 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Active Learning under (Human) Label Variation
Jul 03, 2025Access to high-quality labeled data remains a limiting factor in applied supervised learning. While label variation (LV), i.e., differing labels for the same instance, is common, especially in natural language processing, annotation frameworks often still rest on the assumption of a single ground truth. This overlooks human label variation (HLV), the occurrence of plausible differences in annotations, as an informative signal. Similarly, active learning (AL), a popular approach to optimizing the use of limited annotation budgets in training ML models, often relies on at least one of several simplifying assumptions, which rarely hold in practice when acknowledging HLV. In this paper, we examine foundational assumptions about truth and label nature, highlighting the need to decompose observed LV into signal (e.g., HLV) and noise (e.g., annotation error). We survey how the AL and (H)LV communities have addressed -- or neglected -- these distinctions and propose a conceptual framework for incorporating HLV throughout the AL loop, including instance selection, annotator choice, and label representation. We further discuss the integration of large language models (LLM) as annotators. Our work aims to lay a conceptual foundation for HLV-aware active learning, better reflecting the complexities of real-world annotation.
Structure Is Not Enough: Leveraging Behavior for Neural Network Weight Reconstruction
Mar 21, 2025The weights of neural networks (NNs) have recently gained prominence as a new data modality in machine learning, with applications ranging from accuracy and hyperparameter prediction to representation learning or weight generation. One approach to leverage NN weights involves training autoencoders (AEs), using contrastive and reconstruction losses. This allows such models to be applied to a wide variety of downstream tasks, and they demonstrate strong predictive performance and low reconstruction error. However, despite the low reconstruction error, these AEs reconstruct NN models with deteriorated performance compared to the original ones, limiting their usability with regard to model weight generation. In this paper, we identify a limitation of weight-space AEs, specifically highlighting that a structural loss, that uses the Euclidean distance between original and reconstructed weights, fails to capture some features critical for reconstructing high-performing models. We analyze the addition of a behavioral loss for training AEs in weight space, where we compare the output of the reconstructed model with that of the original one, given some common input. We show a strong synergy between structural and behavioral signals, leading to increased performance in all downstream tasks evaluated, in particular NN weights reconstruction and generation.
Towards Label Embedding -- Measuring classification difficulty
Nov 15, 2023Uncertainty quantification in machine learning is a timely and vast field of research. In supervised learning, uncertainty can already occur in the very first stage of the training process, the labelling step. In particular, this is the case when not every instance can be unambiguously classified. The problem occurs for classifying instances, where classes may overlap or instances can not be clearly categorised. In other words, there is inevitable ambiguity in the annotation step and not necessarily a 'ground truth'. We look exemplary at the classification of satellite images. Each image is annotated independently by multiple labellers and classified into local climate zones (LCZs). For each instance we have multiple votes, leading to a distribution of labels rather than a single value. The main idea of this work is that we do not assume a ground truth label but embed the votes into a K-dimensional space, with K as the number of possible categories. The embedding is derived from the voting distribution in a Bayesian setup, modelled via a Dirichlet-Multinomial model. We estimate the model and posteriors using a stochastic Expectation Maximisation algorithm with Markov Chain Monte Carlo steps. While we focus on the particular example of LCZ classification, the methods developed in this paper readily extend to other situations where multiple annotators independently label texts or images. We also apply our approach to two other benchmark datasets for image classification to demonstrate this. Besides the embeddings themselves, we can investigate the resulting correlation matrices, which can be seen as generalised confusion matrices and reflect the semantic similarities of the original classes very well for all three exemplary datasets. The insights gained are valuable and can serve as general label embedding if a single ground truth per observation cannot be guaranteed.
Sources of Uncertainty in Machine Learning -- A Statisticians' View
May 26, 2023Machine Learning and Deep Learning have achieved an impressive standard today, enabling us to answer questions that were inconceivable a few years ago. Besides these successes, it becomes clear, that beyond pure prediction, which is the primary strength of most supervised machine learning algorithms, the quantification of uncertainty is relevant and necessary as well. While first concepts and ideas in this direction have emerged in recent years, this paper adopts a conceptual perspective and examines possible sources of uncertainty. By adopting the viewpoint of a statistician, we discuss the concepts of aleatoric and epistemic uncertainty, which are more commonly associated with machine learning. The paper aims to formalize the two types of uncertainty and demonstrates that sources of uncertainty are miscellaneous and can not always be decomposed into aleatoric and epistemic. Drawing parallels between statistical concepts and uncertainty in machine learning, we also demonstrate the role of data and their influence on uncertainty.
The Politics of Language Choice: How the Russian-Ukrainian War Influences Ukrainians' Language Use on Twitter
May 04, 2023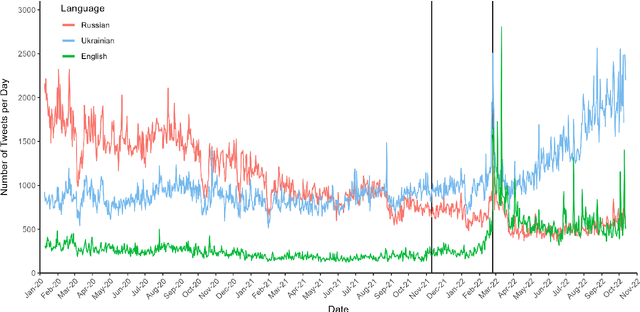
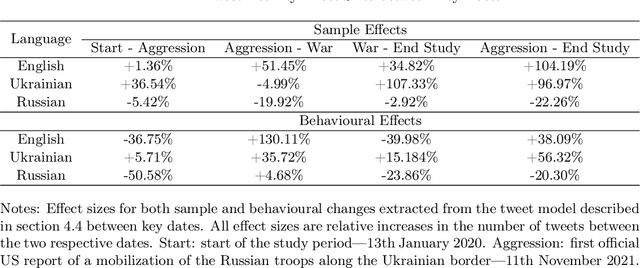
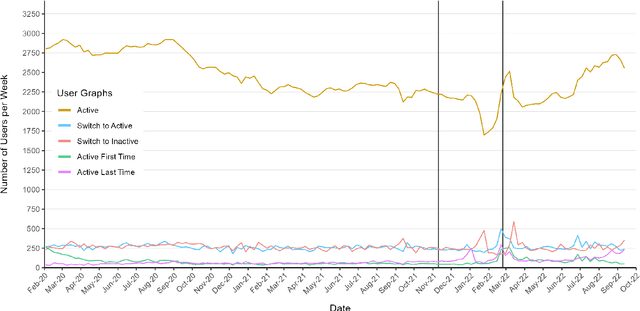
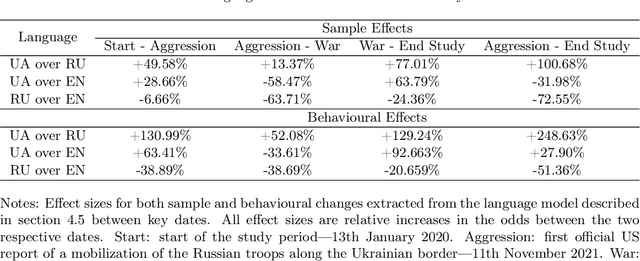
The use of language is innately political and often a vehicle of cultural identity as well as the basis for nation building. Here, we examine language choice and tweeting activity of Ukrainian citizens based on more than 4 million geo-tagged tweets from over 62,000 users before and during the Russian-Ukrainian War, from January 2020 to October 2022. Using statistical models, we disentangle sample effects, arising from the in- and outflux of users on Twitter, from behavioural effects, arising from behavioural changes of the users. We observe a steady shift from the Russian language towards the Ukrainian language already before the war, which drastically speeds up with its outbreak. We attribute these shifts in large part to users' behavioural changes. Notably, we find that many Russian-tweeting users perform a hard-switch to Ukrainian as a result of the war.
Going Beyond One-Hot Encoding in Classification: Can Human Uncertainty Improve Model Performance?
May 30, 2022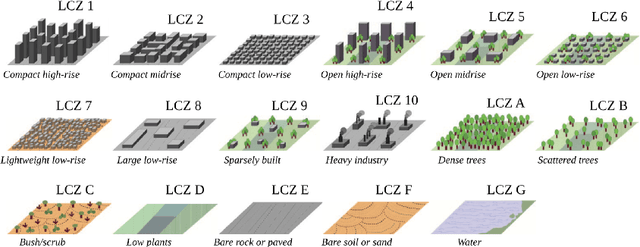



Technological and computational advances continuously drive forward the broad field of deep learning. In recent years, the derivation of quantities describing theuncertainty in the prediction - which naturally accompanies the modeling process - has sparked general interest in the deep learning community. Often neglected in the machine learning setting is the human uncertainty that influences numerous labeling processes. As the core of this work, label uncertainty is explicitly embedded into the training process via distributional labels. We demonstrate the effectiveness of our approach on image classification with a remote sensing data set that contains multiple label votes by domain experts for each image: The incorporation of label uncertainty helps the model to generalize better to unseen data and increases model performance. Similar to existing calibration methods, the distributional labels lead to better-calibrated probabilities, which in turn yield more certain and trustworthy predictions.