoders for Anomaly Detection in Tabular Data
Aug 01, 2025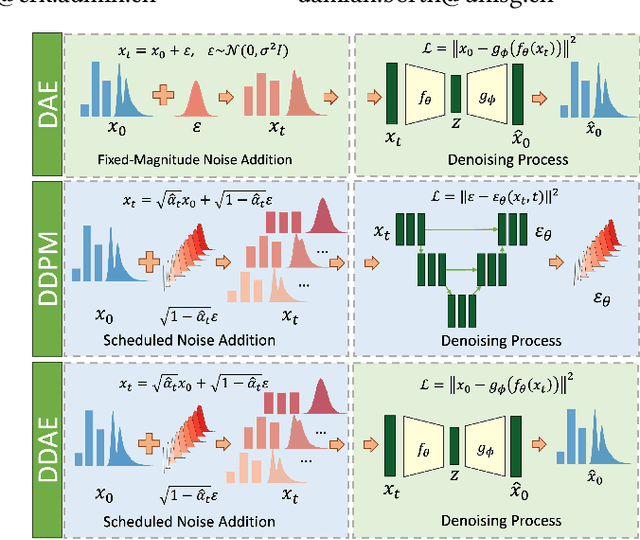
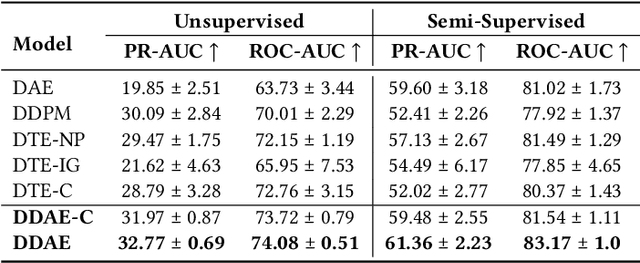
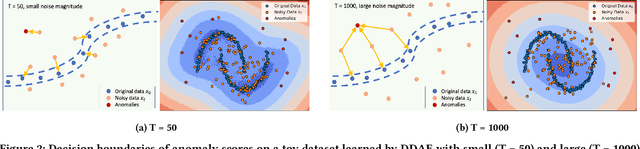

Anomaly detection in tabular data remains challenging due to complex feature interactions and the scarcity of anomalous examples. Denoising autoencoders rely on fixed-magnitude noise, limiting adaptability to diverse data distributions. Diffusion models introduce scheduled noise and iterative denoising, but lack explicit reconstruction mappings. We propose the Diffusion-Scheduled Denoising Autoencoder (DDAE), a framework that integrates diffusion-based noise scheduling and contrastive learning into the encoding process to improve anomaly detection. We evaluated DDAE on 57 datasets from ADBench. Our method outperforms in semi-supervised settings and achieves competitive results in unsupervised settings, improving PR-AUC by up to 65% (9%) and ROC-AUC by 16% (6%) over state-of-the-art autoencoder (diffusion) model baselines. We observed that higher noise levels benefit unsupervised training, while lower noise with linear scheduling is optimal in semi-supervised settings. These findings underscore the importance of principled noise strategies in tabular anomaly detection.
MAPEX: Modality-Aware Pruning of Experts for Remote Sensing Foundation Models
Jul 10, 2025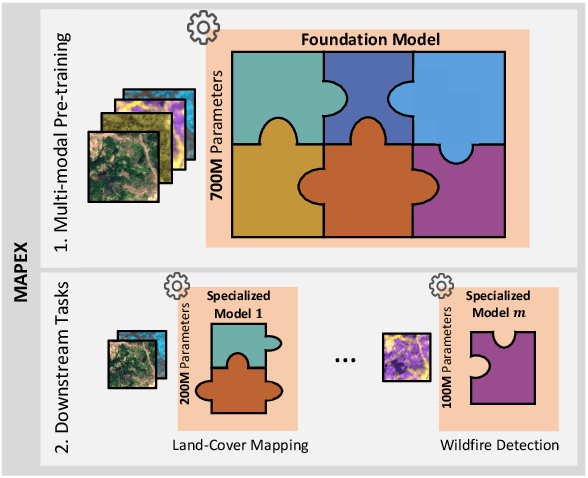
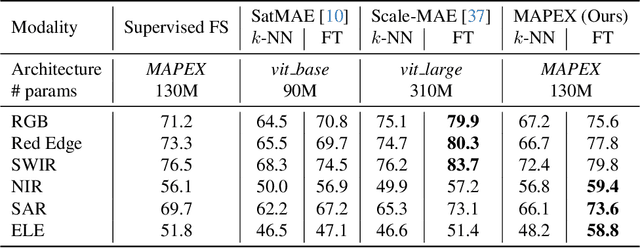
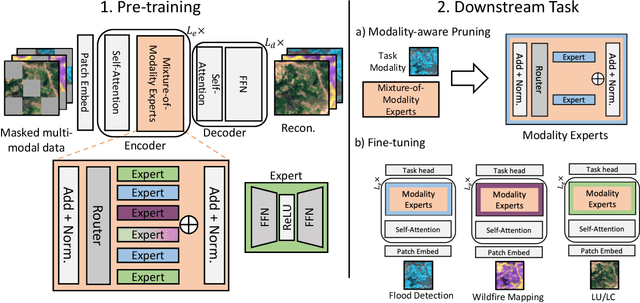
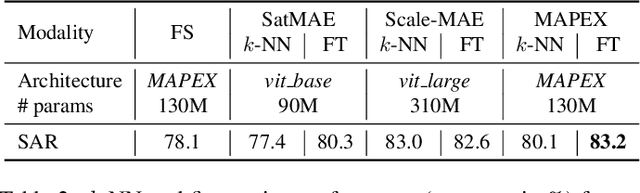
Remote sensing data is commonly used for tasks such as flood mapping, wildfire detection, or land-use studies. For each task, scientists carefully choose appropriate modalities or leverage data from purpose-built instruments. Recent work on remote sensing foundation models pre-trains computer vision models on large amounts of remote sensing data. These large-scale models tend to focus on specific modalities, often optical RGB or multispectral data. For many important applications, this introduces a mismatch between the application modalities and the pre-training data. Moreover, the large size of foundation models makes them expensive and difficult to fine-tune on typically small datasets for each task. We address this mismatch with MAPEX, a remote sensing foundation model based on mixture-of-modality experts. MAPEX is pre-trained on multi-modal remote sensing data with a novel modality-conditioned token routing mechanism that elicits modality-specific experts. To apply the model on a specific task, we propose a modality aware pruning technique, which only retains experts specialized for the task modalities. This yields efficient modality-specific models while simplifying fine-tuning and deployment for the modalities of interest. We experimentally validate MAPEX on diverse remote sensing datasets and show strong performance compared to fully supervised training and state-of-the-art remote sensing foundation models. Code is available at https://github.com/HSG-AIML/MAPEX.
Know Your Attention Maps: Class-specific Token Masking for Weakly Supervised Semantic Segmentation
Jul 09, 2025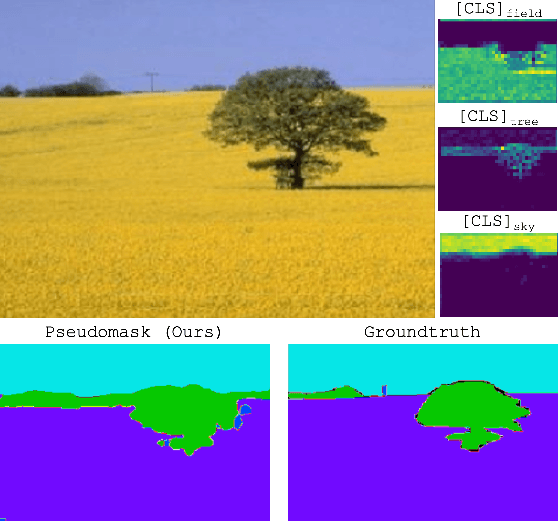
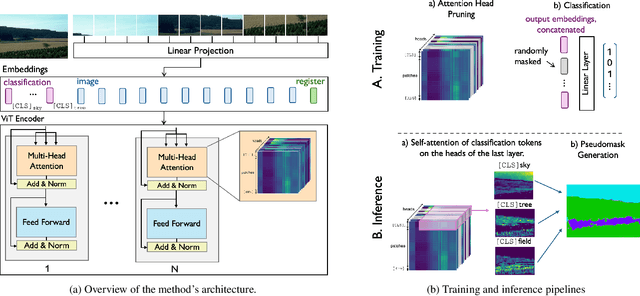
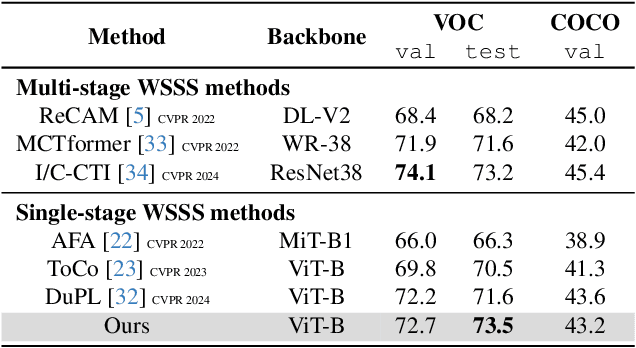
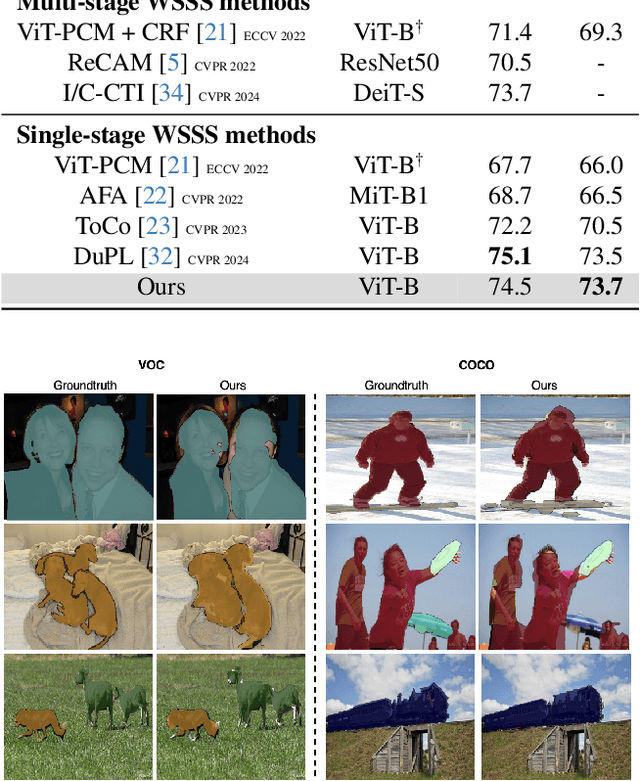
Weakly Supervised Semantic Segmentation (WSSS) is a challenging problem that has been extensively studied in recent years. Traditional approaches often rely on external modules like Class Activation Maps to highlight regions of interest and generate pseudo segmentation masks. In this work, we propose an end-to-end method that directly utilizes the attention maps learned by a Vision Transformer (ViT) for WSSS. We propose training a sparse ViT with multiple [CLS] tokens (one for each class), using a random masking strategy to promote [CLS] token - class assignment. At inference time, we aggregate the different self-attention maps of each [CLS] token corresponding to the predicted labels to generate pseudo segmentation masks. Our proposed approach enhances the interpretability of self-attention maps and ensures accurate class assignments. Extensive experiments on two standard benchmarks and three specialized datasets demonstrate that our method generates accurate pseudo-masks, outperforming related works. Those pseudo-masks can be used to train a segmentation model which achieves results comparable to fully-supervised models, significantly reducing the need for fine-grained labeled data.
A Model Zoo on Phase Transitions in Neural Networks
Apr 25, 2025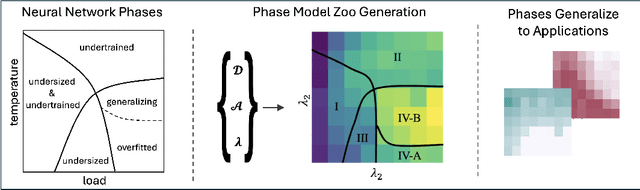
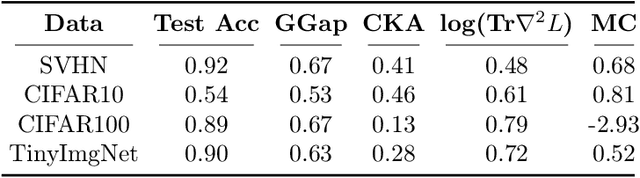
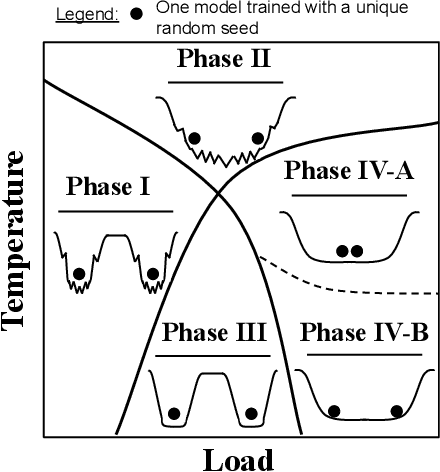

Using the weights of trained Neural Network (NN) models as data modality has recently gained traction as a research field - dubbed Weight Space Learning (WSL). Multiple recent works propose WSL methods to analyze models, evaluate methods, or synthesize weights. Weight space learning methods require populations of trained models as datasets for development and evaluation. However, existing collections of models - called `model zoos' - are unstructured or follow a rudimentary definition of diversity. In parallel, work rooted in statistical physics has identified phases and phase transitions in NN models. Models are homogeneous within the same phase but qualitatively differ from one phase to another. We combine the idea of `model zoos' with phase information to create a controlled notion of diversity in populations. We introduce 12 large-scale zoos that systematically cover known phases and vary over model architecture, size, and datasets. These datasets cover different modalities, such as computer vision, natural language processing, and scientific ML. For every model, we compute loss landscape metrics and validate full coverage of the phases. With this dataset, we provide the community with a resource with a wide range of potential applications for WSL and beyond. Evidence suggests the loss landscape phase plays a role in applications such as model training, analysis, or sparsification. We demonstrate this in an exploratory study of the downstream methods like transfer learning or model weights averaging.
Hyperspectral Vision Transformers for Greenhouse Gas Estimations from Space
Apr 23, 2025Hyperspectral imaging provides detailed spectral information and holds significant potential for monitoring of greenhouse gases (GHGs). However, its application is constrained by limited spatial coverage and infrequent revisit times. In contrast, multispectral imaging offers broader spatial and temporal coverage but often lacks the spectral detail that can enhance GHG detection. To address these challenges, this study proposes a spectral transformer model that synthesizes hyperspectral data from multispectral inputs. The model is pre-trained via a band-wise masked autoencoder and subsequently fine-tuned on spatio-temporally aligned multispectral-hyperspectral image pairs. The resulting synthetic hyperspectral data retain the spatial and temporal benefits of multispectral imagery and improve GHG prediction accuracy relative to using multispectral data alone. This approach effectively bridges the trade-off between spectral resolution and coverage, highlighting its potential to advance atmospheric monitoring by combining the strengths of hyperspectral and multispectral systems with self-supervised deep learning.
Dense Air Pollution Estimation from Sparse in-situ Measurements and Satellite Data
Apr 23, 2025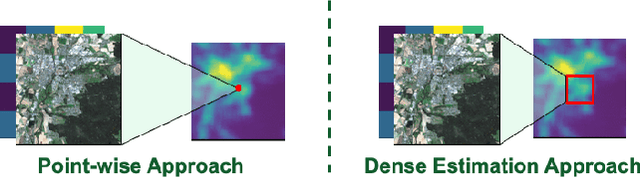
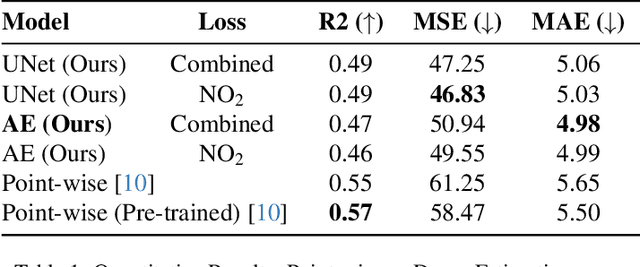
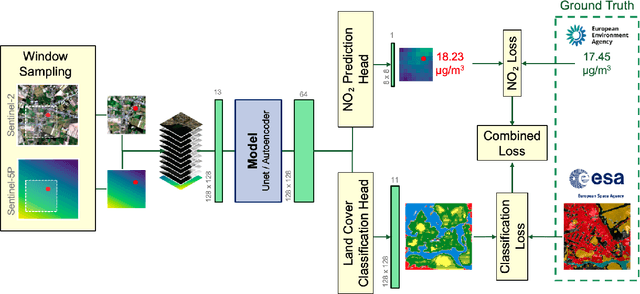
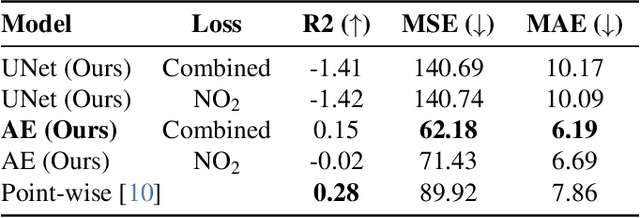
This paper addresses the critical environmental challenge of estimating ambient Nitrogen Dioxide (NO$_2$) concentrations, a key issue in public health and environmental policy. Existing methods for satellite-based air pollution estimation model the relationship between satellite and in-situ measurements at select point locations. While these approaches have advanced our ability to provide air quality estimations on a global scale, they come with inherent limitations. The most notable limitation is the computational intensity required for generating comprehensive estimates over extensive areas. Motivated by these limitations, this study introduces a novel dense estimation technique. Our approach seeks to balance the accuracy of high-resolution estimates with the practicality of computational constraints, thereby enabling efficient and scalable global environmental assessment. By utilizing a uniformly random offset sampling strategy, our method disperses the ground truth data pixel location evenly across a larger patch. At inference, the dense estimation method can then generate a grid of estimates in a single step, significantly reducing the computational resources required to provide estimates for larger areas. Notably, our approach also surpasses the results of existing point-wise methods by a significant margin of $9.45\%$, achieving a Mean Absolute Error (MAE) of $4.98\ \mu\text{g}/\text{m}^3$. This demonstrates both high accuracy and computational efficiency, highlighting the applicability of our method for global environmental assessment. Furthermore, we showcase the method's adaptability and robustness by applying it to diverse geographic regions. Our method offers a viable solution to the computational challenges of large-scale environmental monitoring.
SAR-to-RGB Translation with Latent Diffusion for Earth Observation
Apr 15, 2025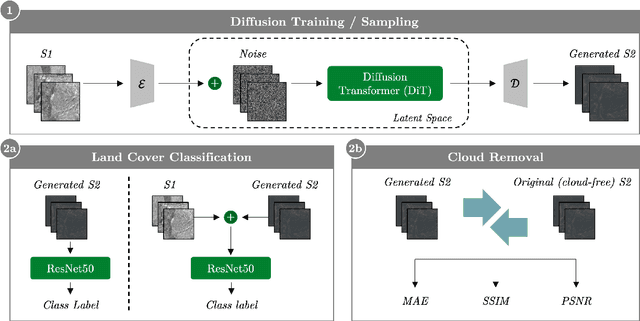



Earth observation satellites like Sentinel-1 (S1) and Sentinel-2 (S2) provide complementary remote sensing (RS) data, but S2 images are often unavailable due to cloud cover or data gaps. To address this, we propose a diffusion model (DM)-based approach for SAR-to-RGB translation, generating synthetic optical images from SAR inputs. We explore three different setups: two using Standard Diffusion, which reconstruct S2 images by adding and removing noise (one without and one with class conditioning), and one using Cold Diffusion, which blends S2 with S1 before removing the SAR signal. We evaluate the generated images in downstream tasks, including land cover classification and cloud removal. While generated images may not perfectly replicate real S2 data, they still provide valuable information. Our results show that class conditioning improves classification accuracy, while cloud removal performance remains competitive despite our approach not being optimized for it. Interestingly, despite exhibiting lower perceptual quality, the Cold Diffusion setup performs well in land cover classification, suggesting that traditional quantitative evaluation metrics may not fully reflect the practical utility of generated images. Our findings highlight the potential of DMs for SAR-to-RGB translation in RS applications where RGB images are missing.