 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCinéaste: A Fine-grained Contextual Movie Question Answering Benchmark
Sep 17, 2025While recent advancements in vision-language models have improved video understanding, diagnosing their capacity for deep, narrative comprehension remains a challenge. Existing benchmarks often test short-clip recognition or use template-based questions, leaving a critical gap in evaluating fine-grained reasoning over long-form narrative content. To address these gaps, we introduce $\mathsf{Cin\acute{e}aste}$, a comprehensive benchmark for long-form movie understanding. Our dataset comprises 3,119 multiple-choice question-answer pairs derived from 1,805 scenes across 200 diverse movies, spanning five novel fine-grained contextual reasoning categories. We use GPT-4o to generate diverse, context-rich questions by integrating visual descriptions, captions, scene titles, and summaries, which require deep narrative understanding. To ensure high-quality evaluation, our pipeline incorporates a two-stage filtering process: Context-Independence filtering ensures questions require video context, while Contextual Veracity filtering validates factual consistency against the movie content, mitigating hallucinations. Experiments show that existing MLLMs struggle on $\mathsf{Cin\acute{e}aste}$; our analysis reveals that long-range temporal reasoning is a primary bottleneck, with the top open-source model achieving only 63.15\% accuracy. This underscores significant challenges in fine-grained contextual understanding and the need for advancements in long-form movie comprehension.
CLoVe: Encoding Compositional Language in Contrastive Vision-Language Models
Mar 01, 2024Recent years have witnessed a significant increase in the performance of Vision and Language tasks. Foundational Vision-Language Models (VLMs), such as CLIP, have been leveraged in multiple settings and demonstrated remarkable performance across several tasks. Such models excel at object-centric recognition yet learn text representations that seem invariant to word order, failing to compose known concepts in novel ways. However, no evidence exists that any VLM, including large-scale single-stream models such as GPT-4V, identifies compositions successfully. In this paper, we introduce a framework to significantly improve the ability of existing models to encode compositional language, with over 10% absolute improvement on compositionality benchmarks, while maintaining or improving the performance on standard object-recognition and retrieval benchmarks. Our code and pre-trained models are publicly available at https://github.com/netflix/clove.
Video Annotator: A framework for efficiently building video classifiers using vision-language models and active learning
Feb 09, 2024



High-quality and consistent annotations are fundamental to the successful development of robust machine learning models. Traditional data annotation methods are resource-intensive and inefficient, often leading to a reliance on third-party annotators who are not the domain experts. Hard samples, which are usually the most informative for model training, tend to be difficult to label accurately and consistently without business context. These can arise unpredictably during the annotation process, requiring a variable number of iterations and rounds of feedback, leading to unforeseen expenses and time commitments to guarantee quality. We posit that more direct involvement of domain experts, using a human-in-the-loop system, can resolve many of these practical challenges. We propose a novel framework we call Video Annotator (VA) for annotating, managing, and iterating on video classification datasets. Our approach offers a new paradigm for an end-user-centered model development process, enhancing the efficiency, usability, and effectiveness of video classifiers. Uniquely, VA allows for a continuous annotation process, seamlessly integrating data collection and model training. We leverage the zero-shot capabilities of vision-language foundation models combined with active learning techniques, and demonstrate that VA enables the efficient creation of high-quality models. VA achieves a median 6.8 point improvement in Average Precision relative to the most competitive baseline across a wide-ranging assortment of tasks. We release a dataset with 153k labels across 56 video understanding tasks annotated by three professional video editors using VA, and also release code to replicate our experiments at: http://github.com/netflix/videoannotator.
RAFIC: Retrieval-Augmented Few-shot Image Classification
Dec 11, 2023Few-shot image classification is the task of classifying unseen images to one of N mutually exclusive classes, using only a small number of training examples for each class. The limited availability of these examples (denoted as K) presents a significant challenge to classification accuracy in some cases. To address this, we have developed a method for augmenting the set of K with an addition set of A retrieved images. We call this system Retrieval-Augmented Few-shot Image Classification (RAFIC). Through a series of experiments, we demonstrate that RAFIC markedly improves performance of few-shot image classification across two challenging datasets. RAFIC consists of two main components: (a) a retrieval component which uses CLIP, LAION-5B, and faiss, in order to efficiently retrieve images similar to the supplied images, and (b) retrieval meta-learning, which learns to judiciously utilize the retrieved images. Code and data is available at github.com/amirziai/rafic.
Match Cutting: Finding Cuts with Smooth Visual Transitions
Oct 11, 2022
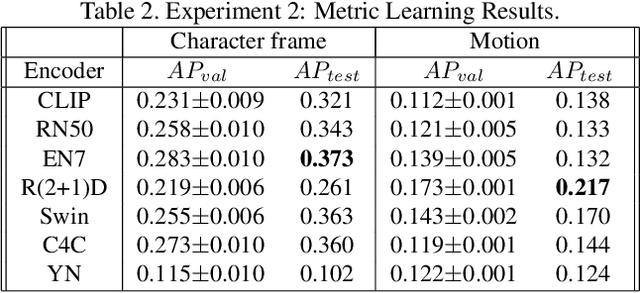

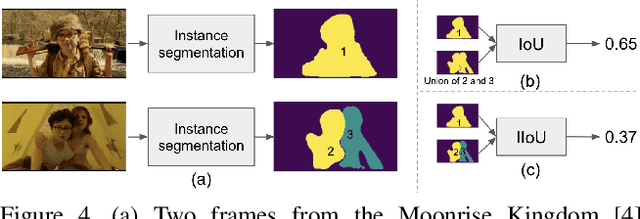
A match cut is a transition between a pair of shots that uses similar framing, composition, or action to fluidly bring the viewer from one scene to the next. Match cuts are frequently used in film, television, and advertising. However, finding shots that work together is a highly manual and time-consuming process that can take days. We propose a modular and flexible system to efficiently find high-quality match cut candidates starting from millions of shot pairs. We annotate and release a dataset of approximately 20k labeled pairs that we use to evaluate our system, using both classification and metric learning approaches that leverage a variety of image, video, audio, and audio-visual feature extractors. In addition, we release code and embeddings for reproducing our experiments at github.com/netflix/matchcut.
Abuse and Fraud Detection in Streaming Services Using Heuristic-Aware Machine Learning
Mar 04, 2022

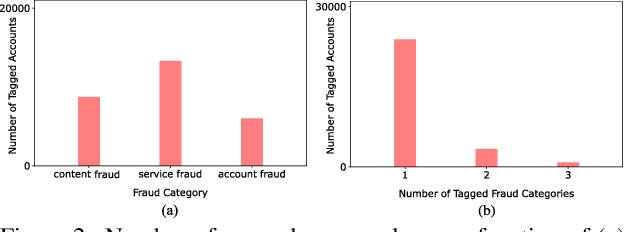

This work presents a fraud and abuse detection framework for streaming services by modeling user streaming behavior. The goal is to discover anomalous and suspicious incidents and scale the investigation efforts by creating models that characterize the user behavior. We study the use of semi-supervised as well as supervised approaches for anomaly detection. In the semi-supervised approach, by leveraging only a set of authenticated anomaly-free data samples, we show the use of one-class classification algorithms as well as autoencoder deep neural networks for anomaly detection. In the supervised anomaly detection task, we present a so-called heuristic-aware data labeling strategy for creating labeled data samples. We carry out binary classification as well as multi-class multi-label classification tasks for not only detecting the anomalous samples but also identifying the underlying anomaly behavior(s) associated with each one. Finally, using a systematic feature importance study we provide insights into the underlying set of features that characterize different streaming fraud categories. To the best of our knowledge, this is the first paper to use machine learning methods for fraud and abuse detection in real-world scale streaming services.
Kinematic & Dynamic Analysis of the Human Upper Limb Using the Theory of Screws
Jun 06, 2019



Screw theory provides geometrical insight into the mechanics of rigid bodies. Screw axis is defined as the line coinciding with the joint axis. Line transformations in the form of a screw operator are used to determine the joint axes of a seven degree of freedom manipulator, representing the human upper limb. Multiplication of a unit screw axis with the joint angular velocity provides the joint twist. Instantaneous motion of a joint is the summation of the twists of the preceding joints and the joint twist itself. Inverse kinematics, velocities and accelerations are calculated using the screw Jacobian for a non-redundant six degree of freedom manipulator. Netwon and Euler dynamic equations are then utilized to solve for the forward and inverse dynamic problems. Dynamics of the upper limb and the upper limb combined with an exoskeleton are only different due to the additional mass and inertia of the exoskeleton. Dynamic equations are crucial for controlling the exoskeleton in position and force.
Detecting Kissing Scenes in a Database of Hollywood Films
Jun 05, 2019



Detecting scene types in a movie can be very useful for application such as video editing, ratings assignment, and personalization. We propose a system for detecting kissing scenes in a movie. This system consists of two components. The first component is a binary classifier that predicts a binary label (i.e. kissing or not) given a features exctracted from both the still frames and audio waves of a one-second segment. The second component aggregates the binary labels for contiguous non-overlapping segments into a set of kissing scenes. We experimented with a variety of 2D and 3D convolutional architectures such as ResNet, DesnseNet, and VGGish and developed a highly accurate kissing detector that achieves a validation F1 score of 0.95 on a diverse database of Hollywood films ranging many genres and spanning multiple decades. The code for this project is available at http://github.com/amirziai/kissing-detector.
Compositional pre-training for neural semantic parsing
May 27, 2019



Semantic parsing is the process of translating natural language utterances into logical forms, which has many important applications such as question answering and instruction following. Sequence-to-sequence models have been very successful across many NLP tasks. However, a lack of task-specific prior knowledge can be detrimental to the performance of these models. Prior work has used frameworks for inducing grammars over the training examples, which capture conditional independence properties that the model can leverage. Inspired by the recent success stories such as BERT we set out to extend this augmentation framework into two stages. The first stage is to pre-train using a corpus of augmented examples in an unsupervised manner. The second stage is to fine-tune to a domain-specific task. In addition, since the pre-training stage is separate from the training on the main task we also expand the universe of possible augmentations without causing catastrophic inference. We also propose a novel data augmentation strategy that interchanges tokens that co-occur in similar contexts to produce new training pairs. We demonstrate that the proposed two-stage framework is beneficial for improving the parsing accuracy in a standard dataset called GeoQuery for the task of generating logical forms from a set of questions about the US geography.
Active Learning for Network Intrusion Detection
Apr 02, 2019



Network operators are generally aware of common attack vectors that they defend against. For most networks the vast majority of traffic is legitimate. However new attack vectors are continually designed and attempted by bad actors which bypass detection and go unnoticed due to low volume. One strategy for finding such activity is to look for anomalous behavior. Investigating anomalous behavior requires significant time and resources. Collecting a large number of labeled examples for training supervised models is both prohibitively expensive and subject to obsoletion as new attacks surface. A purely unsupervised methodology is ideal; however, research has shown that even a very small number of labeled examples can significantly improve the quality of anomaly detection. A methodology that minimizes the number of required labels while maximizing the quality of detection is desirable. False positives in this context result in wasted effort or blockage of legitimate traffic and false negatives translate to undetected attacks. We propose a general active learning framework and experiment with different choices of learners and sampling strategies.