 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSources of Uncertainty in Machine Learning -- A Statisticians' View
May 26, 2023Machine Learning and Deep Learning have achieved an impressive standard today, enabling us to answer questions that were inconceivable a few years ago. Besides these successes, it becomes clear, that beyond pure prediction, which is the primary strength of most supervised machine learning algorithms, the quantification of uncertainty is relevant and necessary as well. While first concepts and ideas in this direction have emerged in recent years, this paper adopts a conceptual perspective and examines possible sources of uncertainty. By adopting the viewpoint of a statistician, we discuss the concepts of aleatoric and epistemic uncertainty, which are more commonly associated with machine learning. The paper aims to formalize the two types of uncertainty and demonstrates that sources of uncertainty are miscellaneous and can not always be decomposed into aleatoric and epistemic. Drawing parallels between statistical concepts and uncertainty in machine learning, we also demonstrate the role of data and their influence on uncertainty.
When regression coefficients change over time: A proposal
Mar 19, 2022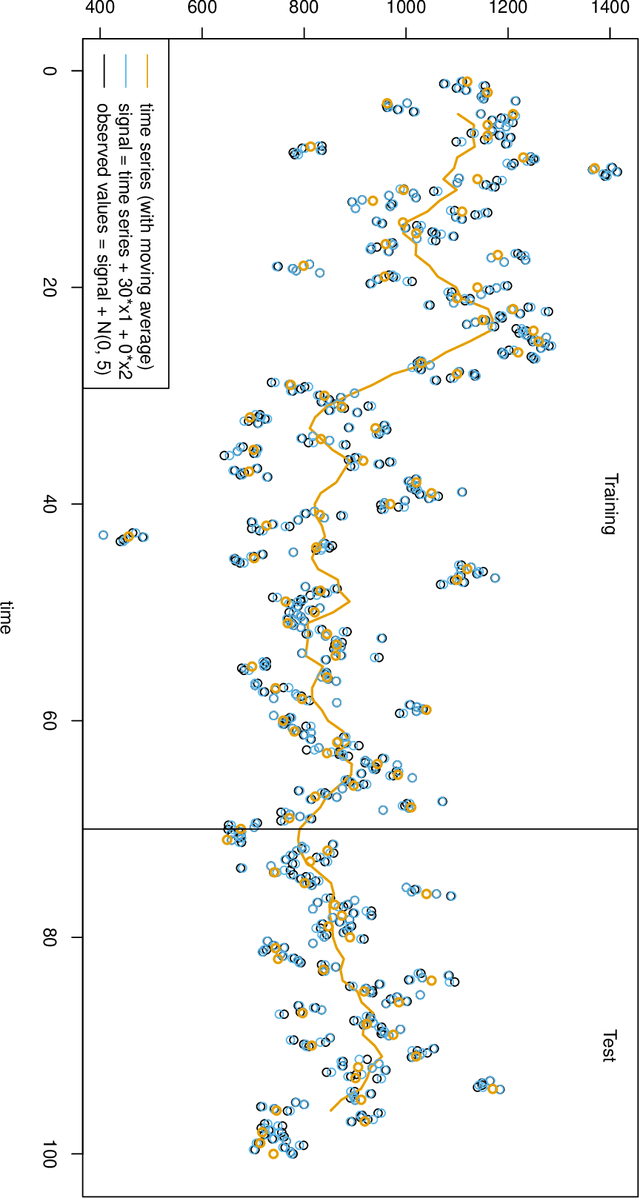
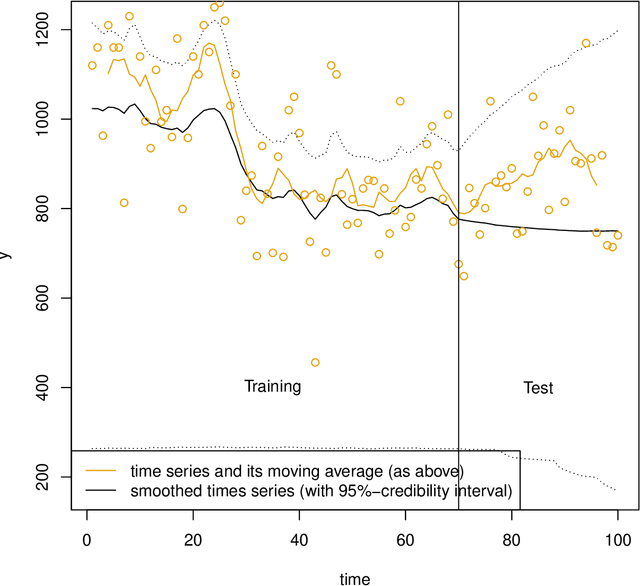
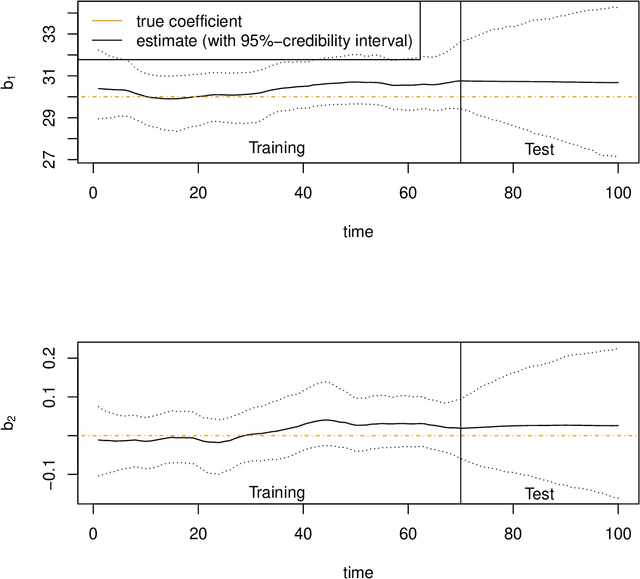
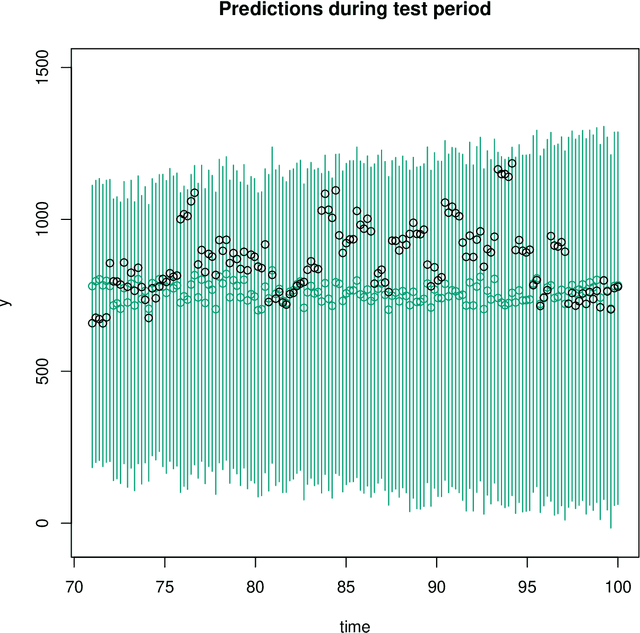
A common approach in forecasting problems is to estimate a least-squares regression (or other statistical learning models) from past data, which is then applied to predict future outcomes. An underlying assumption is that the same correlations that were observed in the past still hold for the future. We propose a model for situations when this assumption is not met: adopting methods from the state space literature, we model how regression coefficients change over time. Our approach can shed light on the large uncertainties associated with forecasting the future, and how much of this is due to changing dynamics of the past. Our simulation study shows that accurate estimates are obtained when the outcome is continuous, but the procedure fails for binary outcomes.