 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradMetaNet: An Equivariant Architecture for Learning on Gradients
Jul 02, 2025Gradients of neural networks encode valuable information for optimization, editing, and analysis of models. Therefore, practitioners often treat gradients as inputs to task-specific algorithms, e.g. for pruning or optimization. Recent works explore learning algorithms that operate directly on gradients but use architectures that are not specifically designed for gradient processing, limiting their applicability. In this paper, we present a principled approach for designing architectures that process gradients. Our approach is guided by three principles: (1) equivariant design that preserves neuron permutation symmetries, (2) processing sets of gradients across multiple data points to capture curvature information, and (3) efficient gradient representation through rank-1 decomposition. Based on these principles, we introduce GradMetaNet, a novel architecture for learning on gradients, constructed from simple equivariant blocks. We prove universality results for GradMetaNet, and show that previous approaches cannot approximate natural gradient-based functions that GradMetaNet can. We then demonstrate GradMetaNet's effectiveness on a diverse set of gradient-based tasks on MLPs and transformers, such as learned optimization, INR editing, and estimating loss landscape curvature.
UmbraTTS: Adapting Text-to-Speech to Environmental Contexts with Flow Matching
Jun 11, 2025Recent advances in Text-to-Speech (TTS) have enabled highly natural speech synthesis, yet integrating speech with complex background environments remains challenging. We introduce UmbraTTS, a flow-matching based TTS model that jointly generates both speech and environmental audio, conditioned on text and acoustic context. Our model allows fine-grained control over background volume and produces diverse, coherent, and context-aware audio scenes. A key challenge is the lack of data with speech and background audio aligned in natural context. To overcome the lack of paired training data, we propose a self-supervised framework that extracts speech, background audio, and transcripts from unannotated recordings. Extensive evaluations demonstrate that UmbraTTS significantly outperformed existing baselines, producing natural, high-quality, environmentally aware audios.
FlowTSE: Target Speaker Extraction with Flow Matching
May 20, 2025Target speaker extraction (TSE) aims to isolate a specific speaker's speech from a mixture using speaker enrollment as a reference. While most existing approaches are discriminative, recent generative methods for TSE achieve strong results. However, generative methods for TSE remain underexplored, with most existing approaches relying on complex pipelines and pretrained components, leading to computational overhead. In this work, we present FlowTSE, a simple yet effective TSE approach based on conditional flow matching. Our model receives an enrollment audio sample and a mixed speech signal, both represented as mel-spectrograms, with the objective of extracting the target speaker's clean speech. Furthermore, for tasks where phase reconstruction is crucial, we propose a novel vocoder conditioned on the complex STFT of the mixed signal, enabling improved phase estimation. Experimental results on standard TSE benchmarks show that FlowTSE matches or outperforms strong baselines.
Go Beyond Your Means: Unlearning with Per-Sample Gradient Orthogonalization
Mar 04, 2025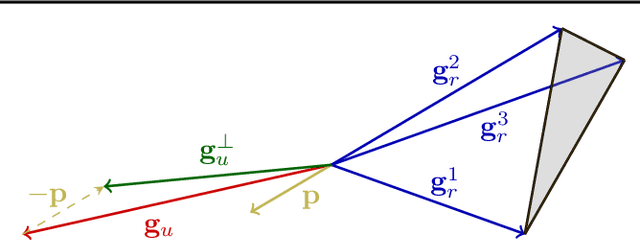
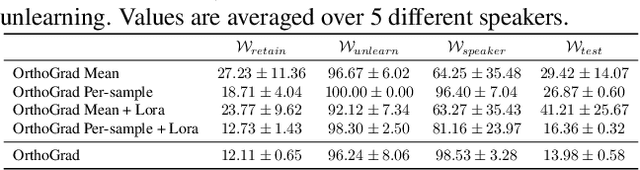

Machine unlearning aims to remove the influence of problematic training data after a model has been trained. The primary challenge in machine unlearning is ensuring that the process effectively removes specified data without compromising the model's overall performance on the remaining dataset. Many existing machine unlearning methods address this challenge by carefully balancing gradient ascent on the unlearn data with the gradient descent on a retain set representing the training data. Here, we propose OrthoGrad, a novel approach that mitigates interference between the unlearn set and the retain set rather than competing ascent and descent processes. Our method projects the gradient of the unlearn set onto the subspace orthogonal to all gradients in the retain batch, effectively avoiding any gradient interference. We demonstrate the effectiveness of OrthoGrad on multiple machine unlearning benchmarks, including automatic speech recognition, outperforming competing methods.
Whisper in Medusa's Ear: Multi-head Efficient Decoding for Transformer-based ASR
Sep 24, 2024



Large transformer-based models have significant potential for speech transcription and translation. Their self-attention mechanisms and parallel processing enable them to capture complex patterns and dependencies in audio sequences. However, this potential comes with challenges, as these large and computationally intensive models lead to slow inference speeds. Various optimization strategies have been proposed to improve performance, including efficient hardware utilization and algorithmic enhancements. In this paper, we introduce Whisper-Medusa, a novel approach designed to enhance processing speed with minimal impact on Word Error Rate (WER). The proposed model extends the OpenAI's Whisper architecture by predicting multiple tokens per iteration, resulting in a 50% reduction in latency. We showcase the effectiveness of Whisper-Medusa across different learning setups and datasets.
WhisperNER: Unified Open Named Entity and Speech Recognition
Sep 12, 2024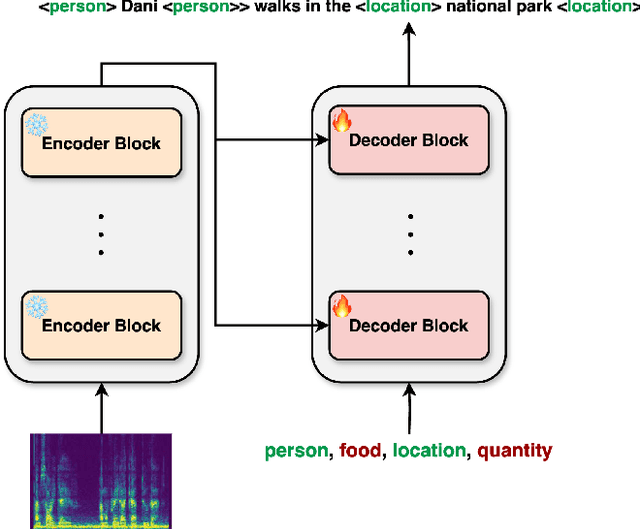
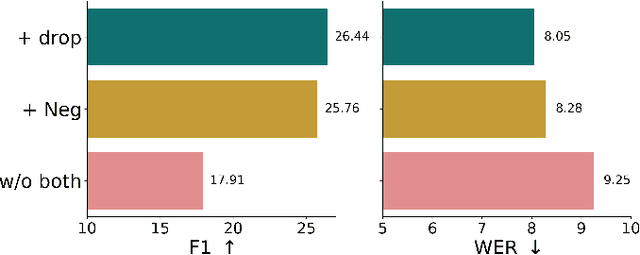
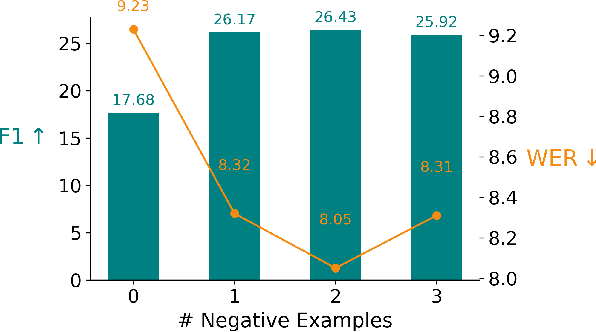

Integrating named entity recognition (NER) with automatic speech recognition (ASR) can significantly enhance transcription accuracy and informativeness. In this paper, we introduce WhisperNER, a novel model that allows joint speech transcription and entity recognition. WhisperNER supports open-type NER, enabling recognition of diverse and evolving entities at inference. Building on recent advancements in open NER research, we augment a large synthetic dataset with synthetic speech samples. This allows us to train WhisperNER on a large number of examples with diverse NER tags. During training, the model is prompted with NER labels and optimized to output the transcribed utterance along with the corresponding tagged entities. To evaluate WhisperNER, we generate synthetic speech for commonly used NER benchmarks and annotate existing ASR datasets with open NER tags. Our experiments demonstrate that WhisperNER outperforms natural baselines on both out-of-domain open type NER and supervised finetuning.
Keyword-Guided Adaptation of Automatic Speech Recognition
Jun 04, 2024



Automatic Speech Recognition (ASR) technology has made significant progress in recent years, providing accurate transcription across various domains. However, some challenges remain, especially in noisy environments and specialized jargon. In this paper, we propose a novel approach for improved jargon word recognition by contextual biasing Whisper-based models. We employ a keyword spotting model that leverages the Whisper encoder representation to dynamically generate prompts for guiding the decoder during the transcription process. We introduce two approaches to effectively steer the decoder towards these prompts: KG-Whisper, which is aimed at fine-tuning the Whisper decoder, and KG-Whisper-PT, which learns a prompt prefix. Our results show a significant improvement in the recognition accuracy of specified keywords and in reducing the overall word error rates. Specifically, in unseen language generalization, we demonstrate an average WER improvement of 5.1% over Whisper.
FedSelect: Personalized Federated Learning with Customized Selection of Parameters for Fine-Tuning
Apr 03, 2024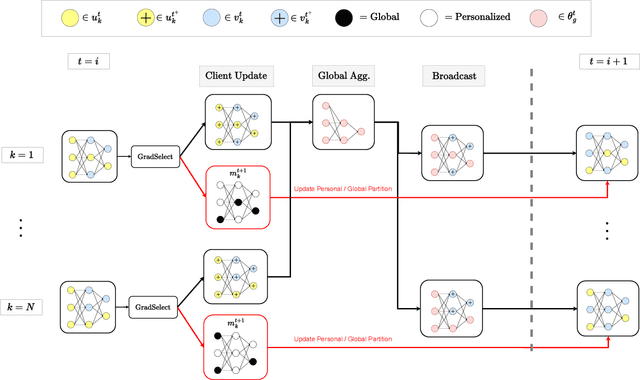
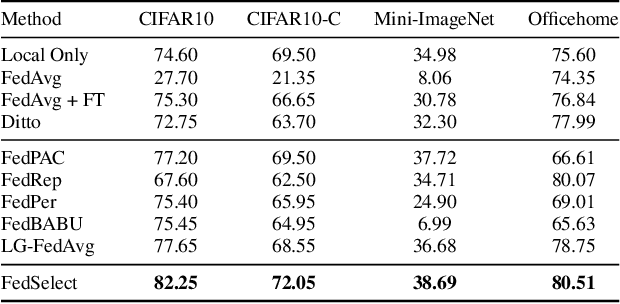
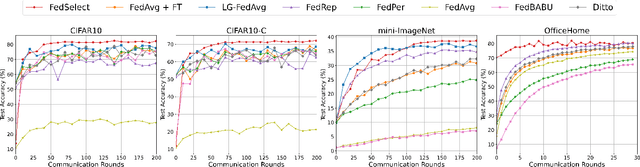
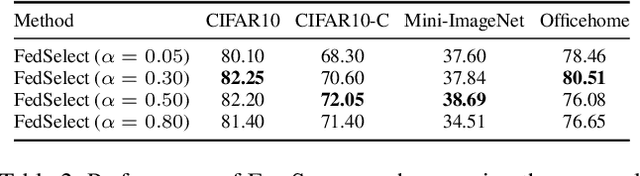
Standard federated learning approaches suffer when client data distributions have sufficient heterogeneity. Recent methods addressed the client data heterogeneity issue via personalized federated learning (PFL) - a class of FL algorithms aiming to personalize learned global knowledge to better suit the clients' local data distributions. Existing PFL methods usually decouple global updates in deep neural networks by performing personalization on particular layers (i.e. classifier heads) and global aggregation for the rest of the network. However, preselecting network layers for personalization may result in suboptimal storage of global knowledge. In this work, we propose FedSelect, a novel PFL algorithm inspired by the iterative subnetwork discovery procedure used for the Lottery Ticket Hypothesis. FedSelect incrementally expands subnetworks to personalize client parameters, concurrently conducting global aggregations on the remaining parameters. This approach enables the personalization of both client parameters and subnetwork structure during the training process. Finally, we show that FedSelect outperforms recent state-of-the-art PFL algorithms under challenging client data heterogeneity settings and demonstrates robustness to various real-world distributional shifts. Our code is available at https://github.com/lapisrocks/fedselect.
Multi Task Inverse Reinforcement Learning for Common Sense Reward
Feb 17, 2024One of the challenges in applying reinforcement learning in a complex real-world environment lies in providing the agent with a sufficiently detailed reward function. Any misalignment between the reward and the desired behavior can result in unwanted outcomes. This may lead to issues like "reward hacking" where the agent maximizes rewards by unintended behavior. In this work, we propose to disentangle the reward into two distinct parts. A simple task-specific reward, outlining the particulars of the task at hand, and an unknown common-sense reward, indicating the expected behavior of the agent within the environment. We then explore how this common-sense reward can be learned from expert demonstrations. We first show that inverse reinforcement learning, even when it succeeds in training an agent, does not learn a useful reward function. That is, training a new agent with the learned reward does not impair the desired behaviors. We then demonstrate that this problem can be solved by training simultaneously on multiple tasks. That is, multi-task inverse reinforcement learning can be applied to learn a useful reward function.
Improved Generalization of Weight Space Networks via Augmentations
Feb 06, 2024Learning in deep weight spaces (DWS), where neural networks process the weights of other neural networks, is an emerging research direction, with applications to 2D and 3D neural fields (INRs, NeRFs), as well as making inferences about other types of neural networks. Unfortunately, weight space models tend to suffer from substantial overfitting. We empirically analyze the reasons for this overfitting and find that a key reason is the lack of diversity in DWS datasets. While a given object can be represented by many different weight configurations, typical INR training sets fail to capture variability across INRs that represent the same object. To address this, we explore strategies for data augmentation in weight spaces and propose a MixUp method adapted for weight spaces. We demonstrate the effectiveness of these methods in two setups. In classification, they improve performance similarly to having up to 10 times more data. In self-supervised contrastive learning, they yield substantial 5-10% gains in downstream classification.