 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing Resource Sharing Practices on Underground Internet Forum Synthetic Non-Consensual Intimate Image Content Creation Communities
Apr 14, 2026Many malicious actors responsible for disseminating synthetic non-consensual intimate imagery (SNCII) operate within internet forums to exchange resources, strategies, and generated content across multiple platforms. Technically-sophisticated actors gravitate toward certain communities (e.g., 4chan), while lower-sophistication end-users are more active on others (e.g., Reddit). To characterize key stakeholders in the broader ecosystem, we perform an integrated analysis of multiple communities, analyzing 282,154 4chan comments and 78,308 Reddit submissions spanning 165 days between June and November 2025 to characterize involved actors, actions, and resources. We find: (a) that users with differing levels of technical sophistication employ and share a wide range of primary resources facilitating SNCII content creation as well as numerous secondary resources facilitating dissemination; and (b) that knowledge transfer between experts and newcomers facilitates propagation of these illicit resources. Based on our empirical analysis, we identify gaps in existing SNCII regulatory infrastructure and synthesize several critical intervention points for bolstering deterrence.
Towards Reliable and Generalizable Differentially Private Machine Learning (Extended Version)
Aug 21, 2025There is a flurry of recent research papers proposing novel differentially private machine learning (DPML) techniques. These papers claim to achieve new state-of-the-art (SoTA) results and offer empirical results as validation. However, there is no consensus on which techniques are most effective or if they genuinely meet their stated claims. Complicating matters, heterogeneity in codebases, datasets, methodologies, and model architectures make direct comparisons of different approaches challenging. In this paper, we conduct a reproducibility and replicability (R+R) experiment on 11 different SoTA DPML techniques from the recent research literature. Results of our investigation are varied: while some methods stand up to scrutiny, others falter when tested outside their initial experimental conditions. We also discuss challenges unique to the reproducibility of DPML, including additional randomness due to DP noise, and how to address them. Finally, we derive insights and best practices to obtain scientifically valid and reliable results.
Inference Attacks for X-Vector Speaker Anonymization
May 13, 2025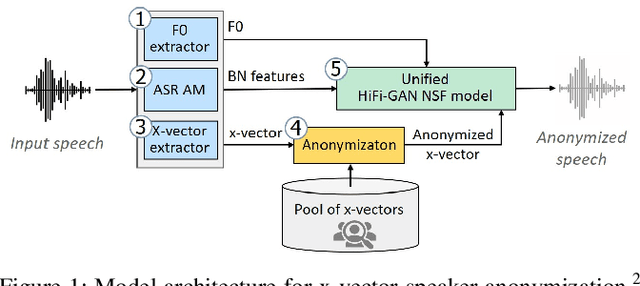
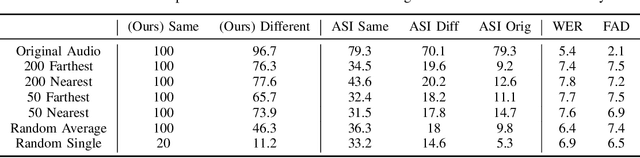
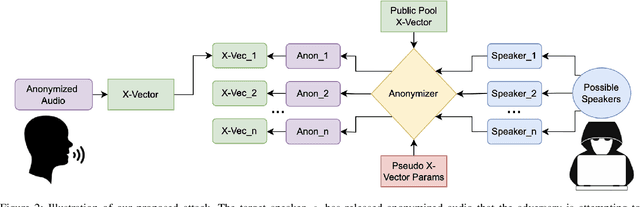

We revisit the privacy-utility tradeoff of x-vector speaker anonymization. Existing approaches quantify privacy through training complex speaker verification or identification models that are later used as attacks. Instead, we propose a novel inference attack for de-anonymization. Our attack is simple and ML-free yet we show experimentally that it outperforms existing approaches.
DP-Mix: Mixup-based Data Augmentation for Differentially Private Learning
Nov 02, 2023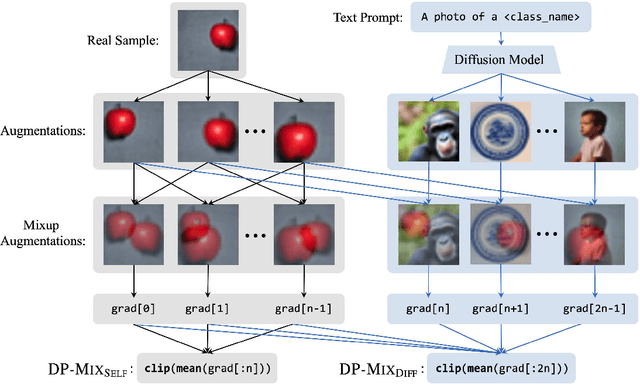

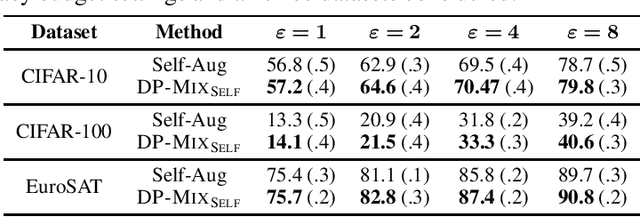
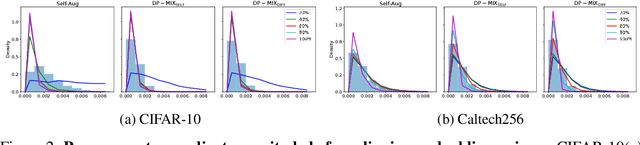
Data augmentation techniques, such as simple image transformations and combinations, are highly effective at improving the generalization of computer vision models, especially when training data is limited. However, such techniques are fundamentally incompatible with differentially private learning approaches, due to the latter's built-in assumption that each training image's contribution to the learned model is bounded. In this paper, we investigate why naive applications of multi-sample data augmentation techniques, such as mixup, fail to achieve good performance and propose two novel data augmentation techniques specifically designed for the constraints of differentially private learning. Our first technique, DP-Mix_Self, achieves SoTA classification performance across a range of datasets and settings by performing mixup on self-augmented data. Our second technique, DP-Mix_Diff, further improves performance by incorporating synthetic data from a pre-trained diffusion model into the mixup process. We open-source the code at https://github.com/wenxuan-Bao/DP-Mix.
SoK: Memorization in General-Purpose Large Language Models
Oct 24, 2023
Large Language Models (LLMs) are advancing at a remarkable pace, with myriad applications under development. Unlike most earlier machine learning models, they are no longer built for one specific application but are designed to excel in a wide range of tasks. A major part of this success is due to their huge training datasets and the unprecedented number of model parameters, which allow them to memorize large amounts of information contained in the training data. This memorization goes beyond mere language, and encompasses information only present in a few documents. This is often desirable since it is necessary for performing tasks such as question answering, and therefore an important part of learning, but also brings a whole array of issues, from privacy and security to copyright and beyond. LLMs can memorize short secrets in the training data, but can also memorize concepts like facts or writing styles that can be expressed in text in many different ways. We propose a taxonomy for memorization in LLMs that covers verbatim text, facts, ideas and algorithms, writing styles, distributional properties, and alignment goals. We describe the implications of each type of memorization - both positive and negative - for model performance, privacy, security and confidentiality, copyright, and auditing, and ways to detect and prevent memorization. We further highlight the challenges that arise from the predominant way of defining memorization with respect to model behavior instead of model weights, due to LLM-specific phenomena such as reasoning capabilities or differences between decoding algorithms. Throughout the paper, we describe potential risks and opportunities arising from memorization in LLMs that we hope will motivate new research directions.
On the Importance of Architecture and Feature Selection in Differentially Private Machine Learning
May 13, 2022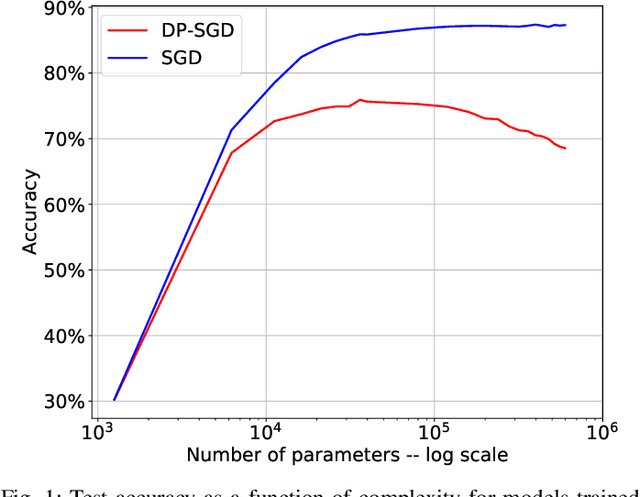
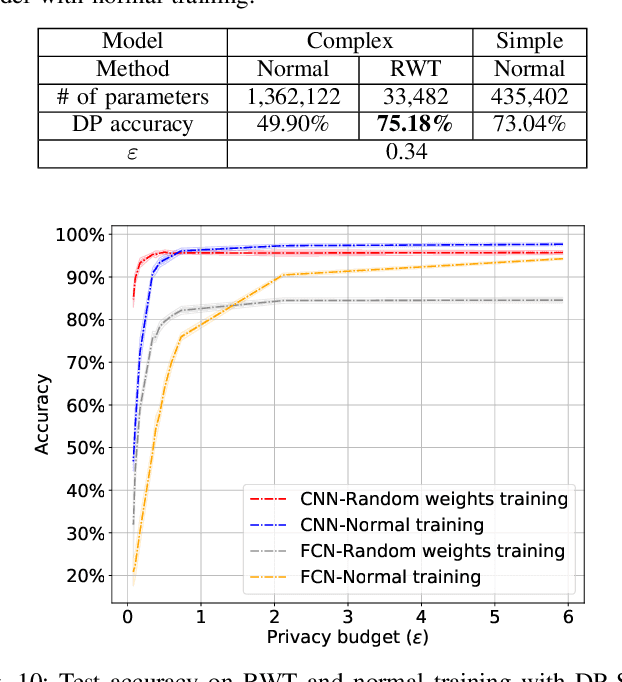
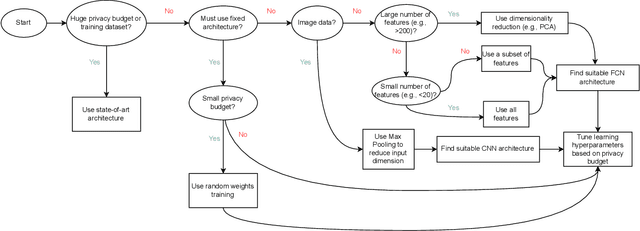
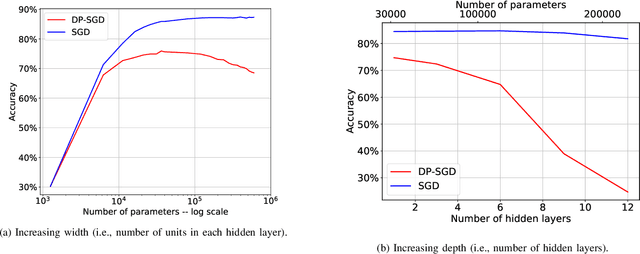
We study a pitfall in the typical workflow for differentially private machine learning. The use of differentially private learning algorithms in a "drop-in" fashion -- without accounting for the impact of differential privacy (DP) noise when choosing what feature engineering operations to use, what features to select, or what neural network architecture to use -- yields overly complex and poorly performing models. In other words, by anticipating the impact of DP noise, a simpler and more accurate alternative model could have been trained for the same privacy guarantee. We systematically study this phenomenon through theory and experiments. On the theory front, we provide an explanatory framework and prove that the phenomenon arises naturally from the addition of noise to satisfy differential privacy. On the experimental front, we demonstrate how the phenomenon manifests in practice using various datasets, types of models, tasks, and neural network architectures. We also analyze the factors that contribute to the problem and distill our experimental insights into concrete takeaways that practitioners can follow when training models with differential privacy. Finally, we propose privacy-aware algorithms for feature selection and neural network architecture search. We analyze their differential privacy properties and evaluate them empirically.
Attacks as Defenses: Designing Robust Audio CAPTCHAs Using Attacks on Automatic Speech Recognition Systems
Mar 10, 2022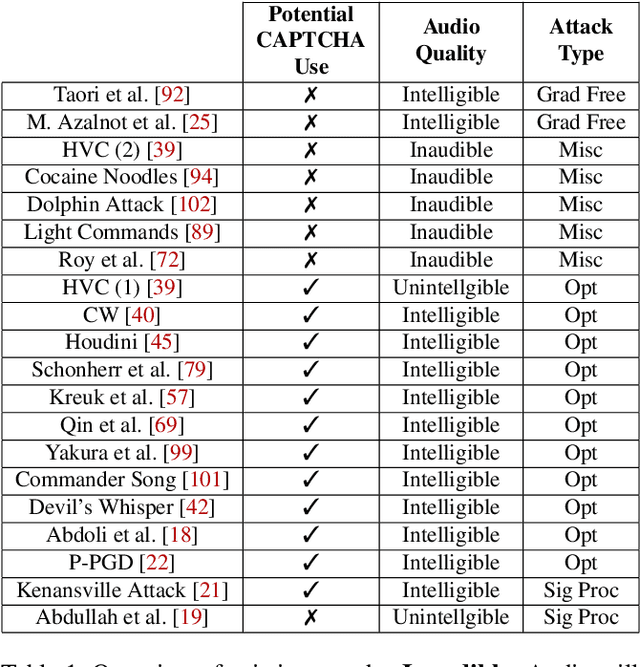
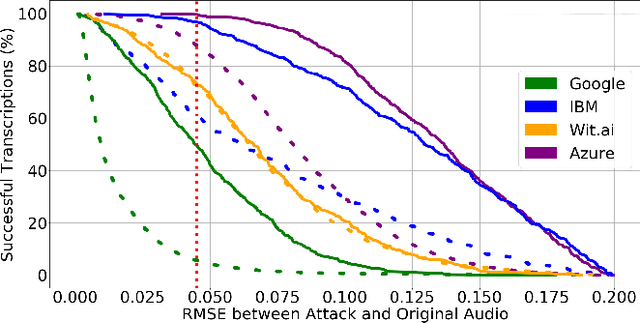

Audio CAPTCHAs are supposed to provide a strong defense for online resources; however, advances in speech-to-text mechanisms have rendered these defenses ineffective. Audio CAPTCHAs cannot simply be abandoned, as they are specifically named by the W3C as important enablers of accessibility. Accordingly, demonstrably more robust audio CAPTCHAs are important to the future of a secure and accessible Web. We look to recent literature on attacks on speech-to-text systems for inspiration for the construction of robust, principle-driven audio defenses. We begin by comparing 20 recent attack papers, classifying and measuring their suitability to serve as the basis of new "robust to transcription" but "easy for humans to understand" CAPTCHAs. After showing that none of these attacks alone are sufficient, we propose a new mechanism that is both comparatively intelligible (evaluated through a user study) and hard to automatically transcribe (i.e., $P({\rm transcription}) = 4 \times 10^{-5}$). Finally, we demonstrate that our audio samples have a high probability of being detected as CAPTCHAs when given to speech-to-text systems ($P({\rm evasion}) = 1.77 \times 10^{-4}$). In so doing, we not only demonstrate a CAPTCHA that is approximately four orders of magnitude more difficult to crack, but that such systems can be designed based on the insights gained from attack papers using the differences between the ways that humans and computers process audio.
Beyond $L_p$ clipping: Equalization-based Psychoacoustic Attacks against ASRs
Oct 25, 2021

Automatic Speech Recognition (ASR) systems convert speech into text and can be placed into two broad categories: traditional and fully end-to-end. Both types have been shown to be vulnerable to adversarial audio examples that sound benign to the human ear but force the ASR to produce malicious transcriptions. Of these attacks, only the "psychoacoustic" attacks can create examples with relatively imperceptible perturbations, as they leverage the knowledge of the human auditory system. Unfortunately, existing psychoacoustic attacks can only be applied against traditional models, and are obsolete against the newer, fully end-to-end ASRs. In this paper, we propose an equalization-based psychoacoustic attack that can exploit both traditional and fully end-to-end ASRs. We successfully demonstrate our attack against real-world ASRs that include DeepSpeech and Wav2Letter. Moreover, we employ a user study to verify that our method creates low audible distortion. Specifically, 80 of the 100 participants voted in favor of all our attack audio samples as less noisier than the existing state-of-the-art attack. Through this, we demonstrate both types of existing ASR pipelines can be exploited with minimum degradation to attack audio quality.
Covert Message Passing over Public Internet Platforms Using Model-Based Format-Transforming Encryption
Oct 13, 2021
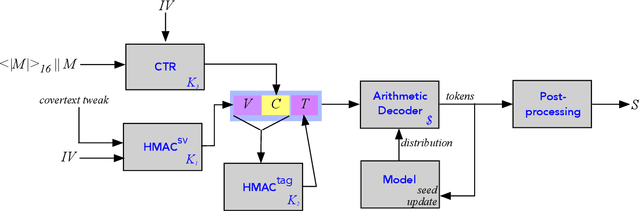

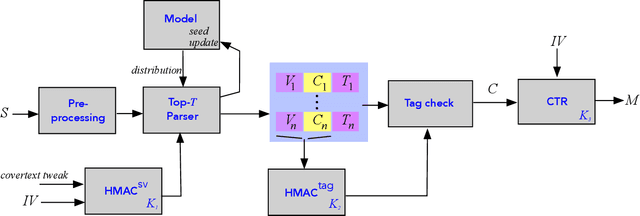
We introduce a new type of format-transforming encryption where the format of ciphertexts is implicitly encoded within a machine-learned generative model. Around this primitive, we build a system for covert messaging over large, public internet platforms (e.g., Twitter). Loosely, our system composes an authenticated encryption scheme, with a method for encoding random ciphertext bits into samples from the generative model's family of seed-indexed token-distributions. By fixing a deployment scenario, we are forced to consider system-level and algorithmic solutions to real challenges -- such as receiver-side parsing ambiguities, and the low information-carrying capacity of actual token-distributions -- that were elided in prior work. We use GPT-2 as our generative model so that our system cryptographically transforms plaintext bitstrings into natural-language covertexts suitable for posting to public platforms. We consider adversaries with full view of the internet platform's content, whose goal is to surface posts that are using our system for covert messaging. We carry out a suite of experiments to provide heuristic evidence of security and to explore tradeoffs between operational efficiency and detectability.
SoK: The Faults in our ASRs: An Overview of Attacks against Automatic Speech Recognition and Speaker Identification Systems
Jul 21, 2020
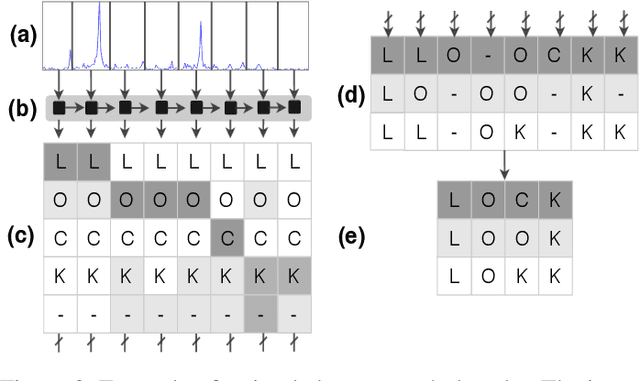
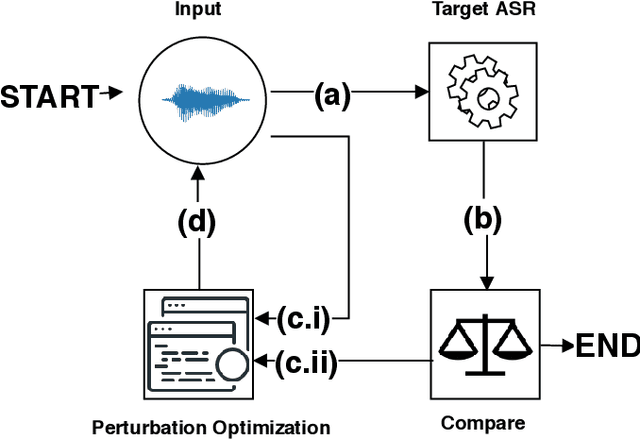
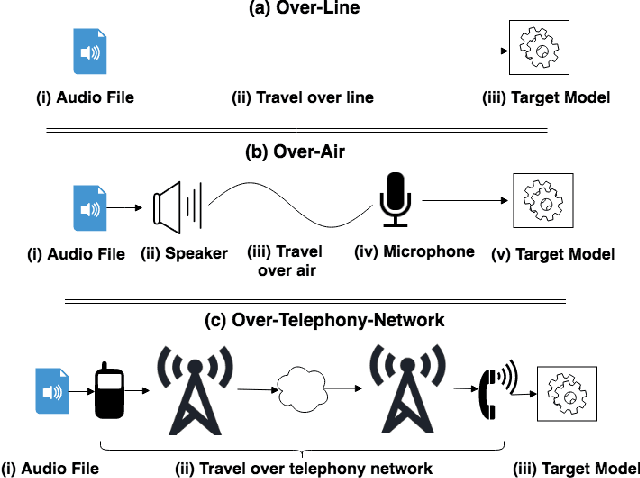
Speech and speaker recognition systems are employed in a variety of applications, from personal assistants to telephony surveillance and biometric authentication. The wide deployment of these systems has been made possible by the improved accuracy in neural networks. Like other systems based on neural networks, recent research has demonstrated that speech and speaker recognition systems are vulnerable to attacks using manipulated inputs. However, as we demonstrate in this paper, the end-to-end architecture of speech and speaker systems and the nature of their inputs make attacks and defenses against them substantially different than those in the image space. We demonstrate this first by systematizing existing research in this space and providing a taxonomy through which the community can evaluate future work. We then demonstrate experimentally that attacks against these models almost universally fail to transfer. In so doing, we argue that substantial additional work is required to provide adequate mitigations in this space.