 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCognitive Training for Language Models: Towards General Capabilities via Cross-Entropy Games
Mar 23, 2026Defining a constructive process to build general capabilities for language models in an automatic manner is considered an open problem in artificial intelligence. Towards this, we consider the problem of building a curriculum of tasks that grows a model via relevant skill discovery. We provide a concrete framework for this task, using a family of tasks called cross-entropy games, which we postulate is universal in a suitable sense. We show that if it is possible to grow the curriculum for relevant skill discovery by iterating a greedy optimization algorithm, then, under natural assumptions, there is essentially only one meta-objective possible (up to a few hyperparameters). We call the resulting process cognitive training. We postulate that, given sufficiently capable language models as players and meta-samplers and sufficient training time, cognitive training provides a principled way to relevant skill discovery; and hence to the extent general capabilities are achievable via greedy curriculum learning, cognitive training would be a solution.
TiME: Tiny Monolingual Encoders for Efficient NLP Pipelines
Dec 16, 2025Today, a lot of research on language models is focused on large, general-purpose models. However, many NLP pipelines only require models with a well-defined, small set of capabilities. While large models are capable of performing the tasks of those smaller models, they are simply not fast enough to process large amounts of data or offer real-time responses. Furthermore, they often use unnecessarily large amounts of energy, leading to sustainability concerns and problems when deploying them on battery-powered devices. In our work, we show how to train small models for such efficiency-critical applications. As opposed to many off-the-shelf NLP pipelines, our models use modern training techniques such as distillation, and offer support for low-resource languages. We call our models TiME (Tiny Monolingual Encoders) and comprehensively evaluate them on a range of common NLP tasks, observing an improved trade-off between benchmark performance on one hand, and throughput, latency and energy consumption on the other. Along the way, we show that distilling monolingual models from multilingual teachers is possible, and likewise distilling models with absolute positional embeddings from teachers with relative positional embeddings.
Neural Redshift: Random Networks are not Random Functions
Mar 05, 2024



Our understanding of the generalization capabilities of neural networks (NNs) is still incomplete. Prevailing explanations are based on implicit biases of gradient descent (GD) but they cannot account for the capabilities of models from gradient-free methods nor the simplicity bias recently observed in untrained networks. This paper seeks other sources of generalization in NNs. Findings. To understand the inductive biases provided by architectures independently from GD, we examine untrained, random-weight networks. Even simple MLPs show strong inductive biases: uniform sampling in weight space yields a very biased distribution of functions in terms of complexity. But unlike common wisdom, NNs do not have an inherent "simplicity bias". This property depends on components such as ReLUs, residual connections, and layer normalizations. Alternative architectures can be built with a bias for any level of complexity. Transformers also inherit all these properties from their building blocks. Implications. We provide a fresh explanation for the success of deep learning independent from gradient-based training. It points at promising avenues for controlling the solutions implemented by trained models.
SoK: Memorization in General-Purpose Large Language Models
Oct 24, 2023
Large Language Models (LLMs) are advancing at a remarkable pace, with myriad applications under development. Unlike most earlier machine learning models, they are no longer built for one specific application but are designed to excel in a wide range of tasks. A major part of this success is due to their huge training datasets and the unprecedented number of model parameters, which allow them to memorize large amounts of information contained in the training data. This memorization goes beyond mere language, and encompasses information only present in a few documents. This is often desirable since it is necessary for performing tasks such as question answering, and therefore an important part of learning, but also brings a whole array of issues, from privacy and security to copyright and beyond. LLMs can memorize short secrets in the training data, but can also memorize concepts like facts or writing styles that can be expressed in text in many different ways. We propose a taxonomy for memorization in LLMs that covers verbatim text, facts, ideas and algorithms, writing styles, distributional properties, and alignment goals. We describe the implications of each type of memorization - both positive and negative - for model performance, privacy, security and confidentiality, copyright, and auditing, and ways to detect and prevent memorization. We further highlight the challenges that arise from the predominant way of defining memorization with respect to model behavior instead of model weights, due to LLM-specific phenomena such as reasoning capabilities or differences between decoding algorithms. Throughout the paper, we describe potential risks and opportunities arising from memorization in LLMs that we hope will motivate new research directions.
Language Model Decoding as Likelihood-Utility Alignment
Oct 13, 2022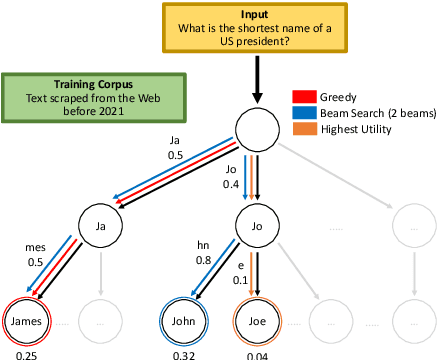

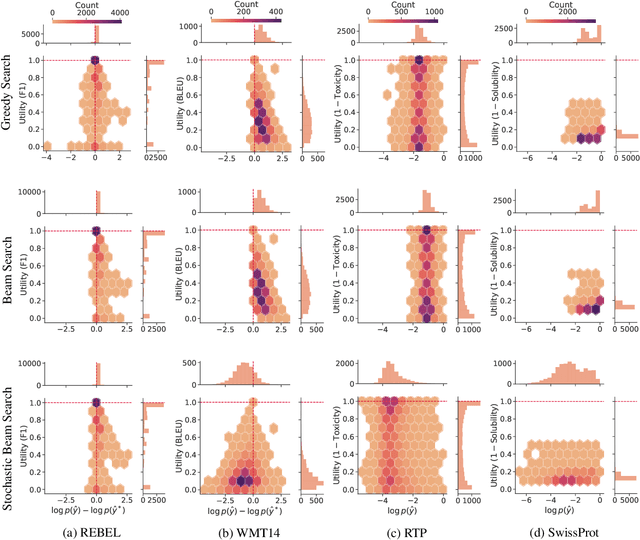
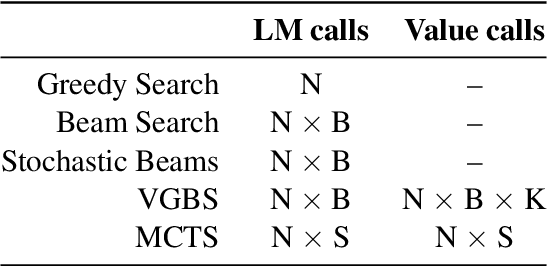
A critical component of a successful language generation pipeline is the decoding algorithm. However, the general principles that should guide the choice of decoding algorithm remain unclear. Previous works only compare decoding algorithms in narrow scenarios and their findings do not generalize across tasks. To better structure the discussion, we introduce a taxonomy that groups decoding strategies based on their implicit assumptions about how well the model's likelihood is aligned with the task-specific notion of utility. We argue that this taxonomy allows a broader view of the decoding problem and can lead to generalizable statements because it is grounded on the interplay between the decoding algorithms and the likelihood-utility misalignment. Specifically, by analyzing the correlation between the likelihood and the utility of predictions across a diverse set of tasks, we provide the first empirical evidence supporting the proposed taxonomy, and a set of principles to structure reasoning when choosing a decoding algorithm. Crucially, our analysis is the first one to relate likelihood-based decoding strategies with strategies that rely on external information such as value-guided methods and prompting, and covers the most diverse set of tasks up-to-date.
Distribution inference risks: Identifying and mitigating sources of leakage
Sep 18, 2022

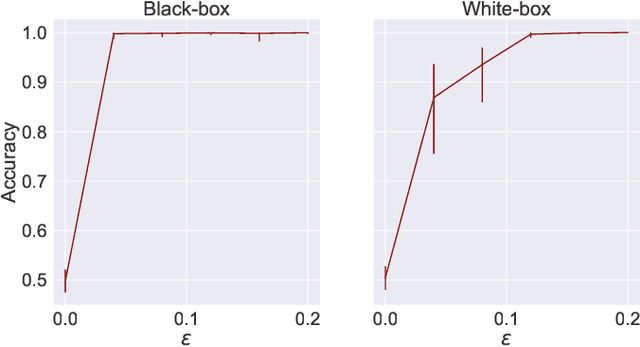
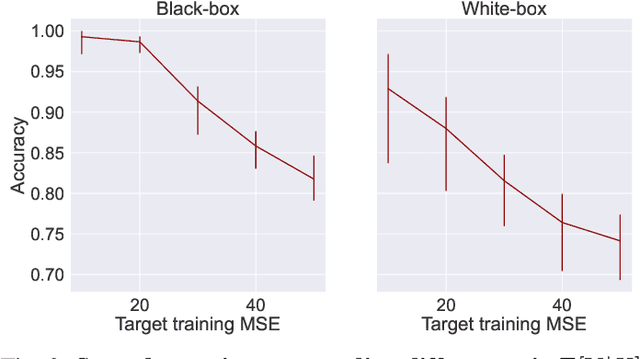
A large body of work shows that machine learning (ML) models can leak sensitive or confidential information about their training data. Recently, leakage due to distribution inference (or property inference) attacks is gaining attention. In this attack, the goal of an adversary is to infer distributional information about the training data. So far, research on distribution inference has focused on demonstrating successful attacks, with little attention given to identifying the potential causes of the leakage and to proposing mitigations. To bridge this gap, as our main contribution, we theoretically and empirically analyze the sources of information leakage that allows an adversary to perpetrate distribution inference attacks. We identify three sources of leakage: (1) memorizing specific information about the $\mathbb{E}[Y|X]$ (expected label given the feature values) of interest to the adversary, (2) wrong inductive bias of the model, and (3) finiteness of the training data. Next, based on our analysis, we propose principled mitigation techniques against distribution inference attacks. Specifically, we demonstrate that causal learning techniques are more resilient to a particular type of distribution inference risk termed distributional membership inference than associative learning methods. And lastly, we present a formalization of distribution inference that allows for reasoning about more general adversaries than was previously possible.
Privacy-Preserving Classification with Secret Vector Machines
Jul 08, 2019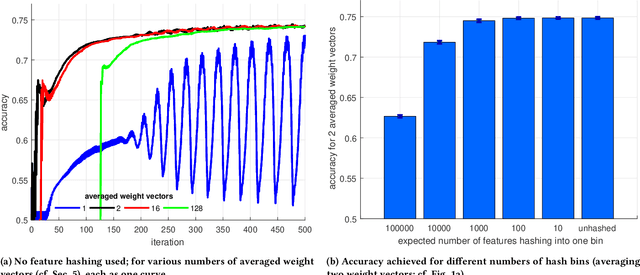


Today, large amounts of valuable data are distributed among millions of user-held devices, such as personal computers, phones, or Internet-of-things devices. Many companies collect such data with the goal of using it for training machine learning models allowing them to improve their services. However, user-held data is often sensitive, and collecting it is problematic in terms of privacy. We address this issue by proposing a novel way of training a supervised classifier in a distributed setting akin to the recently proposed federated learning paradigm (McMahan et al. 2017), but under the stricter privacy requirement that the server that trains the model is assumed to be untrusted and potentially malicious; we thus preserve user privacy by design, rather than by trust. In particular, our framework, called secret vector machine (SecVM), provides an algorithm for training linear support vector machines (SVM) in a setting in which data-holding clients communicate with an untrusted server by exchanging messages designed to not reveal any personally identifiable information. We evaluate our model in two ways. First, in an offline evaluation, we train SecVM to predict user gender from tweets, showing that we can preserve user privacy without sacrificing classification performance. Second, we implement SecVM's distributed framework for the Cliqz web browser and deploy it for predicting user gender in a large-scale online evaluation with thousands of clients, outperforming baselines by a large margin and thus showcasing that SecVM is practicable in production environments. Overall, this work demonstrates the feasibility of machine learning on data from thousands of users without collecting any personal data. We believe this is an innovative approach that will help reconcile machine learning with data privacy.
Privacy-Preserving Distributed Learning with Secret Gradient Descent
Jun 27, 2019
In many important application domains of machine learning, data is a privacy-sensitive resource. In addition, due to the growing complexity of the models, single actors typically do not have sufficient data to train a model on their own. Motivated by these challenges, we propose Secret Gradient Descent (SecGD), a method for training machine learning models on data that is spread over different clients while preserving the privacy of the training data. We achieve this by letting each client add temporary noise to the information they send to the server during the training process. They also share this noise in separate messages with the server, which can then subtract it from the previously received values. By routing all data through an anonymization network such as Tor, we prevent the server from knowing which messages originate from the same client, which in turn allows us to show that breaking a client's privacy is computationally intractable as it would require solving a hard instance of the subset sum problem. This setup allows SecGD to work in the presence of only two honest clients and a malicious server, and without the need for peer-to-peer connections.