 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRamen: Robust Test-Time Adaptation of Vision-Language Models with Active Sample Selection
Apr 23, 2026Pretrained vision-language models such as CLIP exhibit strong zero-shot generalization but remain sensitive to distribution shifts. Test-time adaptation adapts models during inference without access to source data or target labels, offering a practical way to handle such shifts. However, existing methods typically assume that test samples come from a single, consistent domain, while in practice, test data often include samples from mixed domains with distinct characteristics. Consequently, their performance degrades under mixed-domain settings. To address this, we present Ramen, a framework for robust test-time adaptation through active sample selection. For each incoming test sample, Ramen retrieves a customized batch of relevant samples from previously seen data based on two criteria: domain consistency, which ensures that adaptation focuses on data from similar domains, and prediction balance, which mitigates adaptation bias caused by skewed predictions. To improve efficiency, Ramen employs an embedding-gradient cache that stores the embeddings and sample-level gradients of past test images. The stored embeddings are used to retrieve relevant samples, and the corresponding gradients are aggregated for model updates, eliminating the need for any additional forward or backward passes. Our theoretical analysis provides insight into why the proposed adaptation mechanism is effective under mixed-domain shifts. Experiments on multiple image corruption and domain-shift benchmarks demonstrate that Ramen achieves strong and consistent performance, offering robust and efficient adaptation in complex mixed-domain scenarios. Our code is available at https://github.com/baowenxuan/Ramen .
FeDecider: An LLM-Based Framework for Federated Cross-Domain Recommendation
Feb 17, 2026Federated cross-domain recommendation (Federated CDR) aims to collaboratively learn personalized recommendation models across heterogeneous domains while preserving data privacy. Recently, large language model (LLM)-based recommendation models have demonstrated impressive performance by leveraging LLMs' strong reasoning capabilities and broad knowledge. However, adopting LLM-based recommendation models in Federated CDR scenarios introduces new challenges. First, there exists a risk of overfitting with domain-specific local adapters. The magnitudes of locally optimized parameter updates often vary across domains, causing biased aggregation and overfitting toward domain-specific distributions. Second, unlike traditional recommendation models (e.g., collaborative filtering, bipartite graph-based methods) that learn explicit and comparable user/item representations, LLMs encode knowledge implicitly through autoregressive text generation training. This poses additional challenges for effectively measuring the cross-domain similarities under heterogeneity. To address these challenges, we propose an LLM-based framework for federated cross-domain recommendation, FeDecider. Specifically, FeDecider tackles the challenge of scale-specific noise by disentangling each client's low-rank updates and sharing only their directional components. To handle the need for flexible and effective integration, each client further learns personalized weights that achieve the data-aware integration of updates from other domains. Extensive experiments across diverse datasets validate the effectiveness of our proposed FeDecider.
Agentic Reasoning for Large Language Models
Jan 18, 2026Reasoning is a fundamental cognitive process underlying inference, problem-solving, and decision-making. While large language models (LLMs) demonstrate strong reasoning capabilities in closed-world settings, they struggle in open-ended and dynamic environments. Agentic reasoning marks a paradigm shift by reframing LLMs as autonomous agents that plan, act, and learn through continual interaction. In this survey, we organize agentic reasoning along three complementary dimensions. First, we characterize environmental dynamics through three layers: foundational agentic reasoning, which establishes core single-agent capabilities including planning, tool use, and search in stable environments; self-evolving agentic reasoning, which studies how agents refine these capabilities through feedback, memory, and adaptation; and collective multi-agent reasoning, which extends intelligence to collaborative settings involving coordination, knowledge sharing, and shared goals. Across these layers, we distinguish in-context reasoning, which scales test-time interaction through structured orchestration, from post-training reasoning, which optimizes behaviors via reinforcement learning and supervised fine-tuning. We further review representative agentic reasoning frameworks across real-world applications and benchmarks, including science, robotics, healthcare, autonomous research, and mathematics. This survey synthesizes agentic reasoning methods into a unified roadmap bridging thought and action, and outlines open challenges and future directions, including personalization, long-horizon interaction, world modeling, scalable multi-agent training, and governance for real-world deployment.
Subspace Alignment for Vision-Language Model Test-time Adaptation
Jan 13, 2026Vision-language models (VLMs), despite their extraordinary zero-shot capabilities, are vulnerable to distribution shifts. Test-time adaptation (TTA) emerges as a predominant strategy to adapt VLMs to unlabeled test data on the fly. However, existing TTA methods heavily rely on zero-shot predictions as pseudo-labels for self-training, which can be unreliable under distribution shifts and misguide adaptation due to two fundamental limitations. First (Modality Gap), distribution shifts induce gaps between visual and textual modalities, making cross-modal relations inaccurate. Second (Visual Nuisance), visual embeddings encode rich but task-irrelevant noise that often overwhelms task-specific semantics under distribution shifts. To address these limitations, we propose SubTTA, which aligns the semantic subspaces of both modalities to enhance zero-shot predictions to better guide the TTA process. To bridge the modality gap, SubTTA extracts the principal subspaces of both modalities and aligns the visual manifold to the textual semantic anchor by minimizing their chordal distance. To eliminate visual nuisance, SubTTA projects the aligned visual features onto the task-specific textual subspace, which filters out task-irrelevant noise by constraining visual embeddings within the valid semantic span, and standard TTA is further performed on the purified space to refine the decision boundaries. Extensive experiments on various benchmarks and VLM architectures demonstrate the effectiveness of SubTTA, yielding an average improvement of 2.24% over state-of-the-art TTA methods.
Panda: Test-Time Adaptation with Negative Data Augmentation
Nov 13, 2025Pretrained VLMs exhibit strong zero-shot classification capabilities, but their predictions degrade significantly under common image corruptions. To improve robustness, many test-time adaptation (TTA) methods adopt positive data augmentation (PDA), which generates multiple views of each test sample to reduce prediction variance. However, these methods suffer from two key limitations. First, it introduces considerable computational overhead due to the large number of augmentations required per image. Second, it fails to mitigate prediction bias, where the model tends to predict certain classes disproportionately under corruption, as PDA operates on corrupted inputs and typically does not remove the corruption itself. To address these challenges, we propose Panda, a novel TTA method based on negative data augmentation (NDA). Unlike positive augmentations that preserve object semantics, Panda generates negative augmentations by disrupting semantic content. It divides images into patches and randomly assembles them from a shared patch pool. These negatively augmented images retain corruption-specific features while discarding object-relevant signals. We then subtract the mean feature of these negative samples from the original image feature, effectively suppressing corruption-related components while preserving class-relevant information. This mitigates prediction bias under distribution shifts. Panda allows augmentation to be shared across samples within a batch, resulting in minimal computational overhead. Panda can be seamlessly integrated into existing test-time adaptation frameworks and substantially improve their robustness. Our experiments indicate that Panda delivers superior performance compared to PDA methods, and a wide range of TTA methods exhibit significantly enhanced performance when integrated with Panda. Our code is available at https://github.com/ruxideng/Panda .
Towards Reliable and Generalizable Differentially Private Machine Learning (Extended Version)
Aug 21, 2025There is a flurry of recent research papers proposing novel differentially private machine learning (DPML) techniques. These papers claim to achieve new state-of-the-art (SoTA) results and offer empirical results as validation. However, there is no consensus on which techniques are most effective or if they genuinely meet their stated claims. Complicating matters, heterogeneity in codebases, datasets, methodologies, and model architectures make direct comparisons of different approaches challenging. In this paper, we conduct a reproducibility and replicability (R+R) experiment on 11 different SoTA DPML techniques from the recent research literature. Results of our investigation are varied: while some methods stand up to scrutiny, others falter when tested outside their initial experimental conditions. We also discuss challenges unique to the reproducibility of DPML, including additional randomness due to DP noise, and how to address them. Finally, we derive insights and best practices to obtain scientifically valid and reliable results.
Pave Your Own Path: Graph Gradual Domain Adaptation on Fused Gromov-Wasserstein Geodesics
May 19, 2025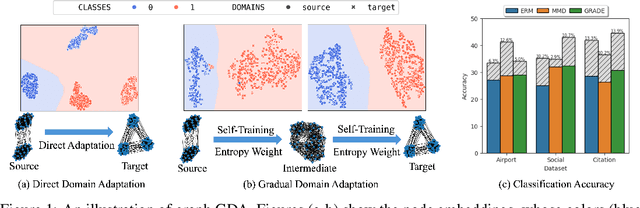
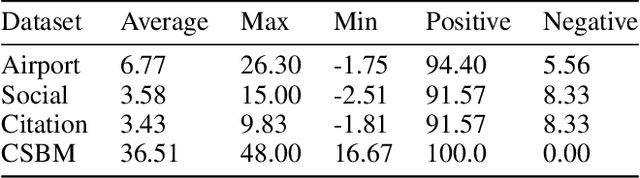
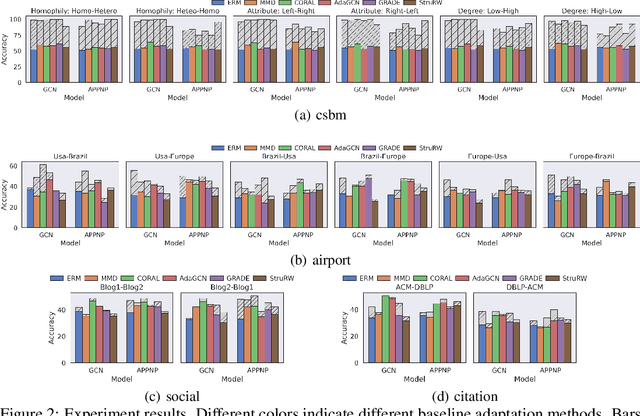
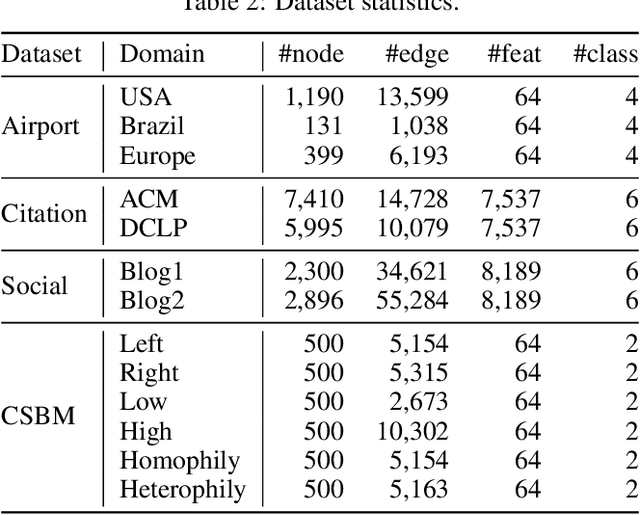
Graph neural networks, despite their impressive performance, are highly vulnerable to distribution shifts on graphs. Existing graph domain adaptation (graph DA) methods often implicitly assume a \textit{mild} shift between source and target graphs, limiting their applicability to real-world scenarios with \textit{large} shifts. Gradual domain adaptation (GDA) has emerged as a promising approach for addressing large shifts by gradually adapting the source model to the target domain via a path of unlabeled intermediate domains. Existing GDA methods exclusively focus on independent and identically distributed (IID) data with a predefined path, leaving their extension to \textit{non-IID graphs without a given path} an open challenge. To bridge this gap, we present Gadget, the first GDA framework for non-IID graph data. First (\textit{theoretical foundation}), the Fused Gromov-Wasserstein (FGW) distance is adopted as the domain discrepancy for non-IID graphs, based on which, we derive an error bound revealing that the target domain error is proportional to the length of the path. Second (\textit{optimal path}), guided by the error bound, we identify the FGW geodesic as the optimal path, which can be efficiently generated by our proposed algorithm. The generated path can be seamlessly integrated with existing graph DA methods to handle large shifts on graphs, improving state-of-the-art graph DA methods by up to 6.8\% in node classification accuracy on real-world datasets.
Inference Attacks for X-Vector Speaker Anonymization
May 13, 2025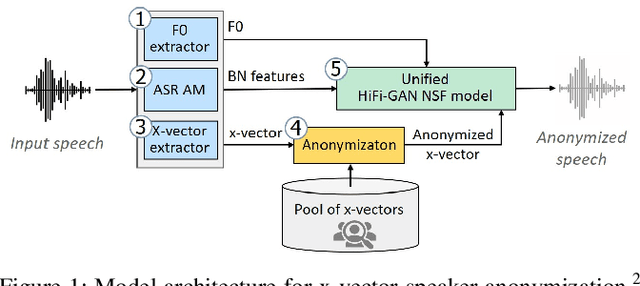
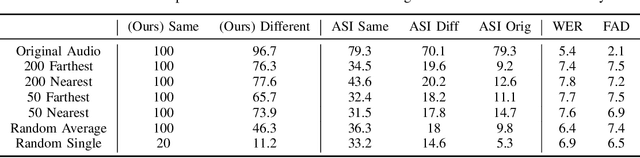
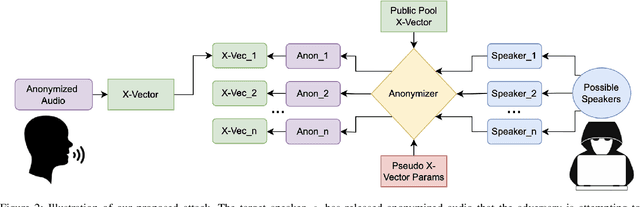

We revisit the privacy-utility tradeoff of x-vector speaker anonymization. Existing approaches quantify privacy through training complex speaker verification or identification models that are later used as attacks. Instead, we propose a novel inference attack for de-anonymization. Our attack is simple and ML-free yet we show experimentally that it outperforms existing approaches.
Ask, and it shall be given: Turing completeness of prompting
Nov 04, 2024Since the success of GPT, large language models (LLMs) have been revolutionizing machine learning and have initiated the so-called LLM prompting paradigm. In the era of LLMs, people train a single general-purpose LLM and provide the LLM with different prompts to perform different tasks. However, such empirical success largely lacks theoretical understanding. Here, we present the first theoretical study on the LLM prompting paradigm to the best of our knowledge. In this work, we show that prompting is in fact Turing-complete: there exists a finite-size Transformer such that for any computable function, there exists a corresponding prompt following which the Transformer computes the function. Furthermore, we show that even though we use only a single finite-size Transformer, it can still achieve nearly the same complexity bounds as that of the class of all unbounded-size Transformers. Overall, our result reveals that prompting can enable a single finite-size Transformer to be efficiently universal, which establishes a theoretical underpinning for prompt engineering in practice.
AdaRC: Mitigating Graph Structure Shifts during Test-Time
Oct 09, 2024



Powerful as they are, graph neural networks (GNNs) are known to be vulnerable to distribution shifts. Recently, test-time adaptation (TTA) has attracted attention due to its ability to adapt a pre-trained model to a target domain without re-accessing the source domain. However, existing TTA algorithms are primarily designed for attribute shifts in vision tasks, where samples are independent. These methods perform poorly on graph data that experience structure shifts, where node connectivity differs between source and target graphs. We attribute this performance gap to the distinct impact of node attribute shifts versus graph structure shifts: the latter significantly degrades the quality of node representations and blurs the boundaries between different node categories. To address structure shifts in graphs, we propose AdaRC, an innovative framework designed for effective and efficient adaptation to structure shifts by adjusting the hop-aggregation parameters in GNNs. To enhance the representation quality, we design a prediction-informed clustering loss to encourage the formation of distinct clusters for different node categories. Additionally, AdaRC seamlessly integrates with existing TTA algorithms, allowing it to handle attribute shifts effectively while improving overall performance under combined structure and attribute shifts. We validate the effectiveness of AdaRC on both synthetic and real-world datasets, demonstrating its robustness across various combinations of structure and attribute shifts.