 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhisper in Medusa's Ear: Multi-head Efficient Decoding for Transformer-based ASR
Sep 24, 2024



Large transformer-based models have significant potential for speech transcription and translation. Their self-attention mechanisms and parallel processing enable them to capture complex patterns and dependencies in audio sequences. However, this potential comes with challenges, as these large and computationally intensive models lead to slow inference speeds. Various optimization strategies have been proposed to improve performance, including efficient hardware utilization and algorithmic enhancements. In this paper, we introduce Whisper-Medusa, a novel approach designed to enhance processing speed with minimal impact on Word Error Rate (WER). The proposed model extends the OpenAI's Whisper architecture by predicting multiple tokens per iteration, resulting in a 50% reduction in latency. We showcase the effectiveness of Whisper-Medusa across different learning setups and datasets.
WhisperNER: Unified Open Named Entity and Speech Recognition
Sep 12, 2024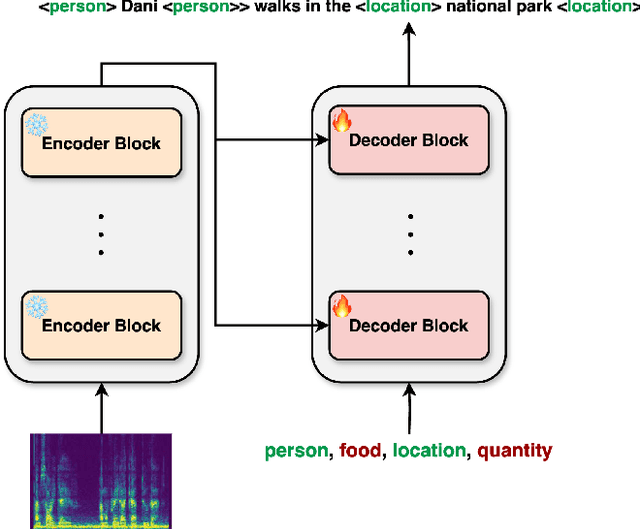
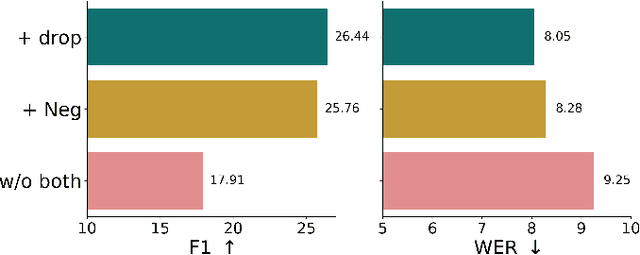
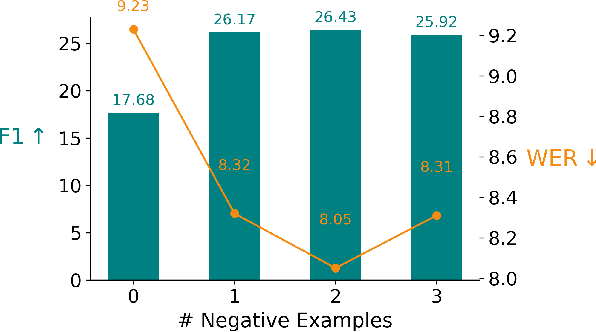

Integrating named entity recognition (NER) with automatic speech recognition (ASR) can significantly enhance transcription accuracy and informativeness. In this paper, we introduce WhisperNER, a novel model that allows joint speech transcription and entity recognition. WhisperNER supports open-type NER, enabling recognition of diverse and evolving entities at inference. Building on recent advancements in open NER research, we augment a large synthetic dataset with synthetic speech samples. This allows us to train WhisperNER on a large number of examples with diverse NER tags. During training, the model is prompted with NER labels and optimized to output the transcribed utterance along with the corresponding tagged entities. To evaluate WhisperNER, we generate synthetic speech for commonly used NER benchmarks and annotate existing ASR datasets with open NER tags. Our experiments demonstrate that WhisperNER outperforms natural baselines on both out-of-domain open type NER and supervised finetuning.
Keyword-Guided Adaptation of Automatic Speech Recognition
Jun 04, 2024



Automatic Speech Recognition (ASR) technology has made significant progress in recent years, providing accurate transcription across various domains. However, some challenges remain, especially in noisy environments and specialized jargon. In this paper, we propose a novel approach for improved jargon word recognition by contextual biasing Whisper-based models. We employ a keyword spotting model that leverages the Whisper encoder representation to dynamically generate prompts for guiding the decoder during the transcription process. We introduce two approaches to effectively steer the decoder towards these prompts: KG-Whisper, which is aimed at fine-tuning the Whisper decoder, and KG-Whisper-PT, which learns a prompt prefix. Our results show a significant improvement in the recognition accuracy of specified keywords and in reducing the overall word error rates. Specifically, in unseen language generalization, we demonstrate an average WER improvement of 5.1% over Whisper.
Open-vocabulary Keyword-spotting with Adaptive Instance Normalization
Sep 13, 2023



Open vocabulary keyword spotting is a crucial and challenging task in automatic speech recognition (ASR) that focuses on detecting user-defined keywords within a spoken utterance. Keyword spotting methods commonly map the audio utterance and keyword into a joint embedding space to obtain some affinity score. In this work, we propose AdaKWS, a novel method for keyword spotting in which a text encoder is trained to output keyword-conditioned normalization parameters. These parameters are used to process the auditory input. We provide an extensive evaluation using challenging and diverse multi-lingual benchmarks and show significant improvements over recent keyword spotting and ASR baselines. Furthermore, we study the effectiveness of our approach on low-resource languages that were unseen during the training. The results demonstrate a substantial performance improvement compared to baseline methods.
A General Spatio-Temporal Clustering-Based Non-local Formulation for Multiscale Modeling of Compartmentalized Reservoirs
Apr 28, 2019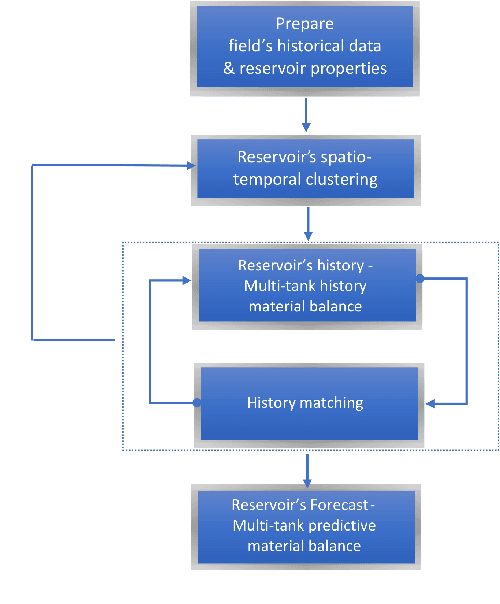
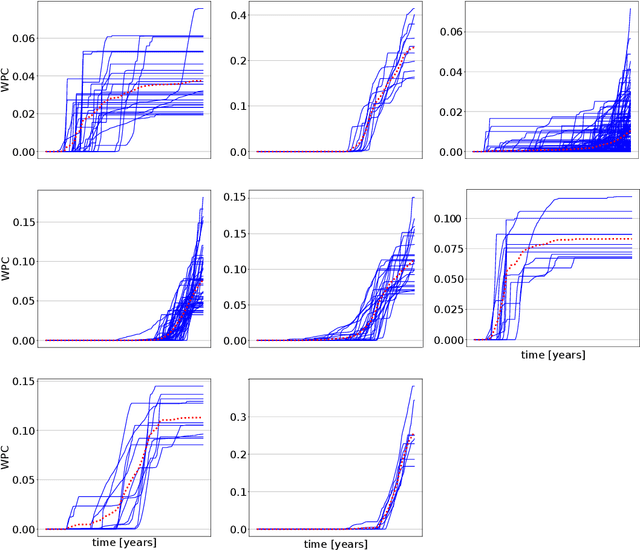
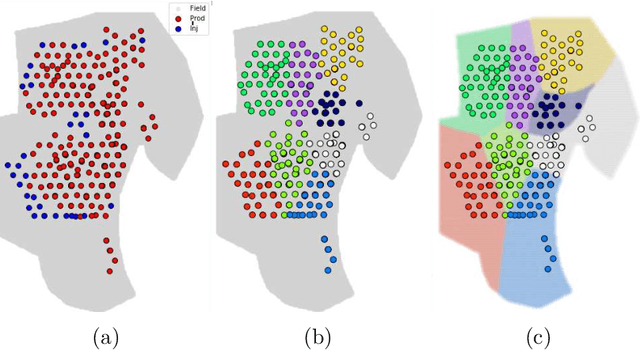
Representing the reservoir as a network of discrete compartments with neighbor and non-neighbor connections is a fast, yet accurate method for analyzing oil and gas reservoirs. Automatic and rapid detection of coarse-scale compartments with distinct static and dynamic properties is an integral part of such high-level reservoir analysis. In this work, we present a hybrid framework specific to reservoir analysis for an automatic detection of clusters in space using spatial and temporal field data, coupled with a physics-based multiscale modeling approach. In this work a novel hybrid approach is presented in which we couple a physics-based non-local modeling framework with data-driven clustering techniques to provide a fast and accurate multiscale modeling of compartmentalized reservoirs. This research also adds to the literature by presenting a comprehensive work on spatio-temporal clustering for reservoir studies applications that well considers the clustering complexities, the intrinsic sparse and noisy nature of the data, and the interpretability of the outcome. Keywords: Artificial Intelligence; Machine Learning; Spatio-Temporal Clustering; Physics-Based Data-Driven Formulation; Multiscale Modeling