 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLoVe: Encoding Compositional Language in Contrastive Vision-Language Models
Mar 01, 2024Recent years have witnessed a significant increase in the performance of Vision and Language tasks. Foundational Vision-Language Models (VLMs), such as CLIP, have been leveraged in multiple settings and demonstrated remarkable performance across several tasks. Such models excel at object-centric recognition yet learn text representations that seem invariant to word order, failing to compose known concepts in novel ways. However, no evidence exists that any VLM, including large-scale single-stream models such as GPT-4V, identifies compositions successfully. In this paper, we introduce a framework to significantly improve the ability of existing models to encode compositional language, with over 10% absolute improvement on compositionality benchmarks, while maintaining or improving the performance on standard object-recognition and retrieval benchmarks. Our code and pre-trained models are publicly available at https://github.com/netflix/clove.
Human Action Co-occurrence in Lifestyle Vlogs using Graph Link Prediction
Sep 22, 2023We introduce the task of automatic human action co-occurrence identification, i.e., determine whether two human actions can co-occur in the same interval of time. We create and make publicly available the ACE (Action Co-occurrencE) dataset, consisting of a large graph of ~12k co-occurring pairs of visual actions and their corresponding video clips. We describe graph link prediction models that leverage visual and textual information to automatically infer if two actions are co-occurring. We show that graphs are particularly well suited to capture relations between human actions, and the learned graph representations are effective for our task and capture novel and relevant information across different data domains. The ACE dataset and the code introduced in this paper are publicly available at https://github.com/MichiganNLP/vlog_action_co-occurrence.
Scalable Performance Analysis for Vision-Language Models
May 31, 2023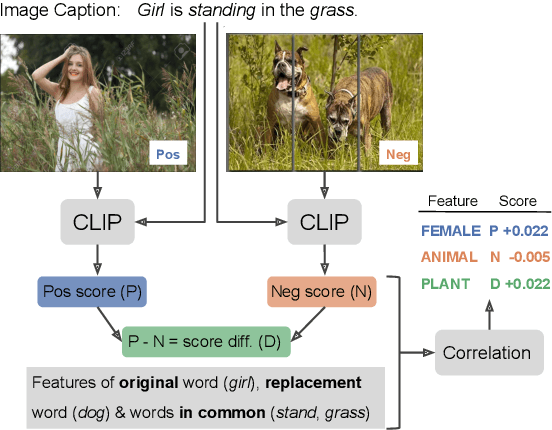
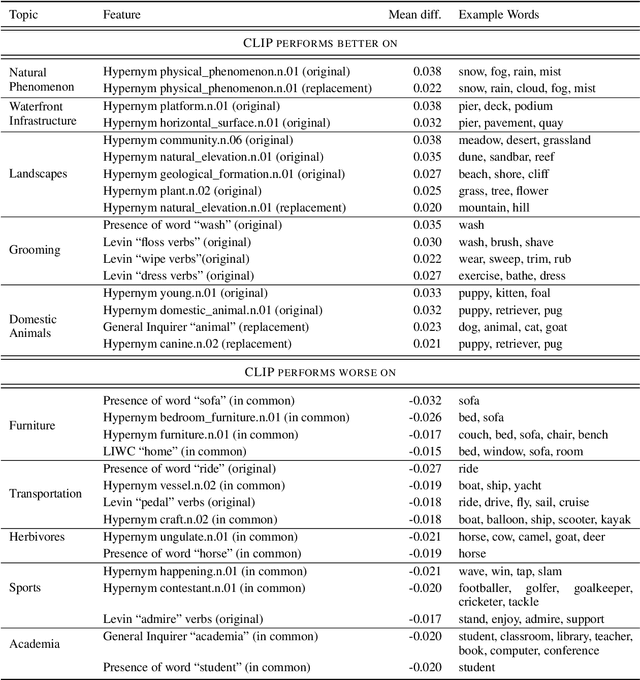
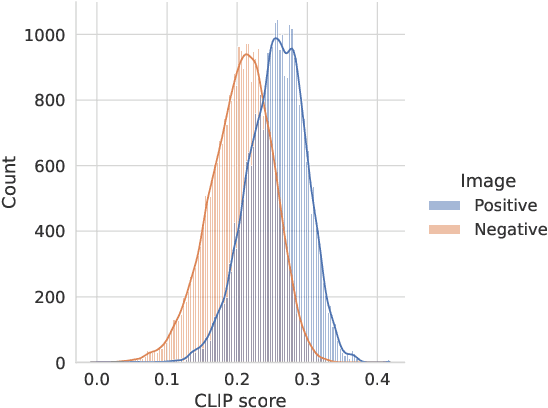
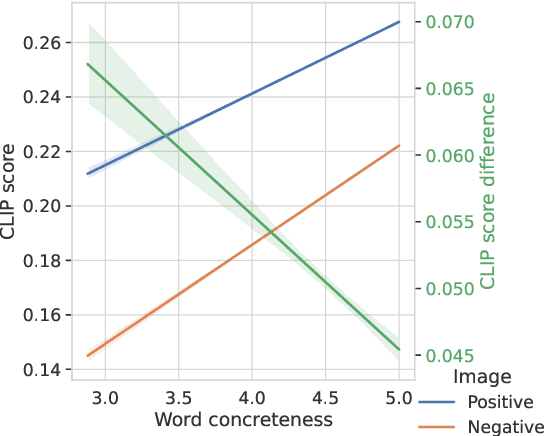
Joint vision-language models have shown great performance over a diverse set of tasks. However, little is known about their limitations, as the high dimensional space learned by these models makes it difficult to identify semantic errors. Recent work has addressed this problem by designing highly controlled probing task benchmarks. Our paper introduces a more scalable solution that relies on already annotated benchmarks. Our method consists of extracting a large set of diverse features from a vision-language benchmark and measuring their correlation with the output of the target model. We confirm previous findings that CLIP behaves like a bag of words model and performs better with nouns and verbs; we also uncover novel insights such as CLIP getting confused by concrete words. Our framework is available at https://github.com/MichiganNLP/Scalable-VLM-Probing and can be used with other multimodal models and benchmarks.
A PhD Student's Perspective on Research in NLP in the Era of Very Large Language Models
May 21, 2023Recent progress in large language models has enabled the deployment of many generative NLP applications. At the same time, it has also led to a misleading public discourse that ``it's all been solved.'' Not surprisingly, this has in turn made many NLP researchers -- especially those at the beginning of their career -- wonder about what NLP research area they should focus on. This document is a compilation of NLP research directions that are rich for exploration, reflecting the views of a diverse group of PhD students in an academic research lab. While we identify many research areas, many others exist; we do not cover those areas that are currently addressed by LLMs but where LLMs lag behind in performance, or those focused on LLM development. We welcome suggestions for other research directions to include: https://bit.ly/nlp-era-llm
Phenaki: Variable Length Video Generation From Open Domain Textual Description
Oct 05, 2022
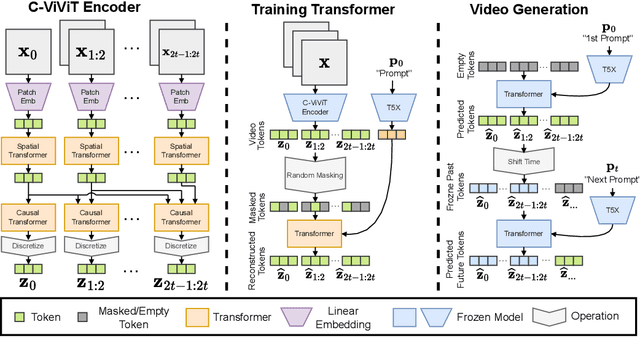


We present Phenaki, a model capable of realistic video synthesis, given a sequence of textual prompts. Generating videos from text is particularly challenging due to the computational cost, limited quantities of high quality text-video data and variable length of videos. To address these issues, we introduce a new model for learning video representation which compresses the video to a small representation of discrete tokens. This tokenizer uses causal attention in time, which allows it to work with variable-length videos. To generate video tokens from text we are using a bidirectional masked transformer conditioned on pre-computed text tokens. The generated video tokens are subsequently de-tokenized to create the actual video. To address data issues, we demonstrate how joint training on a large corpus of image-text pairs as well as a smaller number of video-text examples can result in generalization beyond what is available in the video datasets. Compared to the previous video generation methods, Phenaki can generate arbitrary long videos conditioned on a sequence of prompts (i.e. time variable text or a story) in open domain. To the best of our knowledge, this is the first time a paper studies generating videos from time variable prompts. In addition, compared to the per-frame baselines, the proposed video encoder-decoder computes fewer tokens per video but results in better spatio-temporal consistency.
WildQA: In-the-Wild Video Question Answering
Sep 14, 2022

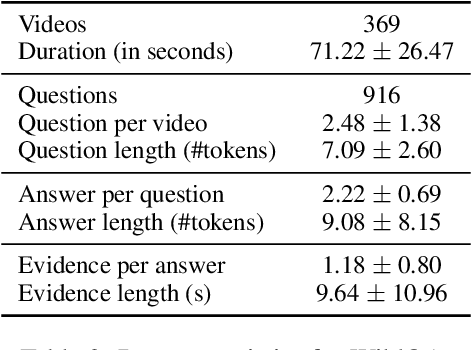
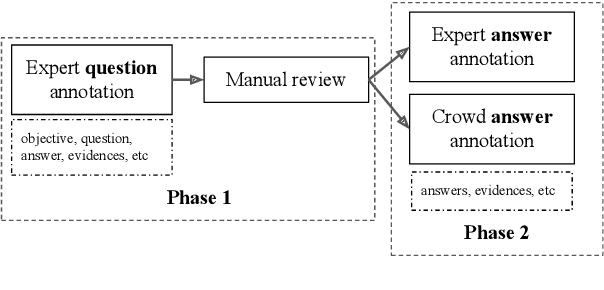
Existing video understanding datasets mostly focus on human interactions, with little attention being paid to the "in the wild" settings, where the videos are recorded outdoors. We propose WILDQA, a video understanding dataset of videos recorded in outside settings. In addition to video question answering (Video QA), we also introduce the new task of identifying visual support for a given question and answer (Video Evidence Selection). Through evaluations using a wide range of baseline models, we show that WILDQA poses new challenges to the vision and language research communities. The dataset is available at https://lit.eecs.umich.edu/wildqa/.
FitCLIP: Refining Large-Scale Pretrained Image-Text Models for Zero-Shot Video Understanding Tasks
Mar 24, 2022



Large-scale pretrained image-text models have shown incredible zero-shot performance in a handful of tasks, including video ones such as action recognition and text-to-video retrieval. However, these models haven't been adapted to video, mainly because they don't account for the time dimension but also because video frames are different from the typical images (e.g., containing motion blur, less sharpness). In this paper, we present a fine-tuning strategy to refine these large-scale pretrained image-text models for zero-shot video understanding tasks. We show that by carefully adapting these models we obtain considerable improvements on two zero-shot Action Recognition tasks and three zero-shot Text-to-video Retrieval tasks. The code is available at https://github.com/bryant1410/fitclip
When Did It Happen? Duration-informed Temporal Localization of Narrated Actions in Vlogs
Feb 21, 2022



We consider the task of temporal human action localization in lifestyle vlogs. We introduce a novel dataset consisting of manual annotations of temporal localization for 13,000 narrated actions in 1,200 video clips. We present an extensive analysis of this data, which allows us to better understand how the language and visual modalities interact throughout the videos. We propose a simple yet effective method to localize the narrated actions based on their expected duration. Through several experiments and analyses, we show that our method brings complementary information with respect to previous methods, and leads to improvements over previous work for the task of temporal action localization.
WhyAct: Identifying Action Reasons in Lifestyle Vlogs
Sep 09, 2021
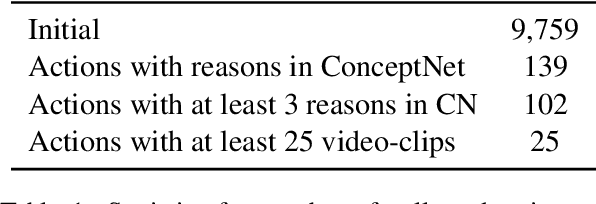

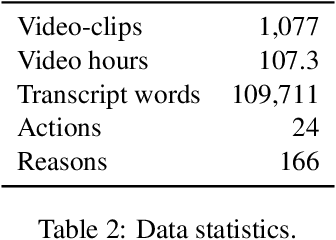
We aim to automatically identify human action reasons in online videos. We focus on the widespread genre of lifestyle vlogs, in which people perform actions while verbally describing them. We introduce and make publicly available the WhyAct dataset, consisting of 1,077 visual actions manually annotated with their reasons. We describe a multimodal model that leverages visual and textual information to automatically infer the reasons corresponding to an action presented in the video.
Fill-in-the-blank as a Challenging Video Understanding Evaluation Framework
Apr 09, 2021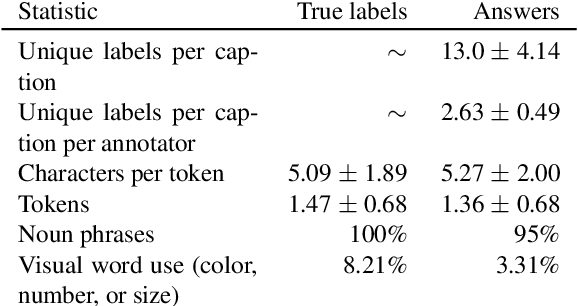
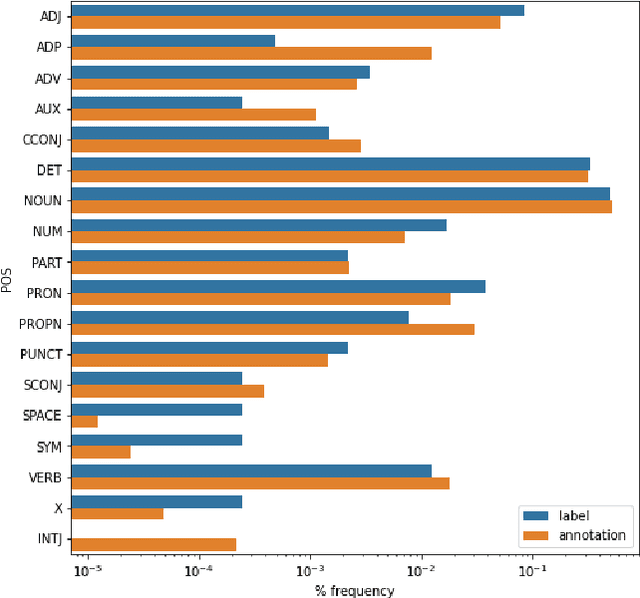
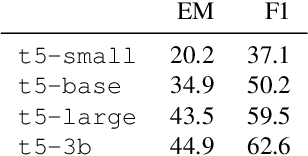
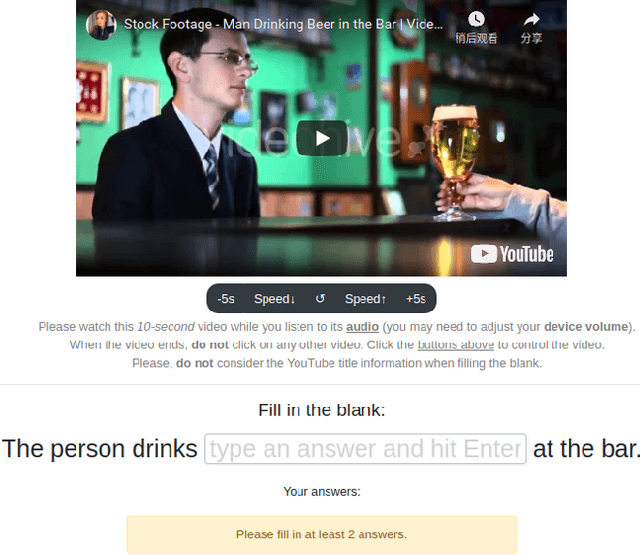
Work to date on language-informed video understanding has primarily addressed two tasks: (1) video question answering using multiple-choice questions, where models perform relatively well because they exploit the fact that candidate answers are readily available; and (2) video captioning, which relies on an open-ended evaluation framework that is often inaccurate because system answers may be perceived as incorrect if they differ in form from the ground truth. In this paper, we propose fill-in-the-blanks as a video understanding evaluation framework that addresses these previous evaluation drawbacks, and more closely reflects real-life settings where no multiple choices are given. The task tests a system understanding of a video by requiring the model to predict a masked noun phrase in the caption of the video, given the video and the surrounding text. We introduce a novel dataset consisting of 28,000 videos and fill-in-the-blank tests. We show that both a multimodal model and a strong language model have a large gap with human performance, thus suggesting that the task is more challenging than current video understanding benchmarks.