 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Certain are Uncertainty Estimates? Three Novel Earth Observation Datasets for Benchmarking Uncertainty Quantification in Machine Learning
Dec 09, 2024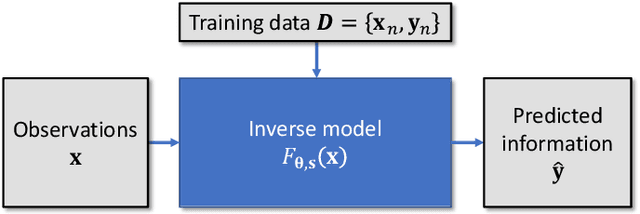


Uncertainty quantification (UQ) is essential for assessing the reliability of Earth observation (EO) products. However, the extensive use of machine learning models in EO introduces an additional layer of complexity, as those models themselves are inherently uncertain. While various UQ methods do exist for machine learning models, their performance on EO datasets remains largely unevaluated. A key challenge in the community is the absence of the ground truth for uncertainty, i.e. how certain the uncertainty estimates are, apart from the labels for the image/signal. This article fills this gap by introducing three benchmark datasets specifically designed for UQ in EO machine learning models. These datasets address three common problem types in EO: regression, image segmentation, and scene classification. They enable a transparent comparison of different UQ methods for EO machine learning models. We describe the creation and characteristics of each dataset, including data sources, preprocessing steps, and label generation, with a particular focus on calculating the reference uncertainty. We also showcase baseline performance of several machine learning models on each dataset, highlighting the utility of these benchmarks for model development and comparison. Overall, this article offers a valuable resource for researchers and practitioners working in artificial intelligence for EO, promoting a more accurate and reliable quality measure of the outputs of machine learning models. The dataset and code are accessible via https://gitlab.lrz.de/ai4eo/WG_Uncertainty.
Towards Label Embedding -- Measuring classification difficulty
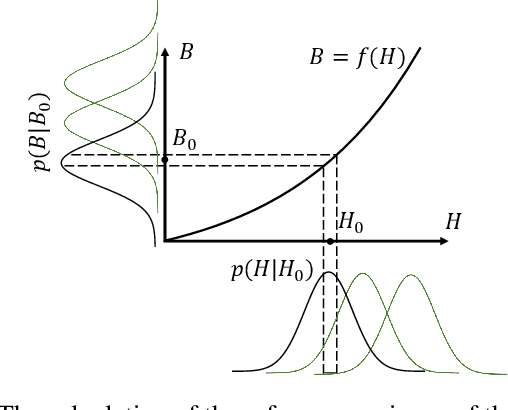
Nov 15, 2023Uncertainty quantification in machine learning is a timely and vast field of research. In supervised learning, uncertainty can already occur in the very first stage of the training process, the labelling step. In particular, this is the case when not every instance can be unambiguously classified. The problem occurs for classifying instances, where classes may overlap or instances can not be clearly categorised. In other words, there is inevitable ambiguity in the annotation step and not necessarily a 'ground truth'. We look exemplary at the classification of satellite images. Each image is annotated independently by multiple labellers and classified into local climate zones (LCZs). For each instance we have multiple votes, leading to a distribution of labels rather than a single value. The main idea of this work is that we do not assume a ground truth label but embed the votes into a K-dimensional space, with K as the number of possible categories. The embedding is derived from the voting distribution in a Bayesian setup, modelled via a Dirichlet-Multinomial model. We estimate the model and posteriors using a stochastic Expectation Maximisation algorithm with Markov Chain Monte Carlo steps. While we focus on the particular example of LCZ classification, the methods developed in this paper readily extend to other situations where multiple annotators independently label texts or images. We also apply our approach to two other benchmark datasets for image classification to demonstrate this. Besides the embeddings themselves, we can investigate the resulting correlation matrices, which can be seen as generalised confusion matrices and reflect the semantic similarities of the original classes very well for all three exemplary datasets. The insights gained are valuable and can serve as general label embedding if a single ground truth per observation cannot be guaranteed.
Going Beyond One-Hot Encoding in Classification: Can Human Uncertainty Improve Model Performance?
May 30, 2022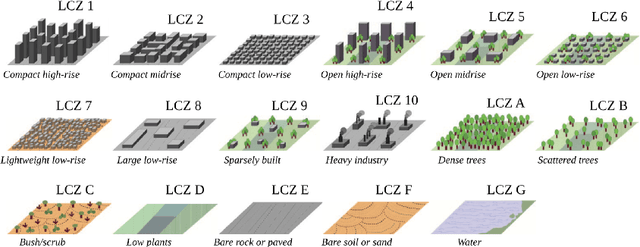



Technological and computational advances continuously drive forward the broad field of deep learning. In recent years, the derivation of quantities describing theuncertainty in the prediction - which naturally accompanies the modeling process - has sparked general interest in the deep learning community. Often neglected in the machine learning setting is the human uncertainty that influences numerous labeling processes. As the core of this work, label uncertainty is explicitly embedded into the training process via distributional labels. We demonstrate the effectiveness of our approach on image classification with a remote sensing data set that contains multiple label votes by domain experts for each image: The incorporation of label uncertainty helps the model to generalize better to unseen data and increases model performance. Similar to existing calibration methods, the distributional labels lead to better-calibrated probabilities, which in turn yield more certain and trustworthy predictions.