 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Model Representations Using Publicly Available Model Hubs
Oct 02, 2025The weights of neural networks have emerged as a novel data modality, giving rise to the field of weight space learning. A central challenge in this area is that learning meaningful representations of weights typically requires large, carefully constructed collections of trained models, typically referred to as model zoos. These model zoos are often trained ad-hoc, requiring large computational resources, constraining the learned weight space representations in scale and flexibility. In this work, we drop this requirement by training a weight space learning backbone on arbitrary models downloaded from large, unstructured model repositories such as Hugging Face. Unlike curated model zoos, these repositories contain highly heterogeneous models: they vary in architecture and dataset, and are largely undocumented. To address the methodological challenges posed by such heterogeneity, we propose a new weight space backbone designed to handle unstructured model populations. We demonstrate that weight space representations trained on models from Hugging Face achieve strong performance, often outperforming backbones trained on laboratory-generated model zoos. Finally, we show that the diversity of the model weights in our training set allows our weight space model to generalize to unseen data modalities. By demonstrating that high-quality weight space representations can be learned in the wild, we show that curated model zoos are not indispensable, thereby overcoming a strong limitation currently faced by the weight space learning community.
A Model Zoo on Phase Transitions in Neural Networks
Apr 25, 2025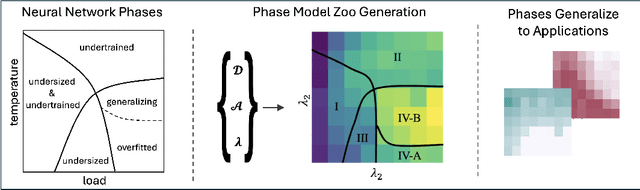
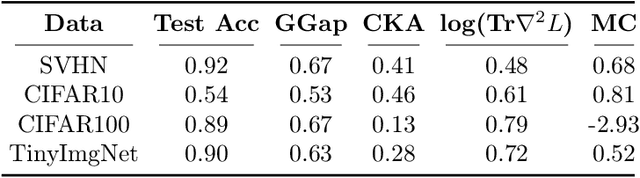
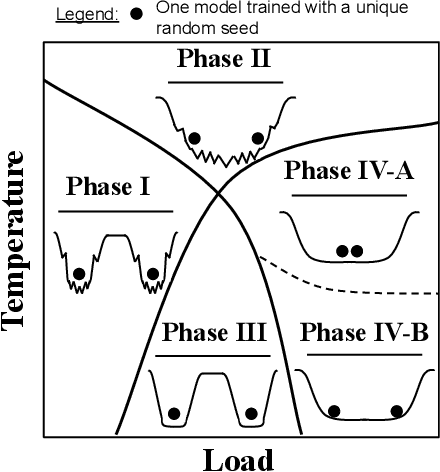

Using the weights of trained Neural Network (NN) models as data modality has recently gained traction as a research field - dubbed Weight Space Learning (WSL). Multiple recent works propose WSL methods to analyze models, evaluate methods, or synthesize weights. Weight space learning methods require populations of trained models as datasets for development and evaluation. However, existing collections of models - called `model zoos' - are unstructured or follow a rudimentary definition of diversity. In parallel, work rooted in statistical physics has identified phases and phase transitions in NN models. Models are homogeneous within the same phase but qualitatively differ from one phase to another. We combine the idea of `model zoos' with phase information to create a controlled notion of diversity in populations. We introduce 12 large-scale zoos that systematically cover known phases and vary over model architecture, size, and datasets. These datasets cover different modalities, such as computer vision, natural language processing, and scientific ML. For every model, we compute loss landscape metrics and validate full coverage of the phases. With this dataset, we provide the community with a resource with a wide range of potential applications for WSL and beyond. Evidence suggests the loss landscape phase plays a role in applications such as model training, analysis, or sparsification. We demonstrate this in an exploratory study of the downstream methods like transfer learning or model weights averaging.
A Model Zoo of Vision Transformers
Apr 14, 2025The availability of large, structured populations of neural networks - called 'model zoos' - has led to the development of a multitude of downstream tasks ranging from model analysis, to representation learning on model weights or generative modeling of neural network parameters. However, existing model zoos are limited in size and architecture and neglect the transformer, which is among the currently most successful neural network architectures. We address this gap by introducing the first model zoo of vision transformers (ViT). To better represent recent training approaches, we develop a new blueprint for model zoo generation that encompasses both pre-training and fine-tuning steps, and publish 250 unique models. They are carefully generated with a large span of generating factors, and their diversity is validated using a thorough choice of weight-space and behavioral metrics. To further motivate the utility of our proposed dataset, we suggest multiple possible applications grounded in both extensive exploratory experiments and a number of examples from the existing literature. By extending previous lines of similar work, our model zoo allows researchers to push their model population-based methods from the small model regime to state-of-the-art architectures. We make our model zoo available at github.com/ModelZoos/ViTModelZoo.
Structure Is Not Enough: Leveraging Behavior for Neural Network Weight Reconstruction
Mar 21, 2025The weights of neural networks (NNs) have recently gained prominence as a new data modality in machine learning, with applications ranging from accuracy and hyperparameter prediction to representation learning or weight generation. One approach to leverage NN weights involves training autoencoders (AEs), using contrastive and reconstruction losses. This allows such models to be applied to a wide variety of downstream tasks, and they demonstrate strong predictive performance and low reconstruction error. However, despite the low reconstruction error, these AEs reconstruct NN models with deteriorated performance compared to the original ones, limiting their usability with regard to model weight generation. In this paper, we identify a limitation of weight-space AEs, specifically highlighting that a structural loss, that uses the Euclidean distance between original and reconstructed weights, fails to capture some features critical for reconstructing high-performing models. We analyze the addition of a behavioral loss for training AEs in weight space, where we compare the output of the reconstructed model with that of the original one, given some common input. We show a strong synergy between structural and behavioral signals, leading to increased performance in all downstream tasks evaluated, in particular NN weights reconstruction and generation.
Distribution inference risks: Identifying and mitigating sources of leakage
Sep 18, 2022

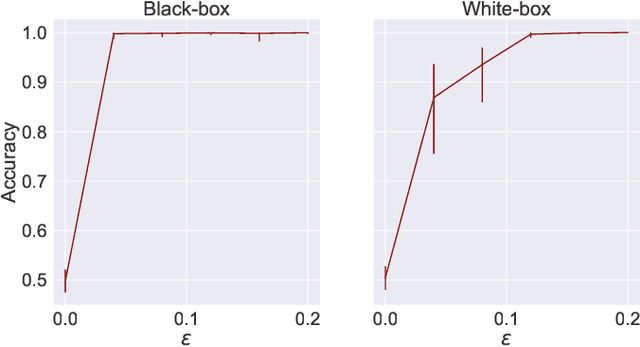
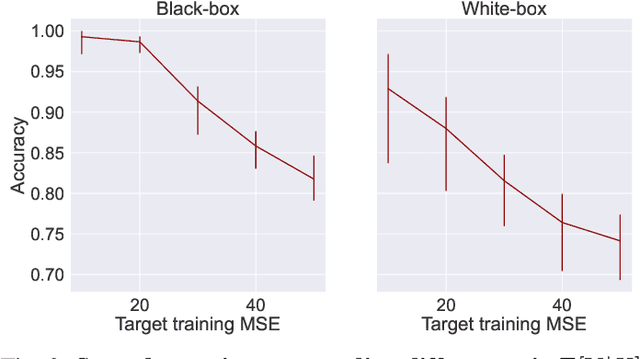
A large body of work shows that machine learning (ML) models can leak sensitive or confidential information about their training data. Recently, leakage due to distribution inference (or property inference) attacks is gaining attention. In this attack, the goal of an adversary is to infer distributional information about the training data. So far, research on distribution inference has focused on demonstrating successful attacks, with little attention given to identifying the potential causes of the leakage and to proposing mitigations. To bridge this gap, as our main contribution, we theoretically and empirically analyze the sources of information leakage that allows an adversary to perpetrate distribution inference attacks. We identify three sources of leakage: (1) memorizing specific information about the $\mathbb{E}[Y|X]$ (expected label given the feature values) of interest to the adversary, (2) wrong inductive bias of the model, and (3) finiteness of the training data. Next, based on our analysis, we propose principled mitigation techniques against distribution inference attacks. Specifically, we demonstrate that causal learning techniques are more resilient to a particular type of distribution inference risk termed distributional membership inference than associative learning methods. And lastly, we present a formalization of distribution inference that allows for reasoning about more general adversaries than was previously possible.