 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWildQA: In-the-Wild Video Question Answering
Sep 14, 2022

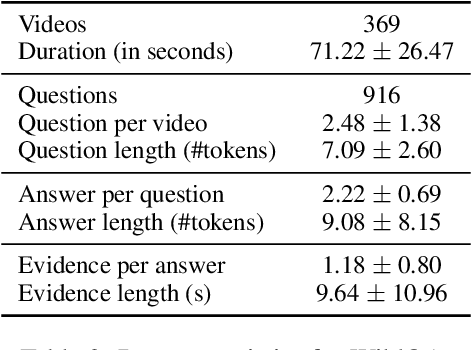
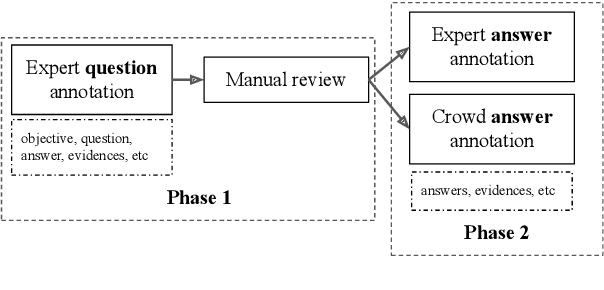
Existing video understanding datasets mostly focus on human interactions, with little attention being paid to the "in the wild" settings, where the videos are recorded outdoors. We propose WILDQA, a video understanding dataset of videos recorded in outside settings. In addition to video question answering (Video QA), we also introduce the new task of identifying visual support for a given question and answer (Video Evidence Selection). Through evaluations using a wide range of baseline models, we show that WILDQA poses new challenges to the vision and language research communities. The dataset is available at https://lit.eecs.umich.edu/wildqa/.
CTP-Net For Cross-Domain Trajectory Prediction
Oct 22, 2021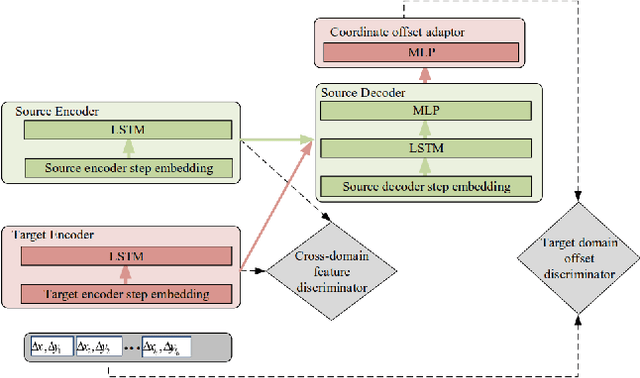


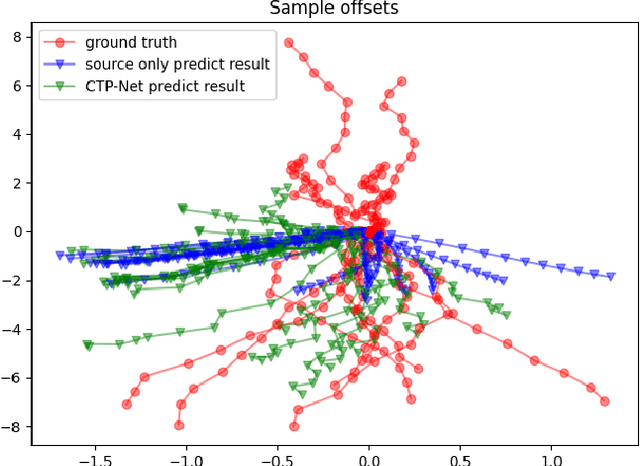
Deep learning based trajectory prediction methods rely on large amount of annotated future trajectories, but may not generalize well to a new scenario captured by another camera. Meanwhile, annotating trajectories for training a network for this new scenario is time-consuming and expensive, therefore it is desirable to adapt the model trained with the annotated source domain trajectories to the target domain. To tackle domain adaptation for trajectory prediction, we propose a Cross-domain Trajectory Prediction Network (CTP-Net), in which LSTMs are used to encode the observed trajectories of both domain, and their features are aligned by a cross-domain feature discriminator. Further, considering the consistency between the observed trajectories and the predicted trajectories in the target domain, a target domain offset discriminator is utilized to adversarially regularize the future trajectory predictions to be consistent with the observed trajectories. Extensive experiments demonstrate the effectiveness of the proposed domain adaptation for trajectory prediction setting as well as our method on domain adaptation for trajectory prediction.
Fill-in-the-blank as a Challenging Video Understanding Evaluation Framework
Apr 09, 2021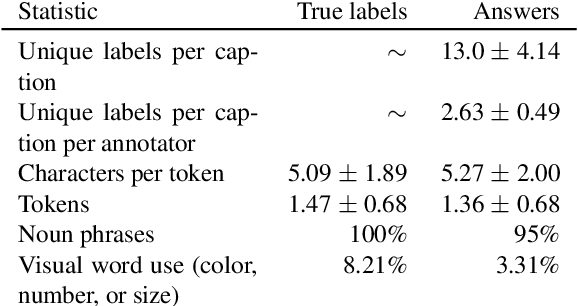
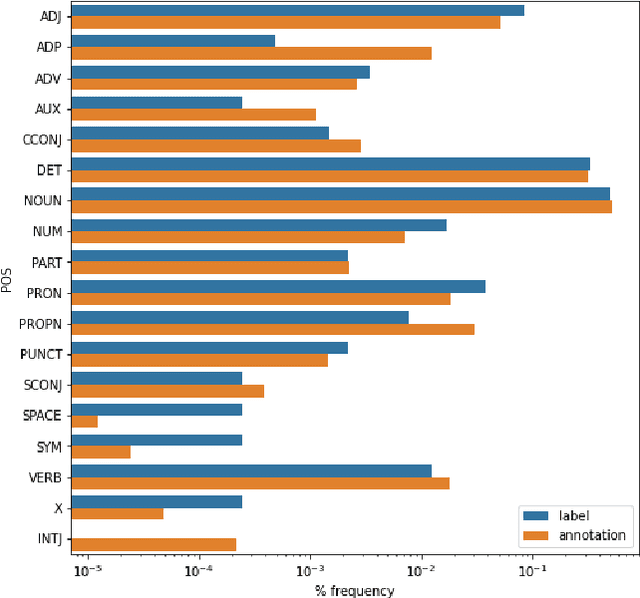
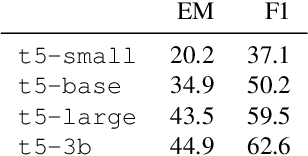
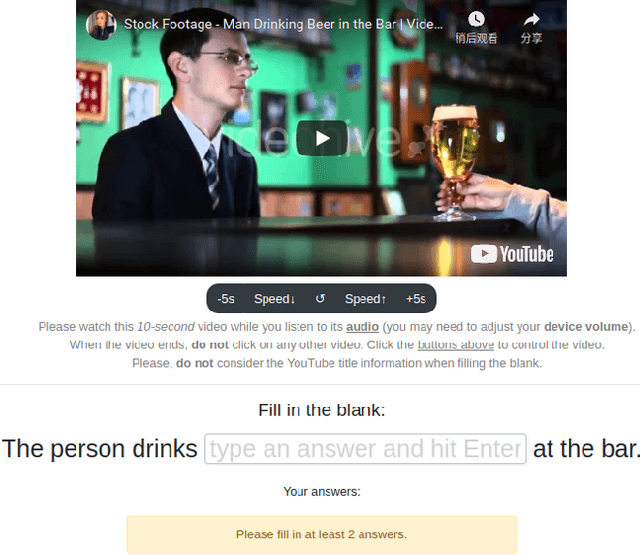
Work to date on language-informed video understanding has primarily addressed two tasks: (1) video question answering using multiple-choice questions, where models perform relatively well because they exploit the fact that candidate answers are readily available; and (2) video captioning, which relies on an open-ended evaluation framework that is often inaccurate because system answers may be perceived as incorrect if they differ in form from the ground truth. In this paper, we propose fill-in-the-blanks as a video understanding evaluation framework that addresses these previous evaluation drawbacks, and more closely reflects real-life settings where no multiple choices are given. The task tests a system understanding of a video by requiring the model to predict a masked noun phrase in the caption of the video, given the video and the surrounding text. We introduce a novel dataset consisting of 28,000 videos and fill-in-the-blank tests. We show that both a multimodal model and a strong language model have a large gap with human performance, thus suggesting that the task is more challenging than current video understanding benchmarks.