 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Importance of Architecture and Feature Selection in Differentially Private Machine Learning
May 13, 2022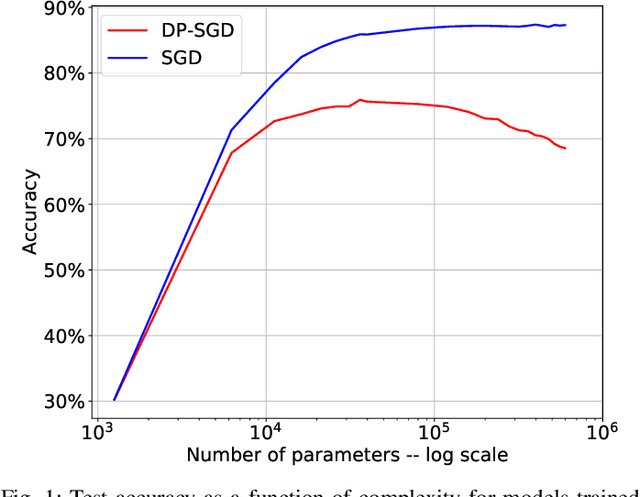
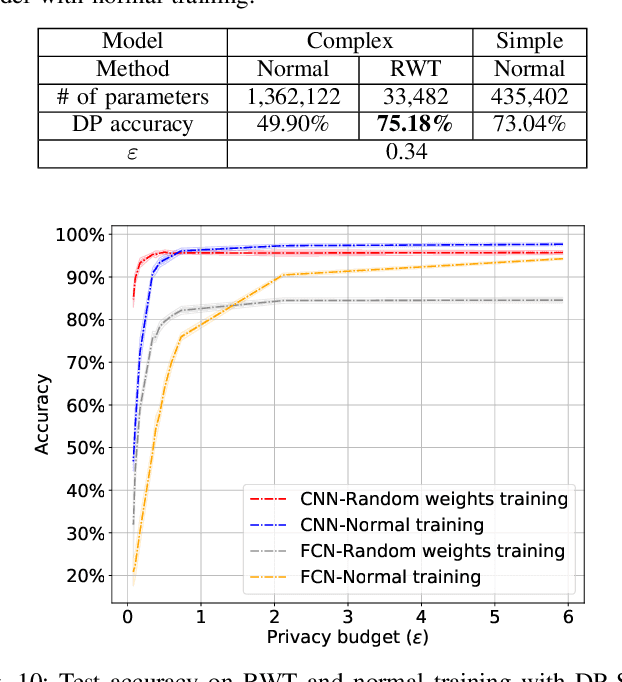
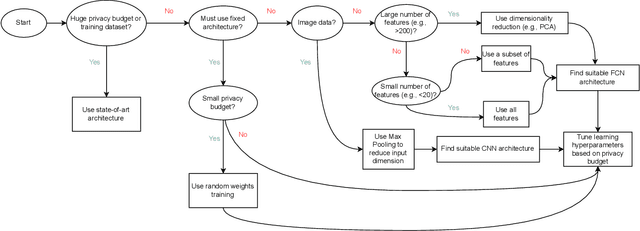
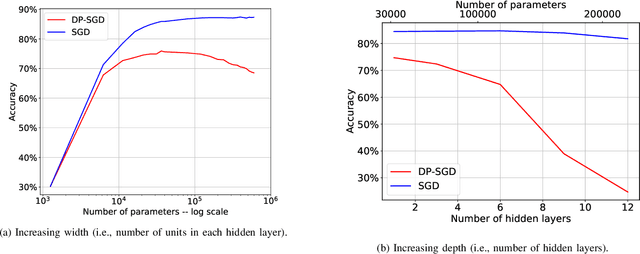
We study a pitfall in the typical workflow for differentially private machine learning. The use of differentially private learning algorithms in a "drop-in" fashion -- without accounting for the impact of differential privacy (DP) noise when choosing what feature engineering operations to use, what features to select, or what neural network architecture to use -- yields overly complex and poorly performing models. In other words, by anticipating the impact of DP noise, a simpler and more accurate alternative model could have been trained for the same privacy guarantee. We systematically study this phenomenon through theory and experiments. On the theory front, we provide an explanatory framework and prove that the phenomenon arises naturally from the addition of noise to satisfy differential privacy. On the experimental front, we demonstrate how the phenomenon manifests in practice using various datasets, types of models, tasks, and neural network architectures. We also analyze the factors that contribute to the problem and distill our experimental insights into concrete takeaways that practitioners can follow when training models with differential privacy. Finally, we propose privacy-aware algorithms for feature selection and neural network architecture search. We analyze their differential privacy properties and evaluate them empirically.
Attacks as Defenses: Designing Robust Audio CAPTCHAs Using Attacks on Automatic Speech Recognition Systems
Mar 10, 2022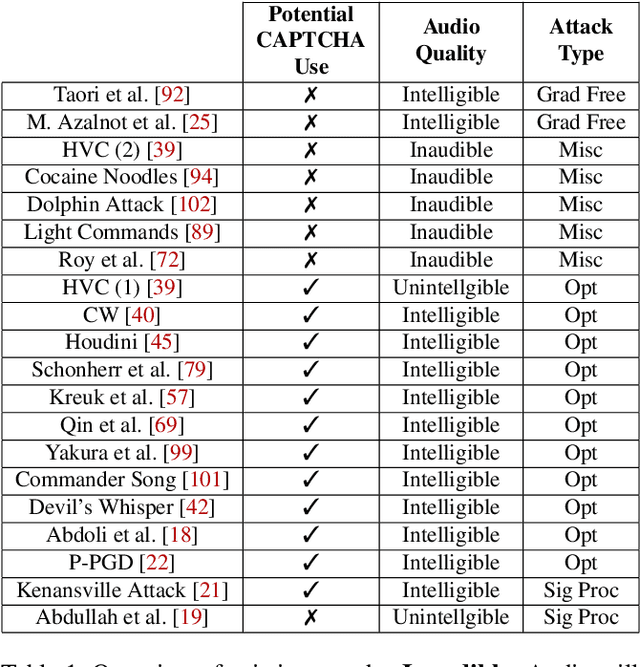
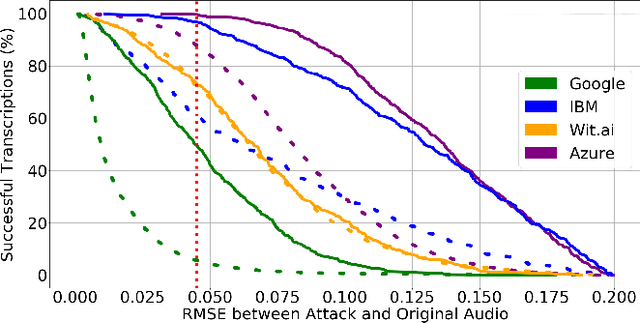

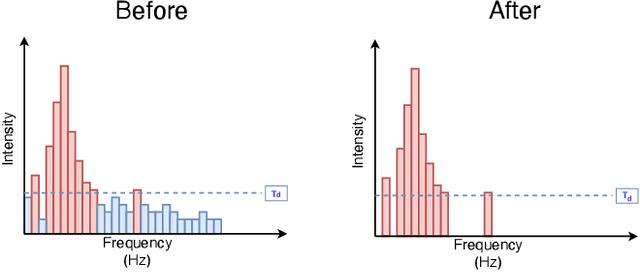
Audio CAPTCHAs are supposed to provide a strong defense for online resources; however, advances in speech-to-text mechanisms have rendered these defenses ineffective. Audio CAPTCHAs cannot simply be abandoned, as they are specifically named by the W3C as important enablers of accessibility. Accordingly, demonstrably more robust audio CAPTCHAs are important to the future of a secure and accessible Web. We look to recent literature on attacks on speech-to-text systems for inspiration for the construction of robust, principle-driven audio defenses. We begin by comparing 20 recent attack papers, classifying and measuring their suitability to serve as the basis of new "robust to transcription" but "easy for humans to understand" CAPTCHAs. After showing that none of these attacks alone are sufficient, we propose a new mechanism that is both comparatively intelligible (evaluated through a user study) and hard to automatically transcribe (i.e., $P({\rm transcription}) = 4 \times 10^{-5}$). Finally, we demonstrate that our audio samples have a high probability of being detected as CAPTCHAs when given to speech-to-text systems ($P({\rm evasion}) = 1.77 \times 10^{-4}$). In so doing, we not only demonstrate a CAPTCHA that is approximately four orders of magnitude more difficult to crack, but that such systems can be designed based on the insights gained from attack papers using the differences between the ways that humans and computers process audio.
Covert Message Passing over Public Internet Platforms Using Model-Based Format-Transforming Encryption
Oct 13, 2021
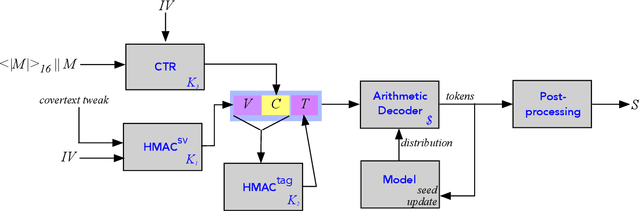

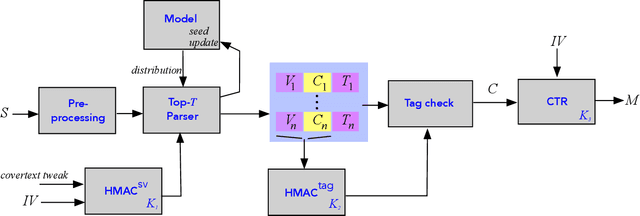
We introduce a new type of format-transforming encryption where the format of ciphertexts is implicitly encoded within a machine-learned generative model. Around this primitive, we build a system for covert messaging over large, public internet platforms (e.g., Twitter). Loosely, our system composes an authenticated encryption scheme, with a method for encoding random ciphertext bits into samples from the generative model's family of seed-indexed token-distributions. By fixing a deployment scenario, we are forced to consider system-level and algorithmic solutions to real challenges -- such as receiver-side parsing ambiguities, and the low information-carrying capacity of actual token-distributions -- that were elided in prior work. We use GPT-2 as our generative model so that our system cryptographically transforms plaintext bitstrings into natural-language covertexts suitable for posting to public platforms. We consider adversaries with full view of the internet platform's content, whose goal is to surface posts that are using our system for covert messaging. We carry out a suite of experiments to provide heuristic evidence of security and to explore tradeoffs between operational efficiency and detectability.