Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWildQA: In-the-Wild Video Question Answering
Paper and Code
Sep 14, 2022

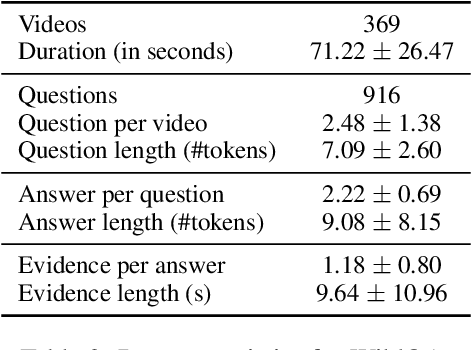
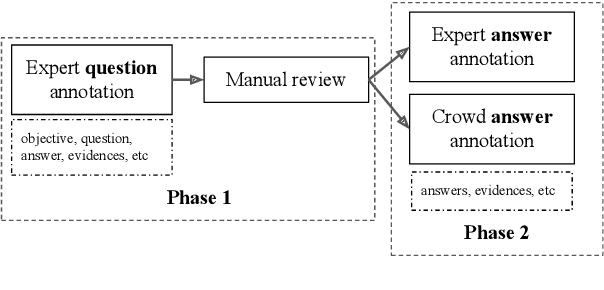
Existing video understanding datasets mostly focus on human interactions, with little attention being paid to the "in the wild" settings, where the videos are recorded outdoors. We propose WILDQA, a video understanding dataset of videos recorded in outside settings. In addition to video question answering (Video QA), we also introduce the new task of identifying visual support for a given question and answer (Video Evidence Selection). Through evaluations using a wide range of baseline models, we show that WILDQA poses new challenges to the vision and language research communities. The dataset is available at https://lit.eecs.umich.edu/wildqa/.
* *: Equal contribution; COLING 2022 oral; project webpage:
https://lit.eecs.umich.edu/wildqa/
View paper on