 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLoVe: Encoding Compositional Language in Contrastive Vision-Language Models
Mar 01, 2024Recent years have witnessed a significant increase in the performance of Vision and Language tasks. Foundational Vision-Language Models (VLMs), such as CLIP, have been leveraged in multiple settings and demonstrated remarkable performance across several tasks. Such models excel at object-centric recognition yet learn text representations that seem invariant to word order, failing to compose known concepts in novel ways. However, no evidence exists that any VLM, including large-scale single-stream models such as GPT-4V, identifies compositions successfully. In this paper, we introduce a framework to significantly improve the ability of existing models to encode compositional language, with over 10% absolute improvement on compositionality benchmarks, while maintaining or improving the performance on standard object-recognition and retrieval benchmarks. Our code and pre-trained models are publicly available at https://github.com/netflix/clove.
Simplify-then-Translate: Automatic Preprocessing for Black-Box Machine Translation
May 27, 2020
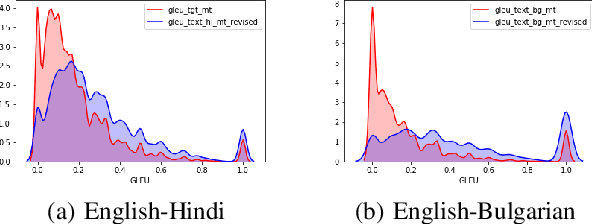

Black-box machine translation systems have proven incredibly useful for a variety of applications yet by design are hard to adapt, tune to a specific domain, or build on top of. In this work, we introduce a method to improve such systems via automatic pre-processing (APP) using sentence simplification. We first propose a method to automatically generate a large in-domain paraphrase corpus through back-translation with a black-box MT system, which is used to train a paraphrase model that "simplifies" the original sentence to be more conducive for translation. The model is used to preprocess source sentences of multiple low-resource language pairs. We show that this preprocessing leads to better translation performance as compared to non-preprocessed source sentences. We further perform side-by-side human evaluation to verify that translations of the simplified sentences are better than the original ones. Finally, we provide some guidance on recommended language pairs for generating the simplification model corpora by investigating the relationship between ease of translation of a language pair (as measured by BLEU) and quality of the resulting simplification model from back-translations of this language pair (as measured by SARI), and tie this into the downstream task of low-resource translation.
Hierarchical Encoders for Modeling and Interpreting Screenplays
Apr 30, 2020

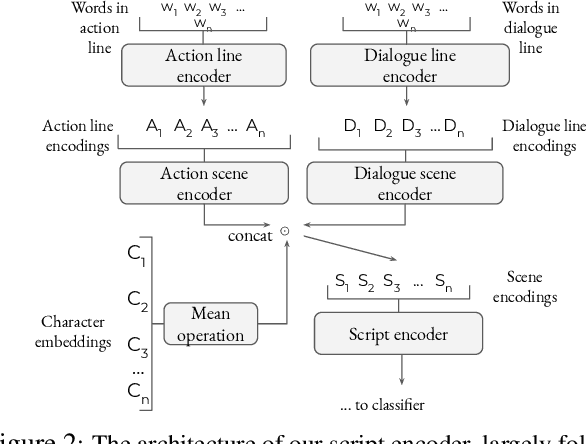
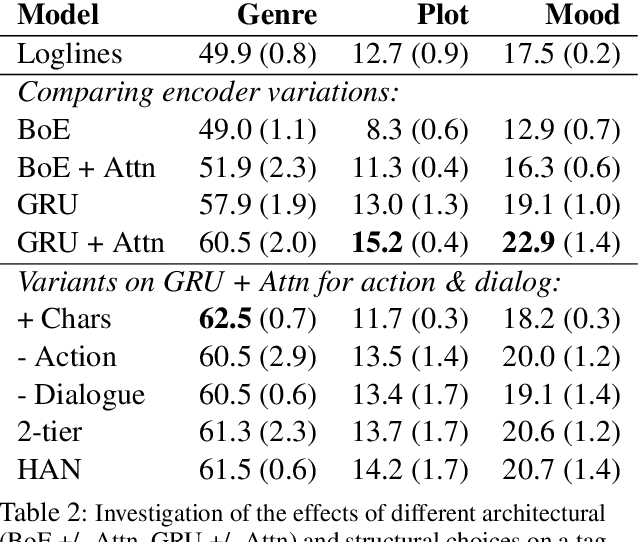
While natural language understanding of long-form documents is still an open challenge, such documents often contain structural information that can inform the design of models for encoding them. Movie scripts are an example of such richly structured text - scripts are segmented into scenes, which are further decomposed into dialogue and descriptive components. In this work, we propose a neural architecture for encoding this structure, which performs robustly on a pair of multi-label tag classification datasets, without the need for handcrafted features. We add a layer of insight by augmenting an unsupervised "interpretability" module to the encoder, allowing for the extraction and visualization of narrative trajectories. Though this work specifically tackles screenplays, we discuss how the underlying approach can be generalized to a range of structured documents.
Using Aspect Extraction Approaches to Generate Review Summaries and User Profiles
Apr 23, 2018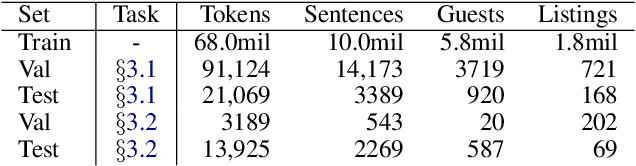
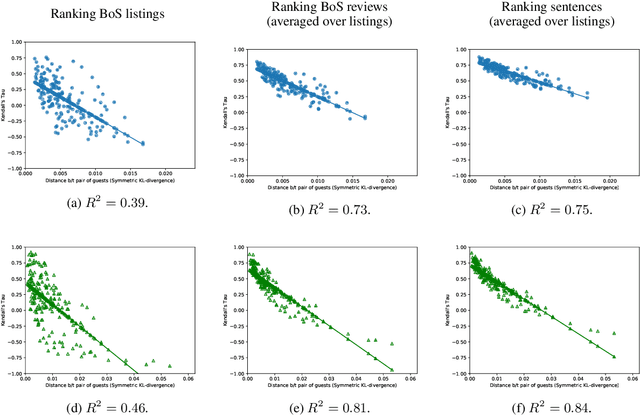


Reviews of products or services on Internet marketplace websites contain a rich amount of information. Users often wish to survey reviews or review snippets from the perspective of a certain aspect, which has resulted in a large body of work on aspect identification and extraction from such corpora. In this work, we evaluate a newly-proposed neural model for aspect extraction on two practical tasks. The first is to extract canonical sentences of various aspects from reviews, and is judged by human evaluators against alternatives. A $k$-means baseline does remarkably well in this setting. The second experiment focuses on the suitability of the recovered aspect distributions to represent users by the reviews they have written. Through a set of review reranking experiments, we find that aspect-based profiles can largely capture notions of user preferences, by showing that divergent users generate markedly different review rankings.
Paraphrase-Supervised Models of Compositionality
Jan 31, 2018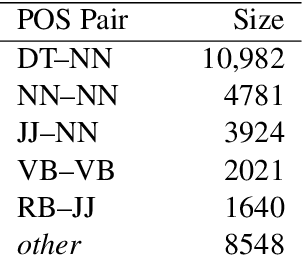


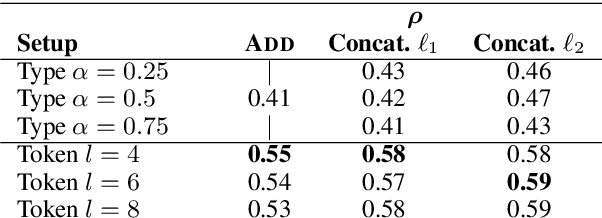
Compositional vector space models of meaning promise new solutions to stubborn language understanding problems. This paper makes two contributions toward this end: (i) it uses automatically-extracted paraphrase examples as a source of supervision for training compositional models, replacing previous work which relied on manual annotations used for the same purpose, and (ii) develops a context-aware model for scoring phrasal compositionality. Experimental results indicate that these multiple sources of information can be used to learn partial semantic supervision that matches previous techniques in intrinsic evaluation tasks. Our approaches are also evaluated for their impact on a machine translation system where we show improvements in translation quality, demonstrating that compositionality in interpretation correlates with compositionality in translation.
Language Modeling with Power Low Rank Ensembles
Oct 03, 2014
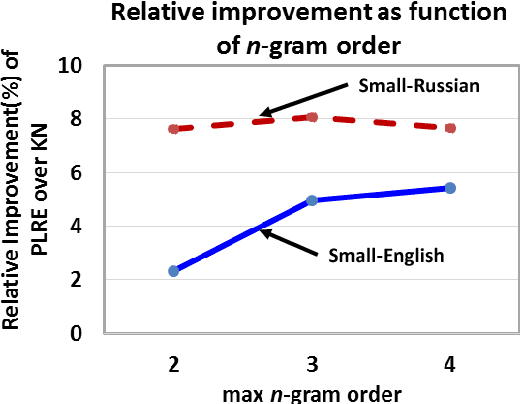
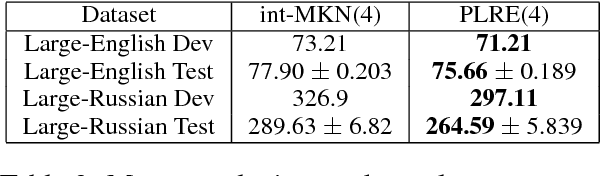

We present power low rank ensembles (PLRE), a flexible framework for n-gram language modeling where ensembles of low rank matrices and tensors are used to obtain smoothed probability estimates of words in context. Our method can be understood as a generalization of n-gram modeling to non-integer n, and includes standard techniques such as absolute discounting and Kneser-Ney smoothing as special cases. PLRE training is efficient and our approach outperforms state-of-the-art modified Kneser Ney baselines in terms of perplexity on large corpora as well as on BLEU score in a downstream machine translation task.
Infinite Mixed Membership Matrix Factorization
Jan 15, 2014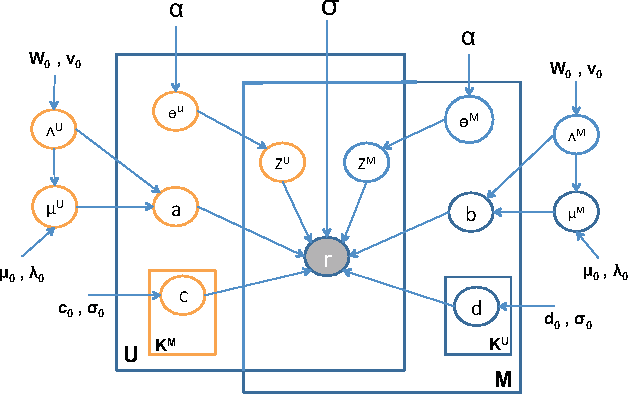
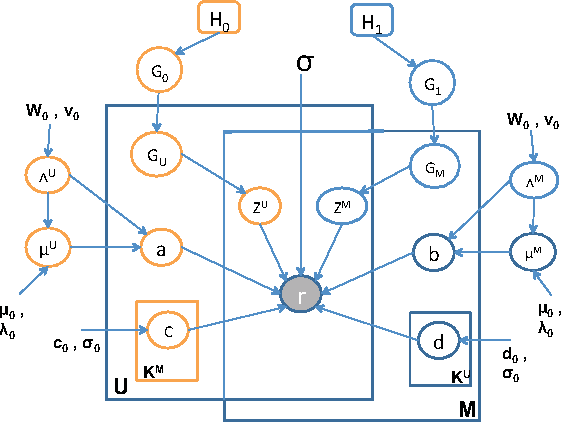
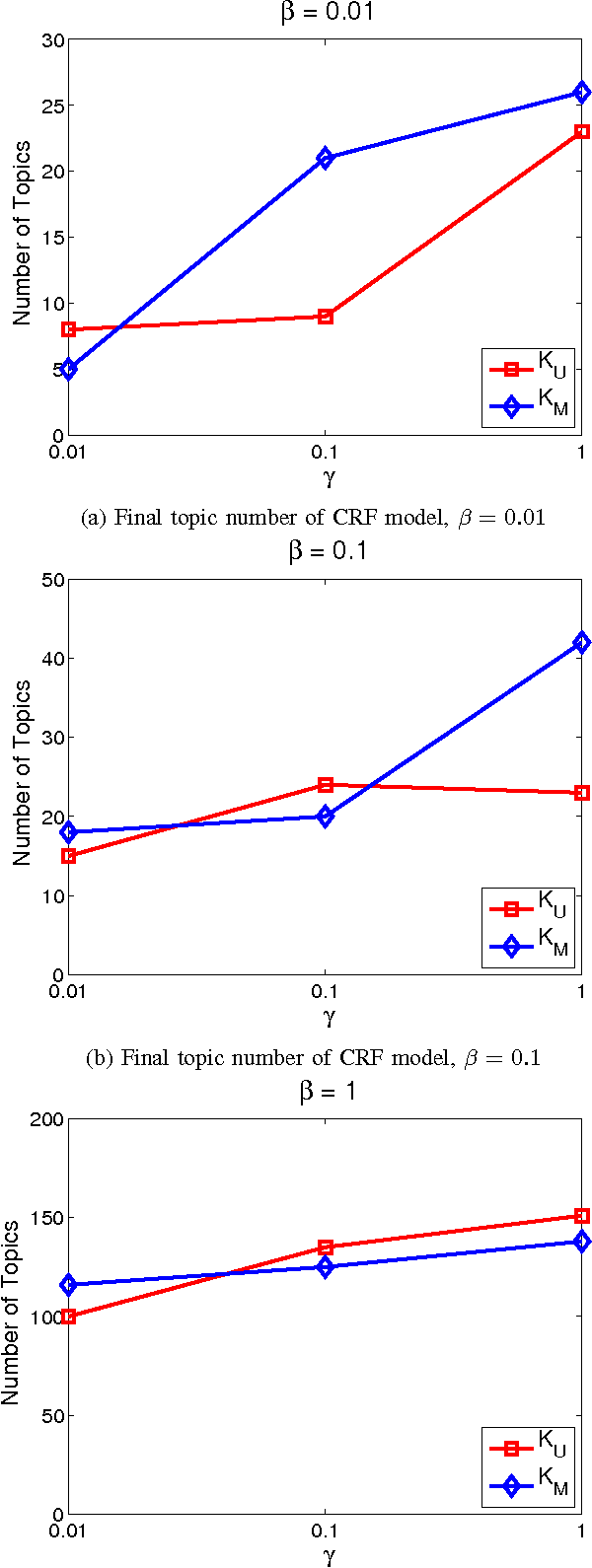
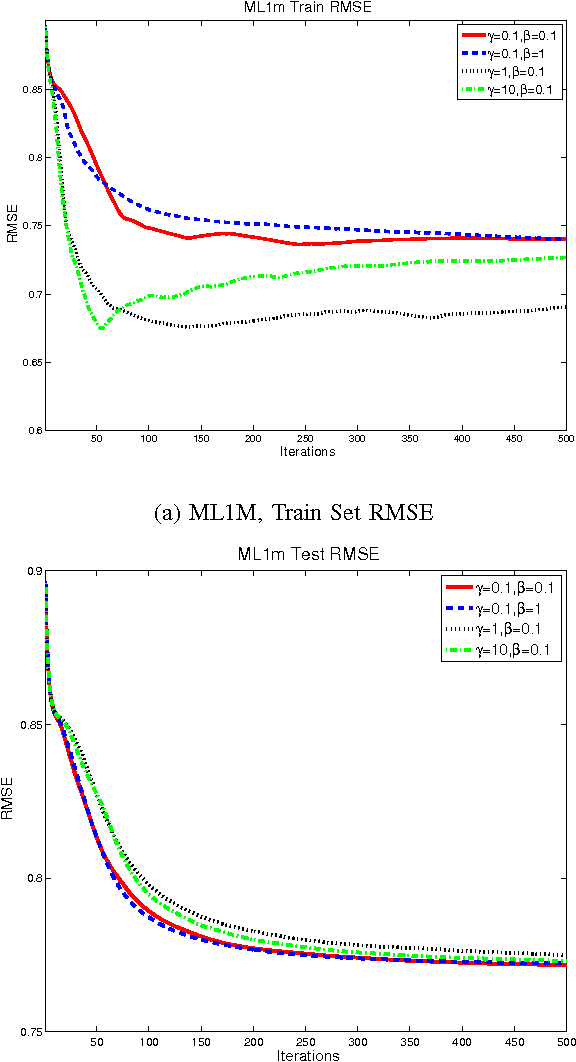
Rating and recommendation systems have become a popular application area for applying a suite of machine learning techniques. Current approaches rely primarily on probabilistic interpretations and extensions of matrix factorization, which factorizes a user-item ratings matrix into latent user and item vectors. Most of these methods fail to model significant variations in item ratings from otherwise similar users, a phenomenon known as the "Napoleon Dynamite" effect. Recent efforts have addressed this problem by adding a contextual bias term to the rating, which captures the mood under which a user rates an item or the context in which an item is rated by a user. In this work, we extend this model in a nonparametric sense by learning the optimal number of moods or contexts from the data, and derive Gibbs sampling inference procedures for our model. We evaluate our approach on the MovieLens 1M dataset, and show significant improvements over the optimal parametric baseline, more than twice the improvements previously encountered for this task. We also extract and evaluate a DBLP dataset, wherein we predict the number of papers co-authored by two authors, and present improvements over the parametric baseline on this alternative domain as well.