 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRisk-Aware Human-in-the-Loop Framework with Adaptive Intrusion Response for Autonomous Vehicles
Jan 16, 2026Autonomous vehicles must remain safe and effective when encountering rare long-tailed scenarios or cyber-physical intrusions during driving. We present RAIL, a risk-aware human-in-the-loop framework that turns heterogeneous runtime signals into calibrated control adaptations and focused learning. RAIL fuses three cues (curvature actuation integrity, time-to-collision proximity, and observation-shift consistency) into an Intrusion Risk Score (IRS) via a weighted Noisy-OR. When IRS exceeds a threshold, actions are blended with a cue-specific shield using a learned authority, while human override remains available; when risk is low, the nominal policy executes. A contextual bandit arbitrates among shields based on the cue vector, improving mitigation choices online. RAIL couples Soft Actor-Critic (SAC) with risk-prioritized replay and dual rewards so that takeovers and near misses steer learning while nominal behavior remains covered. On MetaDrive, RAIL achieves a Test Return (TR) of 360.65, a Test Success Rate (TSR) of 0.85, a Test Safety Violation (TSV) of 0.75, and a Disturbance Rate (DR) of 0.0027, while logging only 29.07 training safety violations, outperforming RL, safe RL, offline/imitation learning, and prior HITL baselines. Under Controller Area Network (CAN) injection and LiDAR spoofing attacks, it improves Success Rate (SR) to 0.68 and 0.80, lowers the Disengagement Rate under Attack (DRA) to 0.37 and 0.03, and reduces the Attack Success Rate (ASR) to 0.34 and 0.11. In CARLA, RAIL attains a TR of 1609.70 and TSR of 0.41 with only 8000 steps.
MURIM: Multidimensional Reputation-based Incentive Mechanism for Federated Learning
Dec 15, 2025Federated Learning (FL) has emerged as a leading privacy-preserving machine learning paradigm, enabling participants to share model updates instead of raw data. However, FL continues to face key challenges, including weak client incentives, privacy risks, and resource constraints. Assessing client reliability is essential for fair incentive allocation and ensuring that each client's data contributes meaningfully to the global model. To this end, we propose MURIM, a MUlti-dimensional Reputation-based Incentive Mechanism that jointly considers client reliability, privacy, resource capacity, and fairness while preventing malicious or unreliable clients from earning undeserved rewards. MURIM allocates incentives based on client contribution, latency, and reputation, supported by a reliability verification module. Extensive experiments on MNIST, FMNIST, and ADULT Income datasets demonstrate that MURIM achieves up to 18% improvement in fairness metrics, reduces privacy attack success rates by 5-9%, and improves robustness against poisoning and noisy-gradient attacks by up to 85% compared to state-of-the-art baselines. Overall, MURIM effectively mitigates adversarial threats, promotes fair and truthful participation, and preserves stable model convergence across heterogeneous and dynamic federated settings.
Empirical Analysis of Privacy-Fairness-Accuracy Trade-offs in Federated Learning: A Step Towards Responsible AI
Mar 20, 2025Federated Learning (FL) enables collaborative machine learning while preserving data privacy but struggles to balance privacy preservation (PP) and fairness. Techniques like Differential Privacy (DP), Homomorphic Encryption (HE), and Secure Multi-Party Computation (SMC) protect sensitive data but introduce trade-offs. DP enhances privacy but can disproportionately impact underrepresented groups, while HE and SMC mitigate fairness concerns at the cost of computational overhead. This work explores the privacy-fairness trade-offs in FL under IID (Independent and Identically Distributed) and non-IID data distributions, benchmarking q-FedAvg, q-MAML, and Ditto on diverse datasets. Our findings highlight context-dependent trade-offs and offer guidelines for designing FL systems that uphold responsible AI principles, ensuring fairness, privacy, and equitable real-world applications.
RESFL: An Uncertainty-Aware Framework for Responsible Federated Learning by Balancing Privacy, Fairness and Utility in Autonomous Vehicles
Mar 20, 2025Autonomous vehicles (AVs) increasingly rely on Federated Learning (FL) to enhance perception models while preserving privacy. However, existing FL frameworks struggle to balance privacy, fairness, and robustness, leading to performance disparities across demographic groups. Privacy-preserving techniques like differential privacy mitigate data leakage risks but worsen fairness by restricting access to sensitive attributes needed for bias correction. This work explores the trade-off between privacy and fairness in FL-based object detection for AVs and introduces RESFL, an integrated solution optimizing both. RESFL incorporates adversarial privacy disentanglement and uncertainty-guided fairness-aware aggregation. The adversarial component uses a gradient reversal layer to remove sensitive attributes, reducing privacy risks while maintaining fairness. The uncertainty-aware aggregation employs an evidential neural network to weight client updates adaptively, prioritizing contributions with lower fairness disparities and higher confidence. This ensures robust and equitable FL model updates. We evaluate RESFL on the FACET dataset and CARLA simulator, assessing accuracy, fairness, privacy resilience, and robustness under varying conditions. RESFL improves detection accuracy, reduces fairness disparities, and lowers privacy attack success rates while demonstrating superior robustness to adversarial conditions compared to other approaches.
How Certain are Uncertainty Estimates? Three Novel Earth Observation Datasets for Benchmarking Uncertainty Quantification in Machine Learning
Dec 09, 2024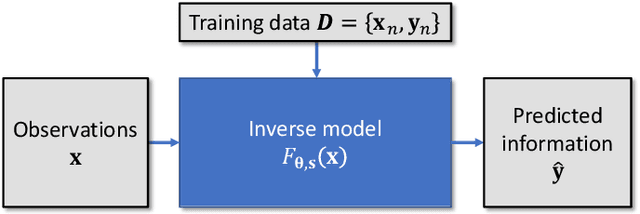

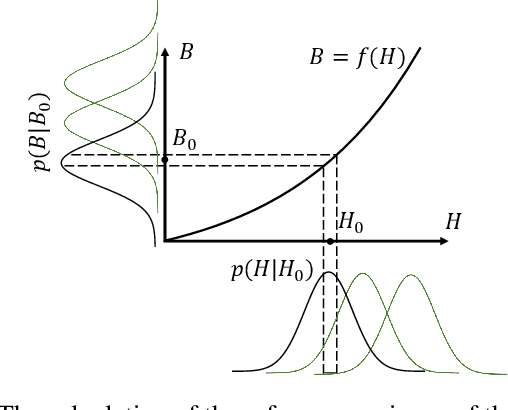

Uncertainty quantification (UQ) is essential for assessing the reliability of Earth observation (EO) products. However, the extensive use of machine learning models in EO introduces an additional layer of complexity, as those models themselves are inherently uncertain. While various UQ methods do exist for machine learning models, their performance on EO datasets remains largely unevaluated. A key challenge in the community is the absence of the ground truth for uncertainty, i.e. how certain the uncertainty estimates are, apart from the labels for the image/signal. This article fills this gap by introducing three benchmark datasets specifically designed for UQ in EO machine learning models. These datasets address three common problem types in EO: regression, image segmentation, and scene classification. They enable a transparent comparison of different UQ methods for EO machine learning models. We describe the creation and characteristics of each dataset, including data sources, preprocessing steps, and label generation, with a particular focus on calculating the reference uncertainty. We also showcase baseline performance of several machine learning models on each dataset, highlighting the utility of these benchmarks for model development and comparison. Overall, this article offers a valuable resource for researchers and practitioners working in artificial intelligence for EO, promoting a more accurate and reliable quality measure of the outputs of machine learning models. The dataset and code are accessible via https://gitlab.lrz.de/ai4eo/WG_Uncertainty.