 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAbuse and Fraud Detection in Streaming Services Using Heuristic-Aware Machine Learning
Mar 04, 2022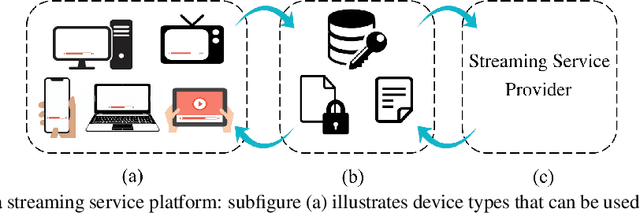

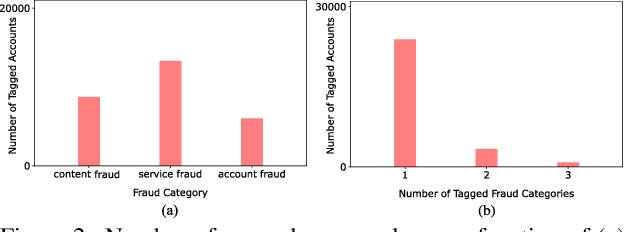

This work presents a fraud and abuse detection framework for streaming services by modeling user streaming behavior. The goal is to discover anomalous and suspicious incidents and scale the investigation efforts by creating models that characterize the user behavior. We study the use of semi-supervised as well as supervised approaches for anomaly detection. In the semi-supervised approach, by leveraging only a set of authenticated anomaly-free data samples, we show the use of one-class classification algorithms as well as autoencoder deep neural networks for anomaly detection. In the supervised anomaly detection task, we present a so-called heuristic-aware data labeling strategy for creating labeled data samples. We carry out binary classification as well as multi-class multi-label classification tasks for not only detecting the anomalous samples but also identifying the underlying anomaly behavior(s) associated with each one. Finally, using a systematic feature importance study we provide insights into the underlying set of features that characterize different streaming fraud categories. To the best of our knowledge, this is the first paper to use machine learning methods for fraud and abuse detection in real-world scale streaming services.
Providing Insights for Open-Response Surveys via End-to-End Context-Aware Clustering
Mar 02, 2022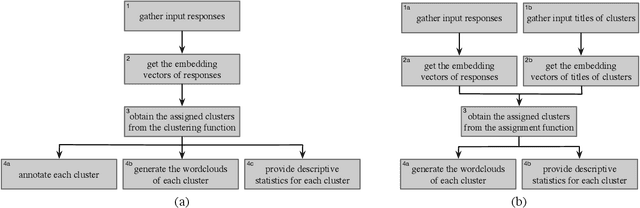


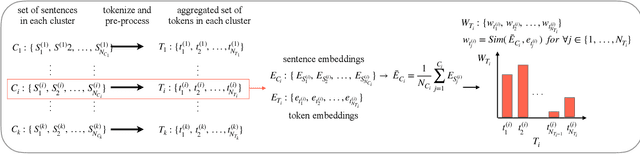
Teachers often conduct surveys in order to collect data from a predefined group of students to gain insights into topics of interest. When analyzing surveys with open-ended textual responses, it is extremely time-consuming, labor-intensive, and difficult to manually process all the responses into an insightful and comprehensive report. In the analysis step, traditionally, the teacher has to read each of the responses and decide on how to group them in order to extract insightful information. Even though it is possible to group the responses only using certain keywords, such an approach would be limited since it not only fails to account for embedded contexts but also cannot detect polysemous words or phrases and semantics that are not expressible in single words. In this work, we present a novel end-to-end context-aware framework that extracts, aggregates, and abbreviates embedded semantic patterns in open-response survey data. Our framework relies on a pre-trained natural language model in order to encode the textual data into semantic vectors. The encoded vectors then get clustered either into an optimally tuned number of groups or into a set of groups with pre-specified titles. In the former case, the clusters are then further analyzed to extract a representative set of keywords or summary sentences that serve as the labels of the clusters. In our framework, for the designated clusters, we finally provide context-aware wordclouds that demonstrate the semantically prominent keywords within each group. Honoring user privacy, we have successfully built the on-device implementation of our framework suitable for real-time analysis on mobile devices and have tested it on a synthetic dataset. Our framework reduces the costs at-scale by automating the process of extracting the most insightful information pieces from survey data.
MeshfreeFlowNet: A Physics-Constrained Deep Continuous Space-Time Super-Resolution Framework
May 01, 2020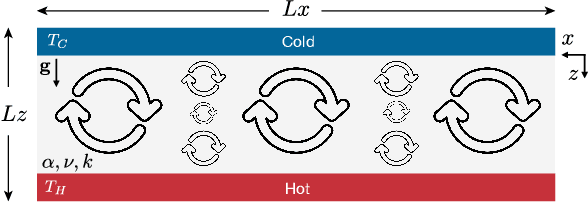
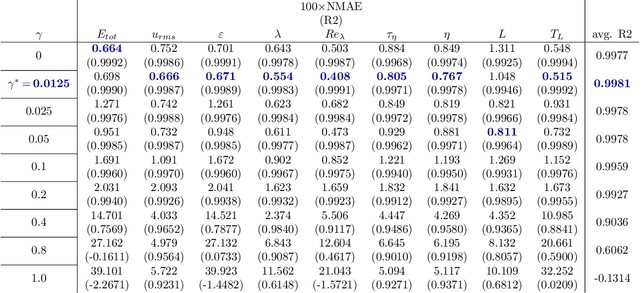
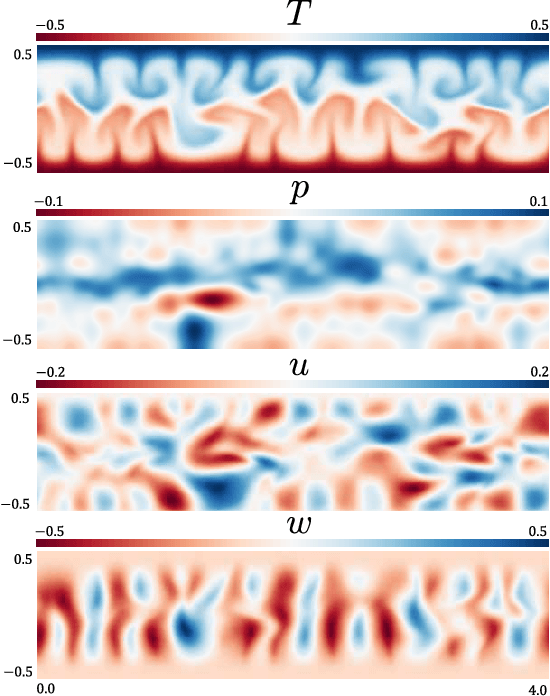
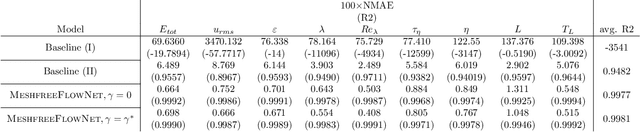
We propose MeshfreeFlowNet, a novel deep learning-based super-resolution framework to generate continuous (grid-free) spatio-temporal solutions from the low-resolution inputs. While being computationally efficient, MeshfreeFlowNet accurately recovers the fine-scale quantities of interest. MeshfreeFlowNet allows for: (i) the output to be sampled at all spatio-temporal resolutions, (ii) a set of Partial Differential Equation (PDE) constraints to be imposed, and (iii) training on fixed-size inputs on arbitrarily sized spatio-temporal domains owing to its fully convolutional encoder. We empirically study the performance of MeshfreeFlowNet on the task of super-resolution of turbulent flows in the Rayleigh-Benard convection problem. Across a diverse set of evaluation metrics, we show that MeshfreeFlowNet significantly outperforms existing baselines. Furthermore, we provide a large scale implementation of MeshfreeFlowNet and show that it efficiently scales across large clusters, achieving 96.80% scaling efficiency on up to 128 GPUs and a training time of less than 4 minutes.
A General Spatio-Temporal Clustering-Based Non-local Formulation for Multiscale Modeling of Compartmentalized Reservoirs
Apr 28, 2019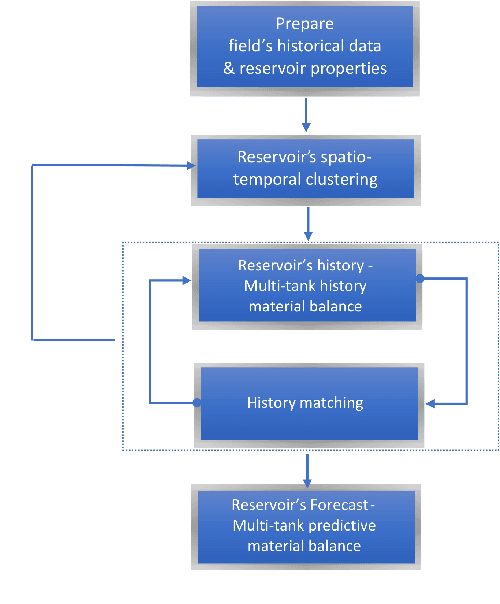
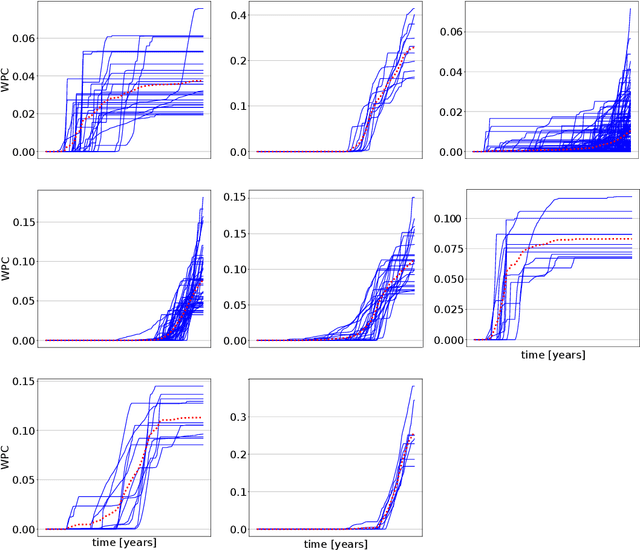
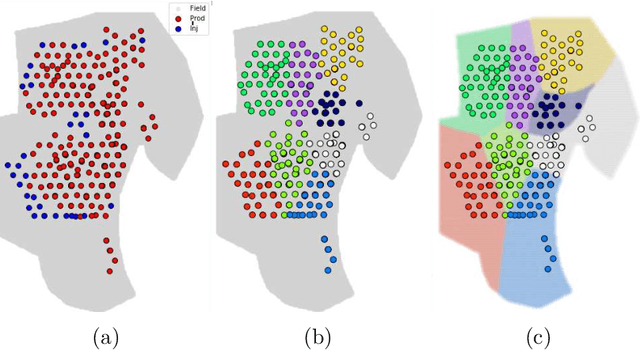
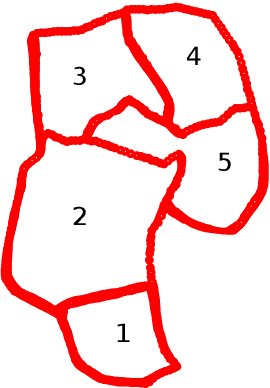
Representing the reservoir as a network of discrete compartments with neighbor and non-neighbor connections is a fast, yet accurate method for analyzing oil and gas reservoirs. Automatic and rapid detection of coarse-scale compartments with distinct static and dynamic properties is an integral part of such high-level reservoir analysis. In this work, we present a hybrid framework specific to reservoir analysis for an automatic detection of clusters in space using spatial and temporal field data, coupled with a physics-based multiscale modeling approach. In this work a novel hybrid approach is presented in which we couple a physics-based non-local modeling framework with data-driven clustering techniques to provide a fast and accurate multiscale modeling of compartmentalized reservoirs. This research also adds to the literature by presenting a comprehensive work on spatio-temporal clustering for reservoir studies applications that well considers the clustering complexities, the intrinsic sparse and noisy nature of the data, and the interpretability of the outcome. Keywords: Artificial Intelligence; Machine Learning; Spatio-Temporal Clustering; Physics-Based Data-Driven Formulation; Multiscale Modeling
Neural Abstractive Text Summarization and Fake News Detection
Mar 24, 2019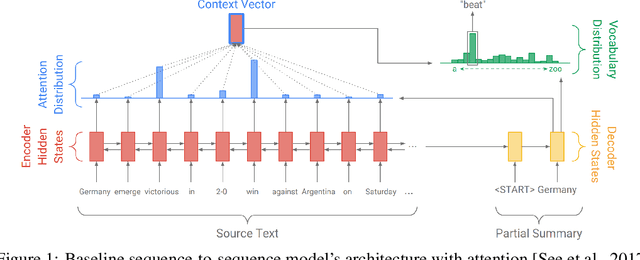
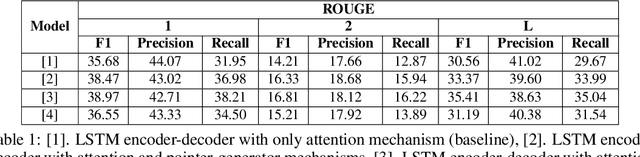
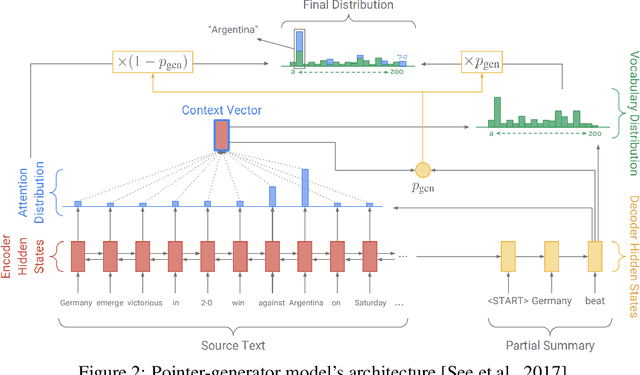

In this work, we study abstractive text summarization by exploring different models such as LSTM-encoder-decoder with attention, pointer-generator networks, coverage mechanisms, and transformers. Upon extensive and careful hyperparameter tuning we compare the proposed architectures against each other for the abstractive text summarization task. Finally, as an extension of our work, we apply our text summarization model as a feature extractor for a fake news detection task where the news articles prior to classification will be summarized and the results are compared against the classification using only the original news text. keywords: abstractive text summarization, pointer-generator, coverage mechanism, transformers, fake news detection
End-To-End Alzheimer's Disease Diagnosis and Biomarker Identification
Oct 01, 2018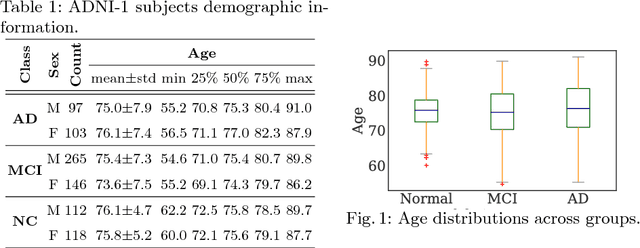
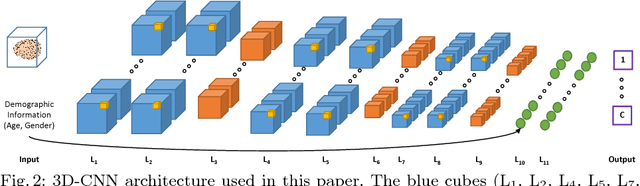
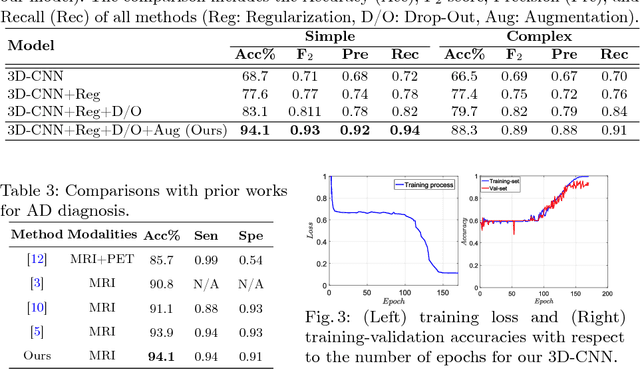
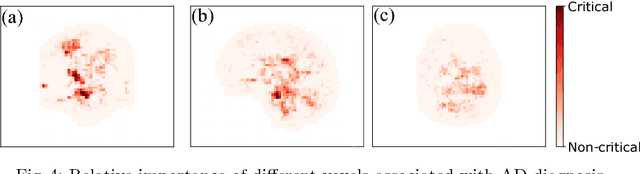
As shown in computer vision, the power of deep learning lies in automatically learning relevant and powerful features for any perdition task, which is made possible through end-to-end architectures. However, deep learning approaches applied for classifying medical images do not adhere to this architecture as they rely on several pre- and post-processing steps. This shortcoming can be explained by the relatively small number of available labeled subjects, the high dimensionality of neuroimaging data, and difficulties in interpreting the results of deep learning methods. In this paper, we propose a simple 3D Convolutional Neural Networks and exploit its model parameters to tailor the end-to-end architecture for the diagnosis of Alzheimer's disease (AD). Our model can diagnose AD with an accuracy of 94.1\% on the popular ADNI dataset using only MRI data, which outperforms the previous state-of-the-art. Based on the learned model, we identify the disease biomarkers, the results of which were in accordance with the literature. We further transfer the learned model to diagnose mild cognitive impairment (MCI), the prodromal stage of AD, which yield better results compared to other methods.
End-to-End Parkinson Disease Diagnosis using Brain MR-Images by 3D-CNN
Jun 13, 2018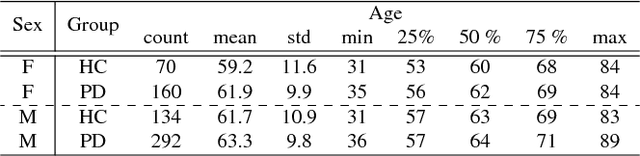
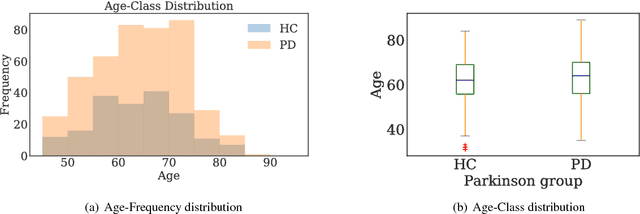
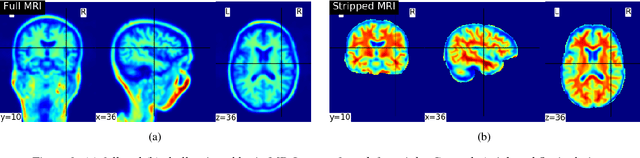
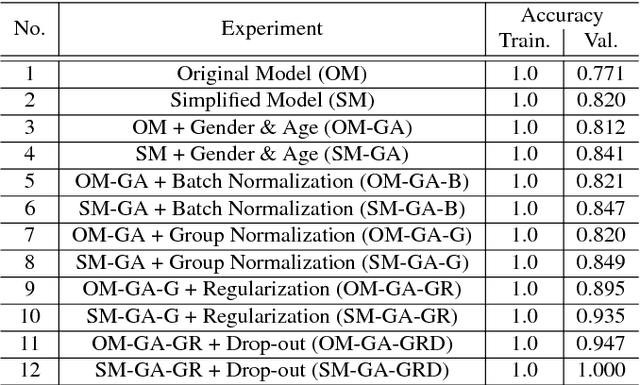
In this work, we use a deep learning framework for simultaneous classification and regression of Parkinson disease diagnosis based on MR-Images and personal information (i.e. age, gender). We intend to facilitate and increase the confidence in Parkinson disease diagnosis through our deep learning framework.
Clinical Parameters Prediction for Gait Disorder Recognition
May 22, 2018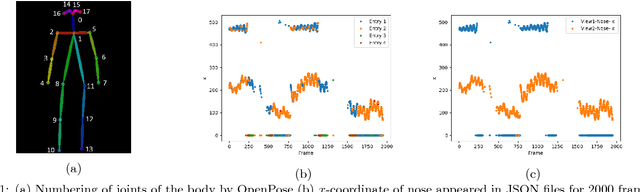
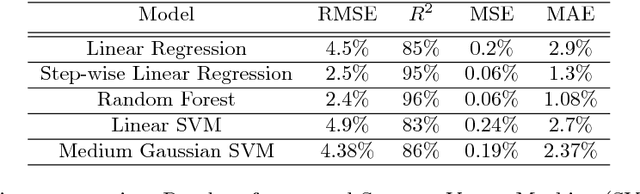
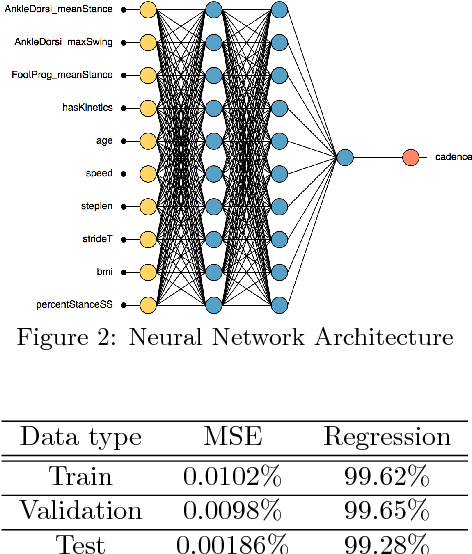
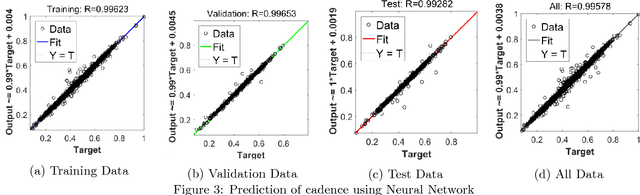
Being able to predict clinical parameters in order to diagnose gait disorders in a patient is of great value in planning treatments. It is known that \textit{decision parameters} such as cadence, step length, and walking speed are critical in the diagnosis of gait disorders in patients. This project aims to predict the decision parameters using two ways and afterwards giving advice on whether a patient needs treatment or not. In one way, we use clinically measured parameters such as Ankle Dorsiflexion, age, walking speed, step length, stride length, weight over height squared (BMI) and etc. to predict the decision parameters. In a second way, we use videos recorded from patient's walking tests in a clinic in order to extract the coordinates of the joints of the patient over time and predict the decision parameters. Finally, having the decision parameters we pre-classify gait disorder intensity of a patient and as the result make decisions on whether a patient needs treatment or not.